标签:min .sh 内存 命令行 run 修改 方案 多个 ima
MongoDB的库级锁
MongoDB是目前最流行的NoSQL数据库,以其自然的文档型数据结构,灵活的数据模式以及简单易用的水平扩展能力而获得了很多开发人员的青睐。 但是金无足赤人无完人,MongoDB不是没有它的一些弱点,比如说它的库级锁就是人们经常抱怨的一个性能瓶颈。简单来说MongoDB的库级锁就是针对某一个数据库的所有写操作,必须在获得这个数据库仅有的一个互斥锁情况下才能进行。这个听上去很糟糕,但实际上由于一个写操作只是针对于内存数据更新的那一刹那保留锁,所以每个写锁的占用时间通常是在纳秒级别。正因为如此,实际应用中库级锁并没有对性能产生人们所担忧的那样显著的影响。
在少数超高并发写的应用场景下,库级锁会可能是一个瓶颈。这个可以通过MongoDB的MMS监控里面的DB Lock %(或者mongostat的命令行输出)指标来进行观察。一般情况下如果DB Lock %超过70-80%并持续就可以认为已经到饱和状态了。如何解决这个问题呢?
方案一: 分片
这个是MongoDB的标准答案如果你有足够的硬件资源。 分片是解决大部分性能瓶颈问题的终极方式。
方案二:分库
这是个非常有效的变通手段。具体做法就是把你的数据分到几个不同的数据库里,然后在应用程序里的数据访问层实现一个路由切换,保证数据读写会被指向到相应的数据库里。一个比较好的例子在一个人口普查的数据库里,你可以为每个省建一个单独的库。31个数据库组成一个逻辑大库。但是这种做法不是什么时候都能用的,比如说如果你需要很多整库数据的查询排序那样的操作,那么协调多个库的结果就会显得很麻烦或者无法实现。
方案三:等待
MongoDB 2.8 即将发布。2.8的最大改动就是把库级锁改成了文档级锁。由库级锁引起的性能问题应该有望得到较大改善。
方案四:微分片
微分片的定义就是使用MongoDB的分片技术,但是多个或者全部分片Mongod运行在同一台服务器(服务器可以是物理机或者虚机)上。由于库级锁的存在,以及MongoDB对多核CPU的利用率不是很高的特性,微分片在满足以下条件的场景下会是一个不错的性能调优手段:
1) 服务器有多核(4或8或更多)CPU
2) 服务器尚未出现IO瓶颈
3) 有足够内存装下热数据(没有出现频繁的 page faults)
在这篇文章里我们通过做一些性能测试来看一下使用微分片技术以后对性能提升的影响。
YCSB 性能测试工具
在开始测试之前,我想首先花点时间介绍一下YCSB这个工具。原因是很多时候我看到开发工程师或者DBA们做测试的时候往往会用一些非常简单的工具作为客户端进行高并发的插入或读取测试。MongoDB本身是一个高性能的数据库,并发量在适当调优的情况下可以达到每秒数万级。如果客户端的代码是简单粗暴型的,甚至使用单线程的客户端,那么性能测试的瓶颈首先就是在客户端本身,而不是服务器。所以选择一个高效的客户端是一个好的性能测试的重要的第一步。
YCSB是Yahoo开发的一个专门用来对新一代数据库进行基准测试的工具。全名是Yahoo! Cloud Serving Benchmark。 他们开发这个工具的目的是希望有一个标准的工具用来衡量不同数据库的性能。YCSB做了很多优化来提高客户端性能,例如在数据类型上用了最原始的比特数组以减少数据对象本身创建转换所需的时间等。YCSB的几大特性:
* 支持常见的数据库读写操作,如插入,修改,删除及读取
* 多线程支持。YCSB用Java实现,有很好的多线程支持。
* 灵活定义场景文件。可以通过参数灵活的指定测试场景,如100%插入, 50%读50%写等等
* 数据请求分布方式:支持随机,zipfian(只有小部分的数据得到大部分的访问请求)以及最新数据几种请求分布方式
* 可扩展性:可以通过扩展Workload的方式来修改或者扩展YCSB的功能
安装YCSB
由于YCSB本身会承担很大的工作量,一般建议部署YCSB在单独的机器上,最好是4-8核CPU,8G内存以上。YCSB和数据库服务器最少要保证千兆的带宽,最好是万兆级。
* 安装JDK 1.7
* 下载实现了MongoDB驱动的YCSB编译版: http://pan.baidu.com/s/1o6iFcfS
* 解压缩
* 进入到ycsb目录并运行(本地要有一个Mongo数据库在 27017端口上):
