标签:格式化 containe argument tabs 随机 between key 技术 ons
进制就是进位制,是人们规定的一种进位方法。计算机底层的数据运算和存储都是二进制数据。计算机语言就是二进制,计算机能直接识别二进制数据,其它数据都不能直接识别。
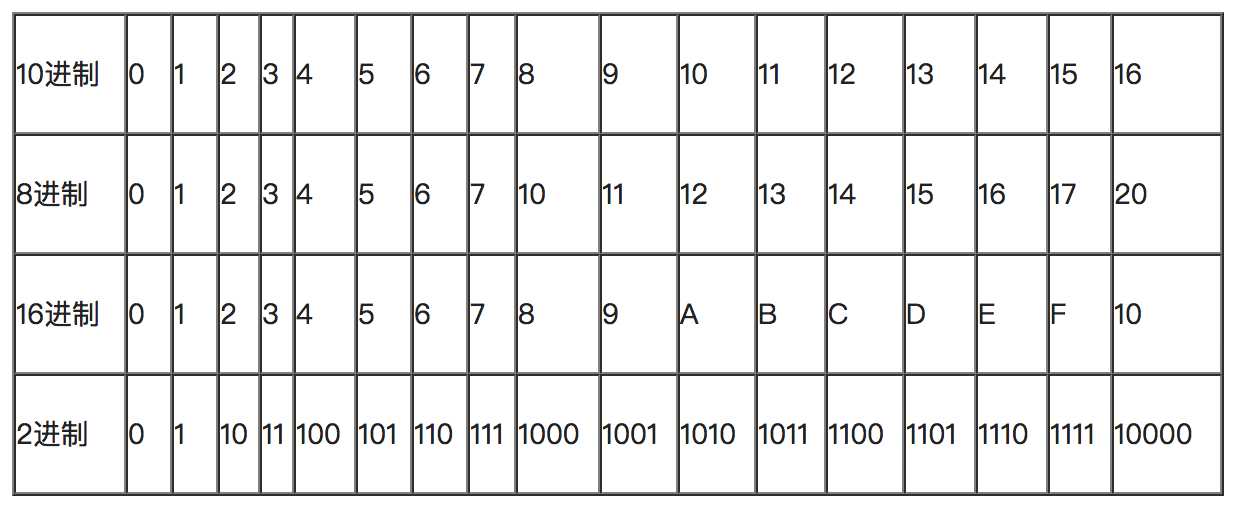
2.常用进制
对于任何一种进制---X进制,就表示某一位置上的数运算时是逢X进一位。 十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,x进制就是逢x进位。我们经常使用的是二进制、八进制、十进制、十六进制。
十六进制:有16个基本数字,分别为0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F,运算规则”逢十六进一”。
我们有最常用的转换方法:用十进制数据除以目标进制得到余数,并将余数从最后一个到第一个排列,就是转换后的目标进制表示形式(简称“除基取余,直到商为0,余数反转”)。以十进制43向二进制转换为例:
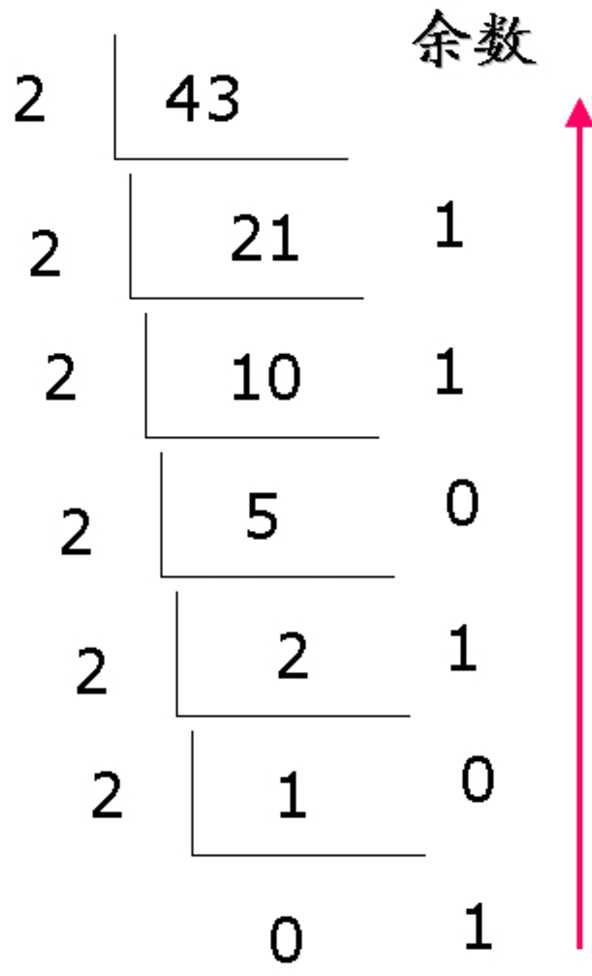
得到的数值排列:101011,所以十进制43的二进制表示形式为101011,同理,如果求八进制、十六进制表示形式,用43除以8、16即可。
类:str
方法:选中str,按住command(ctrl)+左键跳转至对应的方法
字符串常用方法归纳如下:
功能:实现字符串首字母大写,自身不变,会生成一个新的值

1 def capitalize(self): # real signature unknown; restored from __doc__ 2 """ 3 S.capitalize() -> str 4 5 Return a capitalized version of S, i.e. make the first character 6 have upper case and the rest lower case. 7 """ 8 return ""
例子:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 name = ‘hexin‘ 4 v = name.capitalize() #调用str类,执行其中capitalize的方法 5 print(v)
输出:
hexin
Hexin
功能:将所有大写变成小写,另外支持多门语言变化
1 def casefold(self): # real signature unknown; restored from __doc__ 2 """ 3 S.casefold() -> str 4 5 Return a version of S suitable for caseless comparisons. 6 """ 7 return ""
例子:
1 name = ‘HexIn‘ 2 v = name.casefold() 3 print(name) 4 print(v)
输出:
HexIn
hexin
功能:
lower:将所有的大写变小写,局限英文
upper:将所有小写变大写
1 def lower(self): # real signature unknown; restored from __doc__ 2 """ 3 S.lower() -> str 4 5 Return a copy of the string S converted to lowercase. 6 """ 7 return ""
例子:
1 name = ‘HeXin‘ 2 v = name.lower() 3 print(name) 4 print(v)
结果:
HeXin
hexin
功能:文本居中,空白处填充字符
参数1:表示总长度;参数2:空白处填充的字符(长度为1)
1 def center(self, width, fillchar=None): # real signature unknown; restored from __doc__ 2 """ 3 S.center(width[, fillchar]) -> str 4 5 Return S centered in a string of length width. Padding is 6 done using the specified fill character (default is a space) 7 """ 8 return ""
例子:
1 name = ‘HeXin‘ 2 v = name.center(20,‘*‘) 3 print(name) 4 print(v)
输出:
HeXin
*******HeXin********
功能:表示要查找的子序列在字符串中出现的次数
参数1:要查找的值(子序列);参数2:起始位置(索引);参数3:结束位置(索引)
1 def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ 2 """ 3 S.count(sub[, start[, end]]) -> int 4 5 Return the number of non-overlapping occurrences of substring sub in 6 string S[start:end]. Optional arguments start and end are 7 interpreted as in slice notation. 8 """ 9 return 0
例子:
