标签:alt 友情 doc 学习 drive 华为 http 链接 分析
摘要:
我们知道,Map是 Java Collection Framework 的重要成员,也是我们最常用的容器类之一。Map的实现多种多样,包括HashMap、LinkedHashMap等。但是,无论实际中使用哪种实现,我们在编程过程中常常会遇到诸如根据Key或Value对Map进行排序、保持Map插入顺序等问题,本文特别针对以上几个问题给出了具体解法,并分享华为一道与我们主题极为相关的笔试题。
版权声明:
本文原创作者:书呆子Rico
作者博客地址:http://blog.csdn.net/justloveyou_/
友情提示:
若读者需要本博文相关完整代码,请移步我的Github自行获取,项目名为 JTools,链接地址为:https://github.com/githubofrico/JTools。
我们知道,Map是键值对(Key-Value 对)映射的抽象接口,是 Java Collection Framework 的重要成员,也是我们最常用的容器类之一。Map的实现多种多样,包括HashMap、LinkedHashMap等等。特别地,笔者在博文《Map 综述(一):彻头彻尾理解 HashMap》和《Map 综述(二):彻头彻尾理解 LinkedHashMap》对HashMap和LinkedHashMap进行了深入地介绍。但是,无论实际中使用哪种实现,我们在编程过程中常常会遇到这样些问题:
如何对Map根据Value进行排序并进行输出呢?
如何对Map根据Key进行排序并进行输出呢?
如何使Map保持插入顺序呢?
笔者将在本文着重探讨这些问题的解决方案,并给出华为一道类似的笔试题《简单错误记录》,以飨读者。
书归正传,下面的代码给出了以上三个问题的实现样例,下面我们来进行逐一分析。注意,为了保证算法的实用性和鲁棒性,笔者在实现过程中使用了泛型。对于泛型的概念,一言以蔽之,其实质上就是实现了 类型的参数化。此外,如果读者想更全面、详细的了解Java的泛型机制,请见笔者的巨长博文《Java 泛型(Generics) 综述》。
/**
* Title: Map的增强实现
* Description:
*
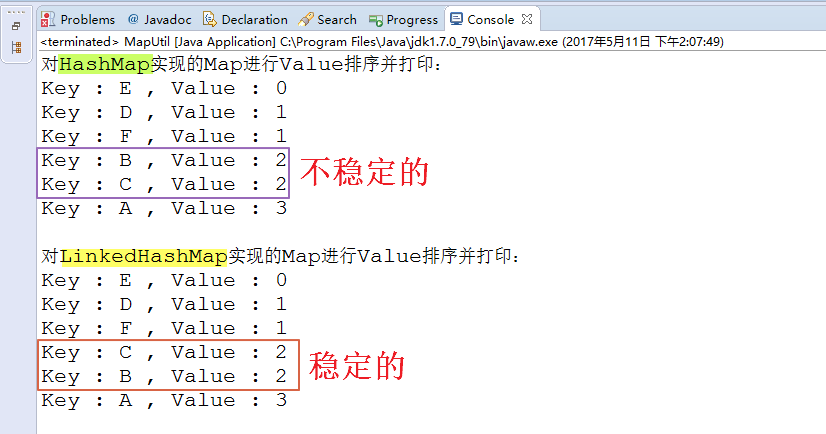
* 1. 根据Value对Map进行排序,并将每条Map.Entry按序输出,这种排序是不稳定的,其取决于Map的具体实现:
* 若使用HashMap实现,由于HashMap是无序的,所以是不稳定的;
* 若使用LinkedHashMap实现,由于LinkedHashMap是保留插入顺序的,所以是稳定的。
* 所谓排序稳定是指,相同两项在排序后仍保持最初的顺序,不会颠倒。
*
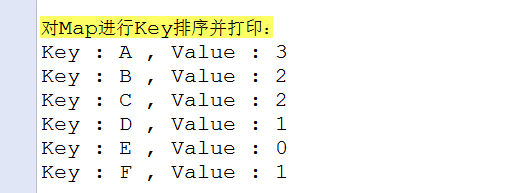
* 2. 根据Key对Map进行排序,并将每条Map.Entry按序输出,这种排序是稳定的,和Map的具体实现无关。
* 因为Key不同于Value,是唯一的。
*
* 3. 使Map保持插入顺序,并将每条Map.Entry按序输出,这时我们应该选用LinkedHashMap来实现Map。
* 因为LinkedHashMap本身就是保留插入顺序的。
*
* @author rico
* @created 2017年5月11日 上午9:01:53
*/
public class MapUtil {
/**
* @description 根据Value对Map进行排序,并将每条Map.Entry按序输出
* @author rico
* @created 2017年5月11日 上午9:14:10
* @param map
* 待排序的Map
* @param valueComparator
* Value的排序规则
*/
public static <K, V> void rankMapByValue(Map<K, V> map,
final Comparator<V> valueComparator) {
List<Map.Entry<K, V>> list = new ArrayList<Map.Entry<K, V>>(
map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<K, V>>() {
@Override
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
return valueComparator.compare(o1.getValue(), o2.getValue());
}
});
for (Map.Entry<K, V> entry : list) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
}
/**
* @description 根据Key对Map进行排序,并将每条Map.Entry按序输出
* @author rico
* @created 2017年5月11日 上午9:14:10
* @param map
* 待排序的Map
* @param valueComparator
* Key的排序规则
*/
public static <K, V> void rankMapByKey(Map<K, V> map,
final Comparator<K> keyComparator) {
List<Map.Entry<K, V>> list = new ArrayList<Map.Entry<K, V>>(
map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<K, V>>() {
@Override
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
return keyComparator.compare(o1.getKey(), o2.getKey());
}
});
for (Map.Entry<K, V> entry : list) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
}
public static void main(String[] args) {
// 使用HashMap实现
Map<String, Integer> hashMap = new HashMap<String, Integer>();
hashMap.put("D", 1);
hashMap.put("C", 2);
hashMap.put("A", 3);
hashMap.put("B", 2);
hashMap.put("F", 1);
hashMap.put("E", 0);
System.out.println("对HashMap实现的Map进行Value排序并打印:");
rankMapByValue(hashMap, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// TODO Auto-generated method stub