./bin/ycsb run mongodb -P workloads/workloada
* 如果YCSB可以运行则表明安装成功
你也可以用Git把源文件拉下来自己编译。需要JDK和Maven工具。Github地址是:https://github.com/achille/YCSB 可以参考这个页面进行编译安装YCSB: https://github.com/achille/YCSB/tree/master/mongodb
YCSB场景文件
使用YCSB测试不同场景只需要提供不同的场景文件就可以。YCSB会按照你的场景文件的属性而自动生成响应的客户端请求。在我们这次测试里我们会使用到几种场景:
场景S1: 100%插入。用来加载测试数据
场景S2: 写多读少 90% 更新 10%读
场景S3: 混合读写 65%读, 25% 插入, 10% 更新
场景S4: 读多写少 90% 读, 10% 插入、更新
场景S5: 100%读
如下是其中场景文件S2的内容:
recordcount=5000000
operationcount=100000000
workload=com.yahoo.ycsb.workloads.CoreWorkload
readallfields=true
readproportion=0.1
updateproportion=0.9
scanproportion=0
insertproportion=0
requestdistribution=uniform
insertorder=hashed
fieldlength=250
fieldcount=8
mongodb.url=mongodb://192.168.1.2:27017
mongodb.writeConcern=acknowledged
threadcount=32
一些说明:
* 测试数据包括500万个文档(recordcount)
* 每个文档大小大约2KB(fieldlength x fieldcount)。数据总共大小是10G+600M的索引
* MongoDB数据库的url是192.168.1.2:27017
* MongoDB的写安全设置(mongodb.writeConcern)是acknowledged
* 线程数是32(threadcount)
* 插入文档的顺序:哈希/随机 (insertorder)
* 更新操作: 90% (0.9)
* 读操作: 10% (0.1)
点击此处下载所有场景文件(S1 – S5) 并解压到上面创建的ycsb目录下面: http://pan.baidu.com/s/1voJAA
MongoDB配置
本次测试是在AWS的虚拟主机上进行测试的。以下是服务器配置情况:
* OS: Amazon Linux (和CentOS基本类似)
* CPU: 8 vCPU
* RAM: 30G
* Storage: 160G SSD
* Journal: 25G EBS with 1000 PIOPS
* Log: 10G EBS with 250 IOPS
*
* MongoDB: 2.6.0
* Readahead:32
几点说明:
MongoDB的数据,恢复日志(journal)以及系统日志(log)分别用了3个不同的存储盘。这是一个常见的优化方式,以保证写日志的操作不会影响到数据的刷盘IO。另外服务器的readahead设置改到了推荐的32。关于readahead等可以参见我的另一个博客:http://mongoing.com/tj/linux-tuning
单机基准测试
在我们测试使用微分片性能之前我们首先需要得出单机的最高性能。启动目标MongoDB服务器,登录上去后先删除ycsb数据库(如果已经存在)
# mongo
> use ycsb
> db.dropDatabase()
场景S1: 数据插入
接下来开始运行YCSB。进到ycsb目录下,运行以下命令(确认当前目录下已经有场景文件S1, S2, S3, S4,S5)
./bin/ycsb load mongodb -P S1 -s
如果运行正常,你会看到每隔10秒YCSB打印一下当前状态,包括每秒的并发率以及平均响应时间。 如:
Loading workload…
Starting test.
