标签:profile code color 而不是 部分 默认 .com 关键字 UI
索引(在MySQL中也叫键(key))是存储引擎用于快速找到记录的一种数据结构。
索引类型有:Normal,Unique,FullText。
索引方法有:BTREE、HASH。
我有一个user_info的测试表
里面随机生成了300个姓名
一、索引基础
创建一个普通索引:
mysql> create index myindex on user_info(username); Query OK, 0 rows affected Records: 0 Duplicates: 0 Warnings: 0
也可以指定索引的长度:
create index myindex on user_info (username(3));
创建一个唯一索引:
mysql> create unique index uindex on user_info (id); Query OK, 0 rows affected Records: 0 Duplicates: 0 Warnings: 0
创建一个全文索引:(InnoDB引擎对全文索引的支持是5.6版本引入的)
mysql> create fulltext index findex on user_info (username); Query OK, 0 rows affected Records: 0 Duplicates: 0 Warnings: 1
到目前为止创建了三个索引:
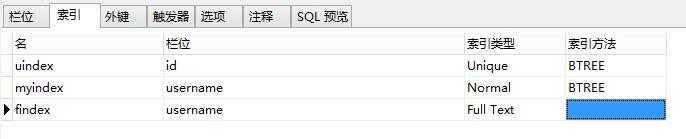
可以看出,默认的索引方法是BTREE。
删除索引:
mysql> drop index findex on user_info; Query OK, 0 rows affected Records: 0 Duplicates: 0 Warnings: 0 mysql> drop index uindex on user_info; Query OK, 0 rows affected Records: 0 Duplicates: 0 Warnings: 0
关键词解释:
主键:当我们创建主键的时候,同时分配了一个唯一索引,也就是“主索引”,不过与唯一索引不一样的是,主键用关键字Primary 而不是 Unique。
外键:一般外键字段为某个表的主键,关键字为Foreign Key
普通索引:这种索引是最基本的索引,作用就是加快数据的访问速度。
唯一索引:普通索引允许数据列包括重复的数据,而唯一索引不允许。
全文索引:该索引可以用于全文搜索。
二、索引设计的原则
1. 最适合索引的列是出现在where子句后面的列,或连接子句中出现的列。
2. 使用唯一索引。考虑列中值的分布。索引的列基数越大,索引的效果越好。
3. 使用短索引。如果对字符串列进行索引,应该指定一个前缀长度。
4. 利用最左前缀。
5. 不要过度索引。
这里解释一下最左前缀:
我创建了一个组合索引:
mysql> create index nindex on user_info (username(3),password(6)); Query OK, 0 rows affected Records: 0 Duplicates: 0 Warnings: 0
实际上我相当于建立了两个索引,分别是:
username,password
username
而没有password。
因为这是MySQL组合索引“最左前缀”的结果。简单理解就是只从最左边开始组合。
例如:
mysql> explain select * from user_info where username = ‘茹芬慧‘ and password = ‘123456‘; +----+-------------+-----------+------+----------------+---------+---------+-------+------+------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+----------------+---------+---------+-------+------+------------------------------------+ | 1 | SIMPLE | user_info | ref | myindex,nindex | myindex | 767 | const | 1 | Using index condition; Using where | +----+-------------+-----------+------+----------------+---------+---------+-------+------+------------------------------------+ 1 row in set mysql> explain select * from user_info where password = ‘123456‘; +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | user_info | ALL | NULL | NULL | NULL | NULL | 300 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ 1 row in set
第一个使用了索引,d第二个没有。
三、语句什么时候执行索引,什么时候不执行?
为什么要写这个,这个标题的意思不是告诉你什么时候用索引,而是告诉你当你使用索引的时候,索引什么时候不干活。
例子1:
mysql> select * from user_info where username like ‘%茹%‘; +-----+----------+----------+------------+ | id | username | password | mydate | +-----+----------+----------+------------+ | 24 | 茹芬慧 | 123456 | 2017-04-28 | | 144 | 茹瑛炫 | 123456 | 2017-04-28 | +-----+----------+----------+------------+ 2 rows in set mysql> select * from user_info where username like ‘茹%‘; +-----+----------+----------+------------+ | id | username | password | mydate | +-----+----------+----------+------------+ | 144 | 茹瑛炫 | 123456 | 2017-04-28 | | 24 | 茹芬慧 | 123456 | 2017-04-28 | +-----+----------+----------+------------+ 2 rows in set
这两个查询语句都查出了结果,可是到底有没有好好干活呢?