return Integer.compare(o1, o2);
}
});
System.out.println();
// 使用LinkedHashMap实现
Map<String, Integer> linkedHashMap = new LinkedHashMap<String, Integer>();
linkedHashMap.put("D", 1);
linkedHashMap.put("C", 2);
linkedHashMap.put("A", 3);
linkedHashMap.put("B", 2);
linkedHashMap.put("F", 1);
linkedHashMap.put("E", 0);
System.out.println("对LinkedHashMap实现的Map进行Value排序并打印:");
rankMapByValue(linkedHashMap, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// TODO Auto-generated method stub
return Integer.compare(o1, o2);
}
});
System.out.println("\n--------我是分割线--------\n");
System.out.println("对Map进行Key排序并打印:");
rankMapByKey(hashMap, String.CASE_INSENSITIVE_ORDER); // String的一个排序算子
System.out.println("\n--------我是分割线--------\n");
System.out.println("HashMap是不保持插入顺序的,是无序的:");
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
System.out.println();
System.out.println("LinkedHashMap是保持插入顺序的:");
for (Map.Entry<String, Integer> entry : linkedHashMap.entrySet()) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
}
}1、对Map根据Key进行排序并进行输出
在上述代码中,方法rankMapByValue实现了”如何对Map根据Value进行排序并进行输出呢?” 这个问题。算法的设计思路是:首先将给定的Map转换成一个以Map.Entry为元素的List,然后我们再使用容器工具类Collections对List进行排序。在进行排序时,客户端需要指定具体的排序规则,即需要传入具体的 Comparator。最后,我们将排序后的List依次打印输出。对应的代码片段如下:
/**
* @description 根据Value对Map进行排序,并将每条Map.Entry按序输出
* @author rico
* @created 2017年5月11日 上午9:14:10
* @param map
* 待排序的Map
* @param valueComparator
* Value的排序规则
*/
public static <K, V> void rankMapByValue(Map<K, V> map,
final Comparator<V> valueComparator) {
List<Map.Entry<K, V>> list = new ArrayList<Map.Entry<K, V>>(
map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<K, V>>() {
@Override
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
return valueComparator.compare(o1.getValue(), o2.getValue());
}
});
for (Map.Entry<K, V> entry : list) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
}其输出结果如下:
关于Java中的排序算子 Comparator 的更多介绍,请读者移步我的博文《Java Comparator Vs. Comparable》。
2、对Map根据Key进行排序并进行输出
在上述代码中,方法rankMapByKey实现了”如何对Map根据Key进行排序并进行输出呢?” 这个问题。本算法的设计思路与对Map根据Value进行排序并进行输出的设计思路类似,此不赘述。对应的代码片段如下:
/**
* @description 根据Key对Map进行排序,并将每条Map.Entry按序输出
* @author rico
* @created 2017年5月11日 上午9:14:10
* @param map
* 待排序的Map
* @param valueComparator
* Key的排序规则
*/
public static <K, V> void rankMapByKey(Map<K, V> map,
final Comparator<K> keyComparator) {
List<Map.Entry<K, V>> list = new ArrayList<Map.Entry<K, V>>(
map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<K, V>>() {
@Override
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
return keyComparator.compare(o1.getKey(), o2.getKey());
}
});
for (Map.Entry<K, V> entry : list) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
}其输出结果如下:
3、使Map保持插入顺序
在实际工作学习中,如果我们需要使Map保持插入顺序,那么我们的最佳做法就是使用LinkedHashMap来实现这个Map,因为LinkedHashMap本身就具有保留插入顺序这个特性。相应的测试代码如下:
public static void main(String[] args) {
// 使用HashMap实现
Map<String, Integer> hashMap = new HashMap<String, Integer>();
hashMap.put("D", 1);
hashMap.put("C", 2);
hashMap.put("A", 3);
hashMap.put("B", 2);
hashMap.put("F", 1);
hashMap.put("E", 0);
// 使用LinkedHashMap实现
