标签:blog http java 使用 io 文件 for 2014 div
4. 转换HTML代码为DOM元素
先创建一个文档片段DocumentFragment,然后调用方法jQuery.clean(elems, context, frag-ment, scripts)将HTML代码转换为DOM元素,并存储在创建的文档片段中。
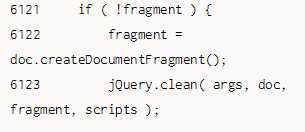

!fragment为true时可能有三种情况: •HTML代码不符合缓存条件。 •HTML代码符合缓存条件,但此时是第一次转换,不存在对应的缓存。 •HTML代码符合缓存条件,但此时是第二次转换,对应的缓存值是1。
5. 把转换后的DOM元素放入缓存对象jQuery.fragments


•如果HTML代码不符合缓存条件,则总是会执行转换过程。 •如果HTML代码符合缓存条件,第一次转换后设置缓存值为1,第二次转换后设置为文档片段,从第三次开始则从缓存中读取。
6. 返回文档片段和缓存状态{fragment: fragment, cacheable: cacheable}
小结

2.5 jQuery.clean(elems, context, fragment, scripts)
2.5.1 实现原理
该方法先创建一个临时的div元素,并将其插入一个安全文档片段中,然后把HTML代码赋值给div元素的innerHTML属性,浏览器会自动生成DOM元素,最后解析div元素的子元素得到转换后的DOM元素
如果HTML代码中含有需要包裹在父标签中的子标签,例如,子标签<option>需要包裹在父标签<select>中,方法jQuery.clean()会先在HTML代码的前后加上父标签和关闭标签,在设置临时div元素的innerHTML属性生成DOM元素后,再层层剥去包裹的父元素,取出HTML代码对应的DOM元素
如果HTML代码中含有<script>标签,为了能执行<script>标签所包含的JavaScript代码或引用的JavaScript文件,在设置临时div元素的inner-HTML属性生成DOM元素后,方法jQuery.clean()会提取其中的script元素放入数组scripts。在生成的DOM元素插入文档树后,数组scripts中的script元素会被逐个手动执行。
2.5.2 源码分析
1. 定义jQuery.clean(elems, context, fragment, scripts)

2. 修正文档对象context
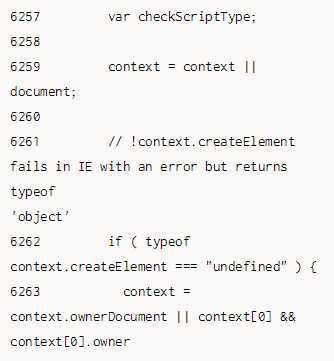
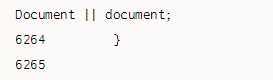
既然方法jQuery.buildFragment()已经谨慎地修正了文档对象doc,并传给了方法jQuery.clean(),那么这里为什么要再次做类似的修正呢?
这是为了方便直接调用jQuery.clean()转换HTML代码为DOM元素。
3. 遍历待转换的HTML代码数组elems


在for语句的第1部分,声明了循环变量elem,在for语句的第2部分取出elems[i]赋值给elem,并判断elem的有效性。另外,判断elem的有效性时使用的是“!=”,这样可以同时过滤null和undefined,却又不会过滤整型数字0,如果elem是数值型,通过让elem自加一个空字符串,把elem转换为字符串。
如果!elem为true,即elem可以转换为false,那么跳过本次循环,执行下一次循环。这行代码用于过滤空字符串的情况。如果elem是整型数字0,因为在前面的代码中已经被转换成了字符串“0”,所以这里可以简单地判断!elem
如果elem是字符串,即HTML代码,则开始转换HTML代码为DOM元素
(1)创建文本节点

用正则rhtml检测HTML代码中是否含有标签、字符代码或数字代码,该正则的定义代码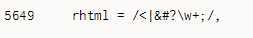
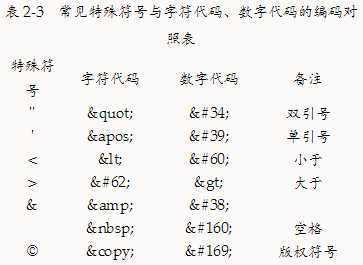

原生方法document.createTextN-ode()用于创建文本节点,但是对于传给它的字符串参数不会做转义解析,也就是说,该方法不能正确地解析和创建包含了字符代码或数字代码的字符串,而浏览器的innerHTML机制则可以
(2)修正自关闭标签

用正则rxhtmlTag匹配HTML代码中的自关闭标签,并通过方法replace()替换为成对的标签
正则rxhtmlTag是修正自关闭标签的关键所在

标签:blog http java 使用 io 文件 for 2014 div
原文地址:http://www.cnblogs.com/sdgjytu/p/3935744.html