mysql> explain select * from user_info where username like ‘%茹%‘; +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | user_info | ALL | NULL | NULL | NULL | NULL | 300 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ 1 row in set mysql> explain select * from user_info where username like ‘茹%‘; +----+-------------+-----------+-------+---------------+---------+---------+------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+-------+---------------+---------+---------+------+------+-----------------------+ | 1 | SIMPLE | user_info | range | myindex | myindex | 767 | NULL | 2 | Using index condition | +----+-------------+-----------+-------+---------------+---------+---------+------+------+-----------------------+ 1 row in set
看吧,第一个扫描了全部行,而第二个就令我们满意了。
mysql> set profiling = 1; Query OK, 0 rows affected mysql> select * from user_info where username like ‘%茹%‘; +-----+----------+----------+------------+ | id | username | password | mydate | +-----+----------+----------+------------+ | 24 | 茹芬慧 | 123456 | 2017-04-28 | | 144 | 茹瑛炫 | 123456 | 2017-04-28 | +-----+----------+----------+------------+ 2 rows in set mysql> select * from user_info where username like ‘茹%‘; +-----+----------+----------+------------+ | id | username | password | mydate | +-----+----------+----------+------------+ | 144 | 茹瑛炫 | 123456 | 2017-04-28 | | 24 | 茹芬慧 | 123456 | 2017-04-28 | +-----+----------+----------+------------+ 2 rows in set mysql> show profiles; +----------+-----------+----------------------------------------------------+ | Query_ID | Duration | Query | +----------+-----------+----------------------------------------------------+ | 1 | 0.0005955 | select * from user_info where username like ‘%茹%‘ | | 2 | 0.000492 | select * from user_info where username like ‘茹%‘ | +----------+-----------+----------------------------------------------------+ 2 rows in set
用了索引的快。
结论一:MySQL能在索引中做最左前缀匹配的LIKE比较,因为该操作可以转换为简单的比较操作,但是!如果是以通配符开头的LIKE查询,就完蛋了。
例子2:
今天重新生成了一下数据,一共798条
我想测试一下group by。
mysql> select count(*),mydate from user_info group by mydate; +----------+---------------------+ | count(*) | mydate | +----------+---------------------+ | 300 | 2017-04-30 10:07:04 | | 199 | 2017-04-30 10:37:19 | | 299 | 2017-04-30 10:37:34 | +----------+---------------------+ 3 rows in set
把mydate字段加上索引,并再次执行上面的语句
mysql> create index tindex on user_info (mydate); Query OK, 0 rows affected Records: 0 Duplicates: 0 Warnings: 0 mysql> select count(*),mydate from user_info group by mydate; +----------+---------------------+ | count(*) | mydate | +----------+---------------------+ | 300 | 2017-04-30 10:07:04 | | 199 | 2017-04-30 10:37:19 | | 299 | 2017-04-30 10:37:34 | +----------+---------------------+ 3 rows in set
最后,比较加上索引与不加索引的区别