1 name = ‘HeXinddaklfjsl;dfjcnljdajsflajdf‘ 2 v = name.count(‘a‘) 3 i = name.count(‘a‘,0,15) 4 print(name) 5 print(v) 6 print(i)
输出:
3 1
功能:判断是否以xx结尾
参数1:判断值;参数2,3:起始和结束的位置(个数)
1 def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__ 2 """ 3 S.endswith(suffix[, start[, end]]) -> bool 4 5 Return True if S ends with the specified suffix, False otherwise. 6 With optional start, test S beginning at that position. 7 With optional end, stop comparing S at that position. 8 suffix can also be a tuple of strings to try. 9 """ 10 return False
例子:
1 name = ‘HeXinddaklfjsl;dfjcnljdajsflajdf‘ 2 v = name.endswith(‘df‘) 3 i = name.endswith(‘n‘,0,5) 4 print(name) 5 print(v) 6 print(i)
输出:
HeXinddaklfjsl;dfjcnljdajsflajdf
True
True
功能:找到制表符\t,进行替换(包含前面的值)
1 def expandtabs(self, tabsize=8): # real signature unknown; restored from __doc__ 2 """ 3 S.expandtabs(tabsize=8) -> str 4 5 Return a copy of S where all tab characters are expanded using spaces. 6 If tabsize is not given, a tab size of 8 characters is assumed. 7 """ 8 return ""
例子:
1 name = "al\te\tx\nalex\tuu\tkkk" 2 v = name.expandtabs(5) #包含前面的值,5个长度 3 print(v)
输出:
al e x
alex uu kkk
功能:找到指定子序列的索引位置,不存在返回-1
def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.find(sub[, start[, end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0
例子:
1 name = ‘hexin‘ 2 v = name.find(‘0‘) 3 i = name.find(‘x‘) 4 print(v) 5 print(i)
输出:
-1 2
功能:字符串格式化
1 def format(*args, **kwargs): # known special case of str.format 2 """ 3 S.format(*args, **kwargs) -> str 4 5 Return a formatted version of S, using substitutions from args and kwargs. 6 The substitutions are identified by braces (‘{‘ and ‘}‘). 7 """ 8 pass
1 def format_map(self, mapping): # real signature unknown; restored from __doc__ 2 """ 3 S.format_map(mapping) -> str 4 5 Return a formatted version of S, using substitutions from mapping. 6 The substitutions are identified by braces (‘{‘ and ‘}‘). 7 """ 8 return ""
例子:
1 tpl1 = "我是:%s;年龄:%s;性别:%s" %( ‘hexin‘,18,‘man‘) 2 print(tpl1) 3 4 tpl2 = "我是:{0};年龄:{1};性别:{2}" 5 v2 = tpl2.format("李杰",19,‘都行‘) 6 print(v2) 7 8 tpl3 = "我是:{name};年龄:{age};性别:{gender}" 9 v3 = tpl3.format(name=‘李杰‘,age=19,gender=‘随意‘) 10 print(v3) 11 12 tpl4 = "我是:{name};年龄:{age};性别:{gender}" 13 v4 = tpl4.format_map({‘name‘:"李杰",‘age‘:19,‘gender‘:‘中‘}) 14 print(v4)
输出:
我是:hexin;年龄:18;性别:man 我是:李杰;年龄:19;性别:都行 我是:李杰;年龄:19;性别:随意 我是:李杰;年龄:19;性别:中
功能:是否是数字或汉字