Map<String, Integer> linkedHashMap = new LinkedHashMap<String, Integer>();
linkedHashMap.put("D", 1);
linkedHashMap.put("C", 2);
linkedHashMap.put("A", 3);
linkedHashMap.put("B", 2);
linkedHashMap.put("F", 1);
linkedHashMap.put("E", 0);
System.out.println("HashMap是不保持插入顺序的,是无序的:");
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
System.out.println();
System.out.println("LinkedHashMap是保持插入顺序的:");
for (Map.Entry<String, Integer> entry : linkedHashMap.entrySet()) {
System.out.println("Key : " + entry.getKey() + " , Value : "
+ entry.getValue());
}
}/* Output:
HashMap是不保持插入顺序的,是无序的:
Key : D , Value : 1
Key : E , Value : 0
Key : F , Value : 1
Key : A , Value : 3
Key : B , Value : 2
Key : C , Value : 2
--------我是分割线--------
LinkedHashMap是保持插入顺序的:
Key : D , Value : 1
Key : C , Value : 2
Key : A , Value : 3
Key : B , Value : 2
Key : F , Value : 1
Key : E , Value : 0
*///:~所以,使Map保持插入顺序最简单的办法就是使用LinkedHashMap实现。与LinkedHashMap相比,HashMap则是不能保证插入顺序,是乱序的。
1、题目描述
在本节,笔者分享华为一道与我们主题极为相关的笔试题《简单错误记录》。下面是这道编程题的详细描述。
题目:简单错误记录
题目描述:开发一个简单错误记录功能小模块,能够记录出错的代码所在的文件名称和行号,要求如下:
记录最多8条错误记录,对相同的错误记录(即文件名称和行号完全匹配)只记录一条,错误计数增加;(文件所在的目录不同,文件名和行号相同也要合并);
超过16个字符的文件名称,只记录文件的最后有效16个字符;(如果文件名不同,而只是文件名的后16个字符和行号相同,也不要合并)
输入的文件可能带路径,记录文件名称不能带路径
输入描述:
一行或多行字符串。每行包括带路径文件名称,行号,以空格隔开。
文件路径为windows格式
如:E:\V1R2\product\fpgadrive.c 1325
输出描述:
将所有的记录统计并将结果输出,格式:文件名代码行数数目,一个空格隔开,如: fpgadrive.c 1325 1
结果根据数目从多到少排序,数目相同的情况下,按照输入第一次出现顺序排序。
如果超过8条记录,则只输出前8条记录.
如果文件名的长度超过16个字符,则只输出后16个字符
输入例子:
E:\V1R2\product\fpgadrive.c 1325
输出例子:
fpgadrive.c 1325 1
2、题目求解
public class Main {
public static void main(String[] args) {
// 应该使用LinkedHashMap实现而不是Hashmap实现,因为题目输出描述中要求保证:
// 结果根据数目从多到少排序,数目相同的情况下,按照输入第一次出现顺序排序。
Map<String, Integer> map = new LinkedHashMap<String, Integer>();
String key;
String filename;
String path;
Scanner in = new Scanner(System.in);
while (in.hasNext()) {
path = in.next();
// 将路径转换为文件名
int id = path.lastIndexOf(‘\\‘);
// 如果找不到说明只有文件名没有路径
filename = id < 0 ? path : path.substring(id + 1);
int linenum = in.nextInt();
key = filename + " " + linenum;
// 统计频率
if (map.containsKey(key)) {
map.put(key, map.get(key) + 1);
} else {
map.put(key, 1);
}
}
in.close();
// 对记录进行排序
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(
map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
// 降序
@Override
public int compare(Map.Entry<String, Integer> value0,
Map.Entry<String, Integer> value1) {
return Integer.compare(value1.getValue(), value0.getValue());
}
});
// 只输出前8条
for (int i = 0; i < 8; i++) {
String[] str = list.get(i).getKey().split(" ");
String fname = str[0].length() > 16 ? str[0].substring(str[0]
.length() - 16) : str[0];
String count = str[1];
System.out.println(fname + " " + count + " " + list.get(i).getValue());
}
}
} 
如上图所示,程序被Accept。反观本题的具体实现,其本质上就是我们在上文提到过的算法。
关于HashMap 和 LinkedHashMap的深入介绍,请见笔者的博文《Map 综述(一):彻头彻尾理解 HashMap》 和 《Map 综述(二):彻头彻尾理解 LinkedHashMap》。
关于Java中的排序算子 Comparator 的更多介绍,请读者移步我的博文《Java Comparator Vs. Comparable》。
如果读者想更全面、详细的了解Java的泛型机制,请见笔者的巨长博文《Java 泛型(Generics) 综述》。
引用
标签:alt 友情 doc 学习 drive 华为 http 链接 分析
原文地址:http://blog.csdn.net/justloveyou_/article/details/71658696