0 sec: 0 operations;
mongo connection created with localhost:27017/ycsb
10 sec: 67169 operations; 7002.16 current ops/sec; [INSERT AverageLatency(us)=4546.87]
20 sec: 151295 operations; 7909.24 current ops/sec; [INSERT AverageLatency(us)=3920.9]
30 sec: 223663 operations; 7235.35 current ops/sec; [INSERT AverageLatency(us)=4422.63]
在运行的同时你可以用mongostat(或者更好的选择:MMS)来监控MongoDB的实时指标,看是否和YCSB的报告大体一致。
运行结束后可以看到类似于如下输出:
[OVERALL], RunTime(ms), 687134.0
[OVERALL], Throughput(ops/sec), 7295.168457372555
…
[INSERT], Operations, 5000000
[INSERT], AverageLatency(us), 4509.1105768
[INSERT], MinLatency(us), 126
[INSERT], MaxLatency(us), 3738063
[INSERT], 95thPercentileLatency(ms), 10
[INSERT], 99thPercentileLatency(ms), 37
[INSERT], Return=0, 5000000
…
这个输出告诉我们插入了500万条记录, 耗时687秒,平均并发量每秒7295条,平均响应时间4.5ms。注意这个数值本身来说对于MongoDB的性能指标没有任何参考价值。如果你的环境有任意一点不一致,或者插入数据的大小,或者索引的多少不一样,都会导致结果很大的不同。所以这个值只能在作为本次测试和微分片性能比较的基准值。
在MongoDB方面,要特别注意一下mongostat或者MMS汇报的page faults,network,DB Lock %等指标。如果你的network是1Gb/s 而mongostat汇报了100m的数字,那你的网络就基本是饱和了。1Gb/s的带宽也就是128m/s的传输速率。在我的这个测试里network in保持在14-15m/s的样子,和每秒的并发率及文档大小(7300x2KB)是一致的。
为了找到一个比较理想的客户端线程数,我对同样的操作重复了多次,每一次修改了场景文件里面的threadcount数值。测试的结果发现到了30 个线程左右并发量就到达了最高值。再增加线程数量性能不再提高。因为我的场景文件中的threadcount值设为32。
现在我们已经在数据库内有了500万测试数据,现在我们可以测一下其他的几个场景。注意:YCSB的第一个参数是测试阶段。刚才是数据导入所以第一个参数是”load”。导入完数据后接下来就是运行阶段所以第二个参数都是”run”。
场景S2: 写多读少
命令:
./bin/ycsb run mongodb -P S2 -s
结果
…
[OVERALL], Throughput(ops/sec), 12102.2928384723
场景S3: 混合读写(65%read)
命令:
./bin/ycsb run mongodb -P S3 -s
结果
…
[OVERALL], Throughput(ops/sec), 15982.39239483840
场景S4: 读多写少
命令:
./bin/ycsb run mongodb -P S4 -s
结果
…
[OVERALL], Throughput(ops/sec), 19102.39099223948