1 def isalnum(self): # real signature unknown; restored from __doc__ 2 """ 3 S.isalnum() -> bool 4 5 Return True if all characters in S are alphanumeric 6 and there is at least one character in S, False otherwise. 7 """ 8 return False
例子:
1 name = ‘hexin0好‘ 2 v = name.isalnum() 3 print(v)
输出:
True
功能:是否是数字
1 def isalnum(self): # real signature unknown; restored from __doc__ 2 """ 3 S.isalnum() -> bool 4 5 Return True if all characters in S are alphanumeric 6 and there is at least one character in S, False otherwise. 7 """ 8 return False
1 def isdecimal(self): # real signature unknown; restored from __doc__ 2 """ 3 S.isdecimal() -> bool 4 5 Return True if there are only decimal characters in S, 6 False otherwise. 7 """ 8 return False
1 def isdigit(self): # real signature unknown; restored from __doc__ 2 """ 3 S.isdigit() -> bool 4 5 Return True if all characters in S are digits 6 and there is at least one character in S, False otherwise. 7 """ 8 return False
例子:
1 num = ‘二‘ 2 v1 = num.isdecimal() # ‘123‘ 3 v2 = num.isdigit() # ‘123‘,‘②‘ 4 v3 = num.isnumeric() # ‘123‘,‘二‘,‘②‘ 5 print(v1,v2,v3)
输出:
False False True
功能:是否是有效的标识符
1 def isidentifier(self): # real signature unknown; restored from __doc__ 2 """ 3 S.isidentifier() -> bool 4 5 Return True if S is a valid identifier according 6 to the language definition. 7 8 Use keyword.iskeyword() to test for reserved identifiers 9 such as "def" and "class". 10 """ 11 return False
例子:
1 n = ‘1name‘ 2 u = ‘name‘ 3 v = n.isidentifier() 4 i = u.isidentifier() 5 print(v) 6 print(i)
输出:
False
True
功能:是否全部是小写(大写)
1 def islower(self): # real signature unknown; restored from __doc__ 2 """ 3 S.islower() -> bool 4 5 Return True if all cased characters in S are lowercase and there is 6 at least one cased character in S, False otherwise. 7 """ 8 return False
例子:
1 name = ‘hexin‘ 2 name1 = ‘Hexin‘ 3 v = name.islower() 4 i = name1.islower() 5 print(v) 6 print(i)
输出:
True
False
功能:是否包含隐含的XX(包含\n,\t等不可见字符为False)

1 def isprintable(self): # real signature unknown; restored from __doc__ 2 """ 3 S.isprintable() -> bool 4 5 Return True if all characters in S are considered 6 printable in repr() or S is empty, False otherwise. 7 """ 8 return False
例子:
1 name = ‘hexindas\talj,hexin‘ 2 v = name.isprintable() 3 print(v)
输出:
False
功能:元素拼接
1 def join(self, iterable): # real signature unknown; restored from __doc__ 2 """ 3 S.join(iterable) -> str 4 5 Return a string which is the concatenation of the strings in the 6 iterable. The separator between elements is S. 7 """ 8 return ""