mysql> show profiles; +----------+------------+-----------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-----------------------------------------------------------+ | 1 | 0.0007455 | select count(*),username from user_info group by username | | 2 | 0.003184 | select count(*),password from user_info group by password | | 3 | 0.000651 | select * from user_info where password = ‘aedd902d‘ | | 4 | 0.0002475 | select count(*) from user_info where group by mydate | | 5 | 0.0182485 | select count(*) from user_info group by mydate | | 6 | 0.0012275 | select count(*),mydate from user_info group by mydate | | 7 | 0.00123675 | select count(*),username from user_info group by username | | 8 | 0.2569555 | create index tindex on user_info (mydate) | | 9 | 0.00111575 | select count(*),mydate from user_info group by mydate | +----------+------------+-----------------------------------------------------------+ 9 rows in set
只需要看6和9,虽然索引快了一些,但是基本上可以忽略了,这是因为我mydate字段重复的太多,不利于索引。
结论2:索引的选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在执行的时候过滤掉更多的行。(选择性=不重复的索引值(也称为基数)/数据表的记录总数)
例如我的:
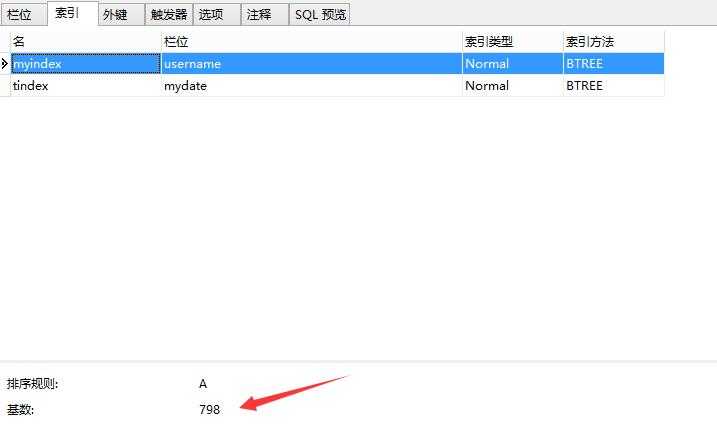
username的选择性为1,效率最高
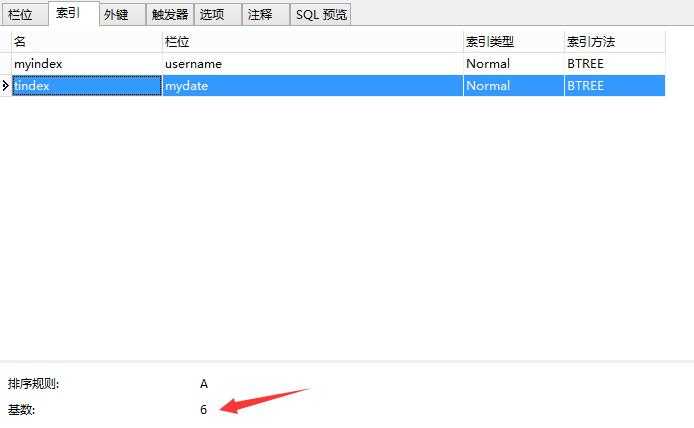
mydate的选择性为6/798,效率非常差
例子3:
mysql> select * from user_info where id + 1 = 798; +-----+----------+----------+---------------------+ | id | username | password | mydate | +-----+----------+----------+---------------------+ | 797 | 燕淞可 | 3e68fcdd | 2017-04-30 10:37:34 | +-----+----------+----------+---------------------+ 1 row in set mysql> select * from user_info where id = 797; +-----+----------+----------+---------------------+ | id | username | password | mydate | +-----+----------+----------+---------------------+ | 797 | 燕淞可 | 3e68fcdd | 2017-04-30 10:37:34 | +-----+----------+----------+---------------------+ 1 row in set
这两条查询语句代表的意思一样,但是执行起来就一样吗?效率差太多了
mysql> show profiles; | 11 | 0.00116025 | select * from user_info where id + 1 = 798 | | 12 | 0.000483 | select * from user_info where id = 797 |
查看Explain
mysql> explain select * from user_info where id + 1 = 798; +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | user_info | ALL | NULL | NULL | NULL | NULL | 798 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+------+-------------+ 1 row in set mysql> explain select * from user_info where id = 797; +----+-------------+-----------+-------+---------------+---------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+-------+---------------+---------+---------+-------+------+-------+ | 1 | SIMPLE | user_info | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL | +----+-------------+-----------+-------+---------------+---------+---------+-------+------+-------+ 1 row in set
这是因为如果查询的列而不是独立的,就不会使用索引。“独立的列”指的是:不能是表达式的一部分,也不能是函数的一部分。
结论三:查询的列需要独立
例子4:
前缀索引,什么时候用呢。对于BLOB,TEXT或者很长的Varchar,我们就不得不使用前缀索引了,并且MySQL不允许索引这些列的完整长度。
但是!对于前缀索引,多长才合适呢?
首先,计算完整列的选择性:
mysql> select count(distinct password)/count(*) from user_info; +-----------------------------------+ | count(distinct password)/count(*) | +-----------------------------------+ | 1.0000 | +-----------------------------------+ 1 row in set
(⊙o⊙)…这是个失误,都怪我这个生成的都好唯一啊。那就干讲吧。
完整列的选择性 = (目标列不重复数目)/(数据总数)
然后计算前缀的选择性,并且让前缀的选择性接近完整列的选择性。
前缀的选择性 = count(distinct left(【列名】,【长度】))/(数据总数)
前缀的选择性需要去换数值一个一个试的。
等你找到了合适的长度,就可以添加这个索引了
create index yourindex on yourtable (yourcol(yourlength));
不过无法用前缀索引做Group By 和Order By。
结论四:如果需要索引很长的字符列,那就使用前缀索引
例子5:
最近比较忙,未完待续...
标签:profile code color 而不是 部分 默认 .com 关键字 UI
原文地址:http://www.cnblogs.com/LUA123/p/6776441.html