场景S5: 100% 读
命令:
./bin/ycsb run mongodb -P S5 -s
结果
…
[OVERALL], Throughput(ops/sec), 49020.29394020022
微分片测试
刚才我们已经得到了单机在5个场景下的性能指标。接下来我们可以开始测试在微分片以及不同数量微分片的情景下的性能指标。
首先我们停掉单机上MongoDB数据库。
接下来我们要建一个分片集群。在这里让我要推荐给大家一个非常方便的MongoDB工具:mtools https://github.com/rueckstiess/mtools
mtools是几个MongoDB相关工具的集合,其中的mlaunch可以帮助我们不费吹灰之力地在单机上创建复制集或分片集群。
安装mtools(需要Python以及Python的包管理工具pip 或者easy_install):
# pip install mtools 或 easy_install mtools
然后建一个新的目录并在新目录下创建微分片集群:
# mkdir shard2
# cd shard2
# mlaunch –sharded 2 –single
这个命令会在同一台机器上创建一下4个进程:
* 1 个mongos 在27017 端口
* 1 个配置服务器的mongod 在27020端口
* 2 个分片服务器的mongod 在27018和27019端口
这四个进程组成了具有两个分片的微分片集群。值得指出的是虽然我们已经搭建了一个分片集群,在这个时候所有的数据还是只会去到其中一个分片,这个分片叫做主分片。要让MongoDB把数据分布到各个分片上,必须显式地激活需要分片的数据库以及集合名。
# mongo
mongos> sh.enableSharding(“ycsb”)
{ “ok” : 1 }
mongos> sh.shardCollection(“ycsb.usertable”, {_id:”hashed”})
{ “collectionsharded” : “ycsb.usertable”, “ok” : 1 }
上述两个命令分别激活了 ”ycsb“ 数据库以及库内 “usertable”集合的分片功能。在对集合开启分片的时候还需要指定分片键。在这里我们使用了 {_id: “hashed” } 表示使用 _id 字段的哈希值作为分片键。哈希值分片键对大量写的场景比较合适,可以把写操作均匀的分布到各个分片上。
接下来我们可以按顺序运行以下5个场景并收集测试结果(注意ycsb的第一个参数):
./bin/ycsb load mongodb -P S1 -s
./bin/ycsb run mongodb -P S2 -s
./bin/ycsb run mongodb -P S3 -s
./bin/ycsb run mongodb -P S4 -s
./bin/ycsb run mongodb -P S5 -s
测试完以后要用下述命令关掉整个集群:
# mlaunch stop
以次类推,可以对4个,6个,和8个成员的微分片集群分别建立单独的目录并重复5个场景的测试。如下是所有测试结果:

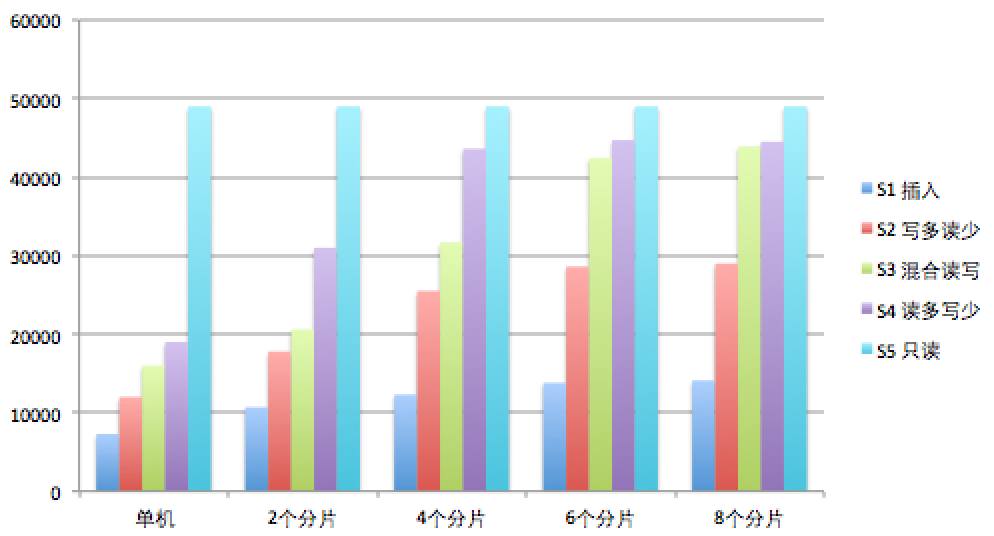
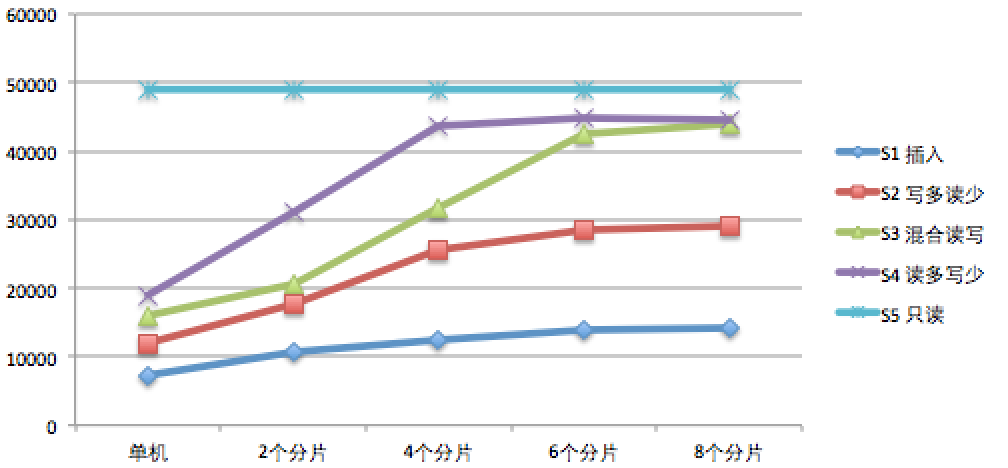
结论
从上表我们可以得出以下结论
* 微分片在合适的应用场景下可以显著的提高MongoDB并发量
* 微分片对只读的应用场景没有任何帮助
* 微分片对混合读写的场景(也是实际中最常见的场景)的优化最好:275%
* 6个微分片就已经基本到了饱和状态,再增加更多分片已经没有明显改善。 这个数字可能会因人而异
标签:min .sh 内存 命令行 run 修改 方案 多个 ima
原文地址:http://www.cnblogs.com/wuhl-89/p/6846104.html