例子:
1 name = ‘hexin‘ 2 3 v = "_".join(name) # 内部循环每个元素 4 print(v) 5 6 name_list = [‘1‘,‘2‘,‘3‘,‘4‘] 7 v = "+".join(name_list) 8 print(v)
输出:
h_e_x_i_n
1+2+3+4
功能:左右填充,类似center
1 def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__ 2 """ 3 S.ljust(width[, fillchar]) -> str 4 5 Return S left-justified in a Unicode string of length width. Padding is 6 done using the specified fill character (default is a space). 7 """ 8 return ""
例子:
1 name = ‘hexin‘ 2 v = name.ljust(14,‘*‘) 3 i = name.rjust(6,‘*‘) 4 print(v) 5 print(i)
输出
hexin********* *hexin
功能:创建对应关系,翻译转换
1 def maketrans(self, *args, **kwargs): # real signature unknown 2 """ 3 Return a translation table usable for str.translate(). 4 5 If there is only one argument, it must be a dictionary mapping Unicode 6 ordinals (integers) or characters to Unicode ordinals, strings or None. 7 Character keys will be then converted to ordinals. 8 If there are two arguments, they must be strings of equal length, and 9 in the resulting dictionary, each character in x will be mapped to the 10 character at the same position in y. If there is a third argument, it 11 must be a string, whose characters will be mapped to None in the result. 12 """ 13 pass
例子:
1 m = str.maketrans(‘aeiou‘,‘12345‘) # 对应关系 2 name = "akpsojfasdufasdlkfj8ausdfakjsdfl;kjer09asdf" 3 v = name.translate(m) 4 print(v)
输出:
1kps4jf1sd5f1sdlkfj815sdf1kjsdfl;kj2r091sdf
功能:分割,保留分割的元素
1 def partition(self, sep): # real signature unknown; restored from __doc__ 2 """ 3 S.partition(sep) -> (head, sep, tail) 4 5 Search for the separator sep in S, and return the part before it, 6 the separator itself, and the part after it. If the separator is not 7 found, return S and two empty strings. 8 """ 9 pass
例子:
1 content = "9SB6SB6" 2 v = content.partition(‘SB‘) # partition 3 print(v)
输出:
(‘9‘, ‘SB‘, ‘6SB6‘)
功能:替换
1 def replace(self, old, new, count=None): # real signature unknown; restored from __doc__ 2 """ 3 S.replace(old, new[, count]) -> str 4 5 Return a copy of S with all occurrences of substring 6 old replaced by new. If the optional argument count is 7 given, only the first count occurrences are replaced. 8 """ 9 return ""
例子:
1 content = "1SB2SB3SB4" 2 v = content.replace(‘SB‘,‘Love‘) 3 print(v) 4 v = content.replace(‘SB‘,‘Love‘,1) 5 print(v)
输出:
1Love2Love3Love4
1Love2SB3SB4
功能:移除空白,\n,\t, 自定义
1 def strip(self, chars=None): # real signature unknown; restored from __doc__ 2 """ 3 S.strip([chars]) -> str 4 5 Return a copy of the string S with leading and trailing 6 whitespace removed. 7 If chars is given and not None, remove characters in chars instead. 8 """ 9 return ""
例子:
1 name = ‘hexin \t‘ 2 v = name.strip() # 空白,\n,\t 3 print(v)
输出:
hexin
功能:填充0
1 def zfill(self, width): # real signature unknown; restored from __doc__ 2 """ 3 S.zfill(width) -> str 4 5 Pad a numeric string S with zeros on the left, to fill a field 6 of the specified width. The string S is never truncated. 7 """ 8 return ""
例子:
1 name = ‘hexin‘ 2 v = name.zfill(20) 3 print(v)
输出:
000000000000000hexin
类int
功能:当前整数的二进制表示的最少位数
def bit_length(self): # real signature unknown; restored from __doc__ """ int.bit_length() -> int Number of bits necessary to represent self in binary. >>> bin(37) ‘0b100101‘ >>> (37).bit_length() 6 """ return 0
例子:
age = 4 # 100 print(age.bit_length())
输出:
3
功能:获取当前数据的字节表示
def to_bytes(self, length, byteorder, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__ """ int.to_bytes(length, byteorder, *, signed=False) -> bytes Return an array of bytes representing an integer. The integer is represented using length bytes. An OverflowError is raised if the integer is not representable with the given number of bytes. The byteorder argument determines the byte order used to represent the integer. If byteorder is ‘big‘, the most significant byte is at the beginning of the byte array. If byteorder is ‘little‘, the most significant byte is at the end of the byte array. To request the native byte order of the host system, use `sys.byteorder‘ as the byte order value. The signed keyword-only argument determines whether two‘s complement is used to represent the integer. If signed is False and a negative integer is given, an OverflowError is raised. """ pass
例子:
age = 15 v = age.to_bytes(10,byteorder=‘big‘) v = age.to_bytes(10,byteorder=‘little‘) print(v)
输出:
b‘\x0f\x00\x00\x00\x00\x00\x00\x00\x00\x00‘
类list
可变类型
功能:追加
def append(self, p_object): # real signature unknown; restored from __doc__ """ L.append(object) -> None -- append object to end """ pass
例子:
user_list = [‘tom‘,‘刘‘,‘jack‘,‘n‘] # 可变类型 user_list.append(‘hex‘) print(user_list)
输出
[‘tom‘, ‘刘‘, ‘jack‘, ‘n‘, ‘hex‘]
功能:清空
例子:
user_list = [‘tom‘,‘刘‘,‘jack‘,‘n‘] # 可变类型 user_list.clear() print(user_list)
输出:
[]
功能:浅拷贝
例子:
user_list = [‘tom‘,‘刘‘,‘jack‘,‘n‘] t = user_list.copy() print(user_list) print(t)
输出:
[‘tom‘, ‘刘‘, ‘jack‘, ‘n‘] [‘tom‘, ‘刘‘, ‘jack‘, ‘n‘]
功能:计数
例子:
user_list = [‘tom‘,‘n‘,‘刘‘,‘jack‘,‘n‘,‘n‘] t = user_list.count(‘n‘) print(user_list) print(t)
输出:
[‘tom‘, ‘n‘, ‘刘‘, ‘jack‘, ‘n‘, ‘n‘] 3
功能:扩展原列表
例子:
user_list = [‘tom‘,‘n‘,‘刘‘,‘jack‘,‘n‘,‘n‘] user_list.extend(‘9‘) print(user_list)
输出:
[‘tom‘, ‘n‘, ‘刘‘, ‘jack‘, ‘n‘, ‘n‘, ‘9‘]
功能:查找元素索引,没有报错
例子:
user_list = [‘tom‘,‘n‘,‘刘‘,‘jack‘,‘n‘,‘n‘] v = user_list.index(‘n‘) print(v)
输出:
1
功能:删除并获取元素,索引
例子:
user_list = [‘tom‘,‘n‘,‘刘‘,‘jack‘,‘n‘,‘n‘] v = user_list.pop(1) print(v) print(user_list)
输出:
n [‘tom‘, ‘刘‘, ‘jack‘, ‘n‘, ‘n‘]
功能:删除,值
例子:
user_list = [‘tom‘,‘n‘,‘刘‘,‘jack‘,‘n‘,‘n‘] user_list.remove(‘n‘) print(user_list)
输出:
[‘tom‘, ‘刘‘, ‘jack‘, ‘n‘, ‘n‘]
功能:翻转
例子:
user_list = [‘tom‘,‘n‘,‘刘‘,‘jack‘,‘n‘,‘n‘] user_list.reverse() print(user_list)
输出:
[‘n‘, ‘n‘, ‘jack‘, ‘刘‘, ‘n‘, ‘tom‘]
功能:排序
例子:
num = [11,2,3,6,111] num.sort() print(num) num.sort(reverse=True) print(num)
输出:
[2, 3, 6, 11, 111]
[111, 11, 6, 3, 2]
py2.7:立即生成数字
range(1,11) # 生成 1,23,,4,56.10
py3:不会立即生成,只有循环迭代,才一个个生成;
for i in range(1,11): print(i) for j in range(1,11,2): print(j) for k in range(10,0,-1): print(k)
1 2 3 4 5 6 7 8 9 10 1 3 5 7 9 10 9 8 7 6 5 4 3 2 1
例子
# li = [‘eric‘,‘alex‘,‘tony‘]
# for i in range(0,len(li)):
# ele = li[i]
# print(ele)
li = [‘eric‘,‘alex‘,‘tony‘]
for i in li:
print(i)
# for i in range(0,len(li)):
# print(i+1,li[i])
输出
eric
alex
tony
功能:额外生成一列有序的数字
例子
li = [‘eric‘,‘alex‘,‘tony‘] for i,ele in enumerate(li,1): print(i,ele) #1 eric #2 alex #3 tony
li = [‘eric‘,‘alex‘,‘tony‘] for i,ele in enumerate(li,1): print(i,ele) v = input(‘请输入商品序号:‘) v = int(v) item = li[v-1] print(item) #1 eric #2 alex #3 tony #请输入商品序号:1 #eric
不可被修改类型,儿子不可被修改,孙子可以
user_tuple = (‘hex‘,‘eric‘,‘seven‘,‘hex‘)
功能:获取个数
user_tuple = (‘hex‘,‘eric‘,‘seven‘,‘hex‘) v = user_tuple.count(‘hex‘) print(v)
#2
功能:获取值得第一个索引位置
user_tuple = (‘hex‘,‘eric‘,‘seven‘,‘hex‘) v = user_tuple.index(‘hex‘) print(v) #0
例子
li = (‘hx‘,) print(li)
user_tuple = (‘alex‘,‘eric‘,‘seven‘,[‘1‘,‘2‘,‘3‘],‘a4‘)
# user_tuple[0] = 123 执行错误
# user_tuple[3] = [11,22,33] 执行错误
user_tuple[3][1] = ‘0‘
print(user_tuple)
可变类型
功能:清空
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
dic.clear()
print(dic)
功能:浅拷贝
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
v = dic.copy()
print(v)
功能:根据key获取指定value,不存在不报错
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
v = dic.get(‘k1111‘,1111)
print(v)
功能:删除并获取对应的value值
# dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘} # v = dic.pop(‘k1‘) # print(dic) # print(v)
输出:
{‘k2‘: ‘v2‘}
v1
功能:随机删除键值对,并获取到删除的键值
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
v = dic.popitem()
print(dic)
print(v)
输出:
{‘k1‘: ‘v1‘}
(‘k2‘, ‘v2‘)
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
k,v = dic.popitem() # (‘k2‘, ‘v2‘)
print(dic)
print(k,v)
输出:
{‘k2‘: ‘v2‘}
k1 v1
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
v = dic.popitem() # (‘k2‘, ‘v2‘)
print(dic)
print(v[0],v[1])
输出:
{‘k1‘: ‘v1‘}
k2 v2
功能:增加,如果不存在即删除
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
dic.setdefault(‘k3‘,‘v3‘)
print(dic)
dic.setdefault(‘k1‘,‘1111111‘)
print(dic)
输出:
{‘k2‘: ‘v2‘, ‘k1‘: ‘v1‘, ‘k3‘: ‘v3‘}
{‘k2‘: ‘v2‘, ‘k1‘: ‘v1‘, ‘k3‘: ‘v3‘}
功能:批量增加或修改
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘}
dic.update({‘k3‘:‘v3‘,‘k1‘:‘v24‘})
print(dic)
输出:
{‘k1‘: ‘v24‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘}
功能:从序列键和值设置为value来创建一个新的字典。
例子:
dic = dict.fromkeys([‘k1‘,‘k2‘,‘k3‘],123) dic[‘k1‘] = ‘asdfjasldkf‘ print(dic)
输出:
{‘k2‘: 123, ‘k1‘: ‘asdfjasldkf‘, ‘k3‘: 123}
集合,不可重复列表,可变类型。
s1 = {"alex",‘eric‘,‘tony‘}
print(type(s1))
print(s1)
输出:
<class ‘set‘> {‘alex‘, ‘eric‘, ‘tony‘}
功能:输出s1中存在,s2中不存在的值
s1 = {"alex",‘eric‘,‘tony‘,‘ii‘}
s2 = {"alex",‘eric‘,‘tony‘,‘hexin‘}
v = s1.difference(s2)
print(v)
输出:
{‘ii‘}
功能:s1中存在,s2中不存在,然后对s1清空,然后在重新赋值
s1 = {"alex",‘eric‘,‘tony‘,‘ii‘}
s2 = {"alex",‘eric‘,‘tony‘,‘hexin‘}
s1.difference_update(s2)
print(s1)
输出:
{‘ii‘}
功能:s1中存在,s2中不存在的值及s2中存在,s1中不存在的值
s1 = {"alex",‘eric‘,‘tony‘,‘ii‘}
s2 = {"alex",‘eric‘,‘tony‘,‘hexin‘}
v = s1.symmetric_difference(s2)
print(v)
{‘ii‘, ‘hexin‘}
功能:交集
s1 = {"alex",‘eric‘,‘tony‘,‘ii‘}
s2 = {"alex",‘eric‘,‘tony‘,‘hexin‘}
v = s1.intersection(s2)
print(v)
输出:
{‘eric‘, ‘alex‘, ‘tony‘}
功能:并集
s1 = {"alex",‘eric‘,‘tony‘,‘ii‘}
s2 = {"alex",‘eric‘,‘tony‘,‘hexin‘}
v = s1.union(s2)
print(v)
输出:
{‘alex‘, ‘hexin‘, ‘eric‘, ‘ii‘, ‘tony‘}
功能:移除
s1 = {"alex",‘eric‘,‘tony‘,‘ii‘}
s2 = {"alex",‘eric‘,‘tony‘,‘hexin‘}
s1.discard(‘alex‘)
print(s1)
输出:
{‘eric‘, ‘tony‘, ‘ii‘}
功能:添加
s1 = {"alex",‘eric‘,‘tony‘,‘李泉‘,‘李泉11‘}
s1.update({‘alex‘,‘123123‘,‘fff‘})
print(s1)
输出:
{‘fff‘, ‘李泉‘, ‘123123‘, ‘tony‘, ‘alex‘, ‘eric‘, ‘李泉11‘}
标签:格式化 containe argument tabs 随机 between key 技术 ons
原文地址:http://www.cnblogs.com/smallmars/p/6835616.html
