标签:exist .sh migrate 分解 prim rate ide 应用 演示
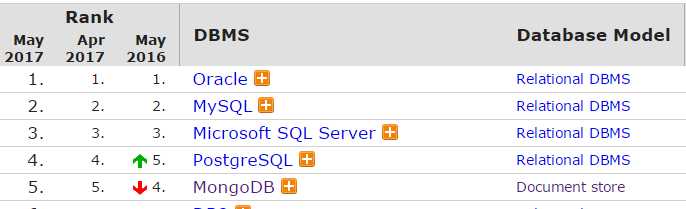
mongodb是目前使用非常广泛的nosql(not only sql)之一,在db engines上排名非常靠前,下图是5月份的排名:
MongoDB is an open-source document database that provides high performance, high availability, and automatic scaling.
开源、基于文档(document oriented)、高性能、高可用、自动伸缩。
开源:
这个好处就不用多说了,GitHub上有源码。
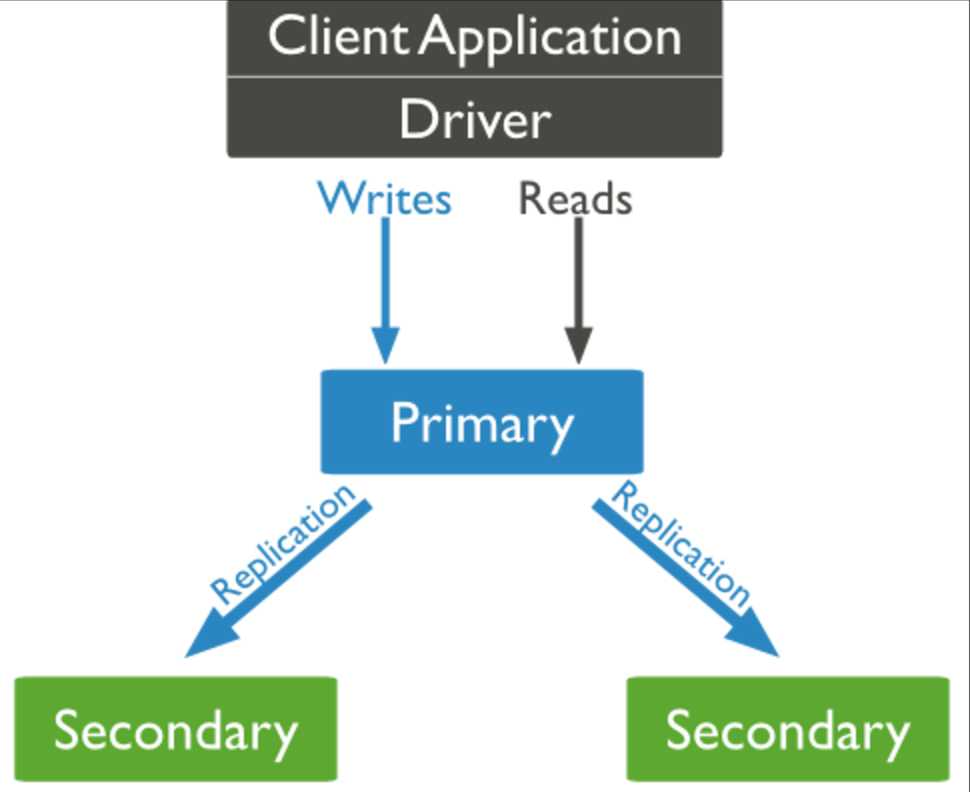
应用程序通过驱动与Primary连接,所有的写操作都在Primary上进行,同时primary会将这些操作写到oplog(operation log)中,secondary通过异步复制oplog,然后在本地数据集上执行oplog中的操作,这样就达到了数据的一致性。从这里可以看到,虽然secondary和primary维护的上同一份数据,但是其变更是要迟于primary的。
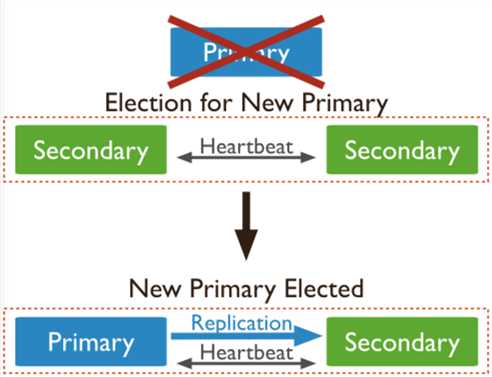
自动的failover 虽然保证了mongodb的高可用性,但是在primary到secondary的切换过程中,这一段时间,mongodb是无法提供写操作的。表现就是对于应用程序的数据库操作请求会返回一些错误,这个时候应用程序需要识别这些错误,然后做重试。
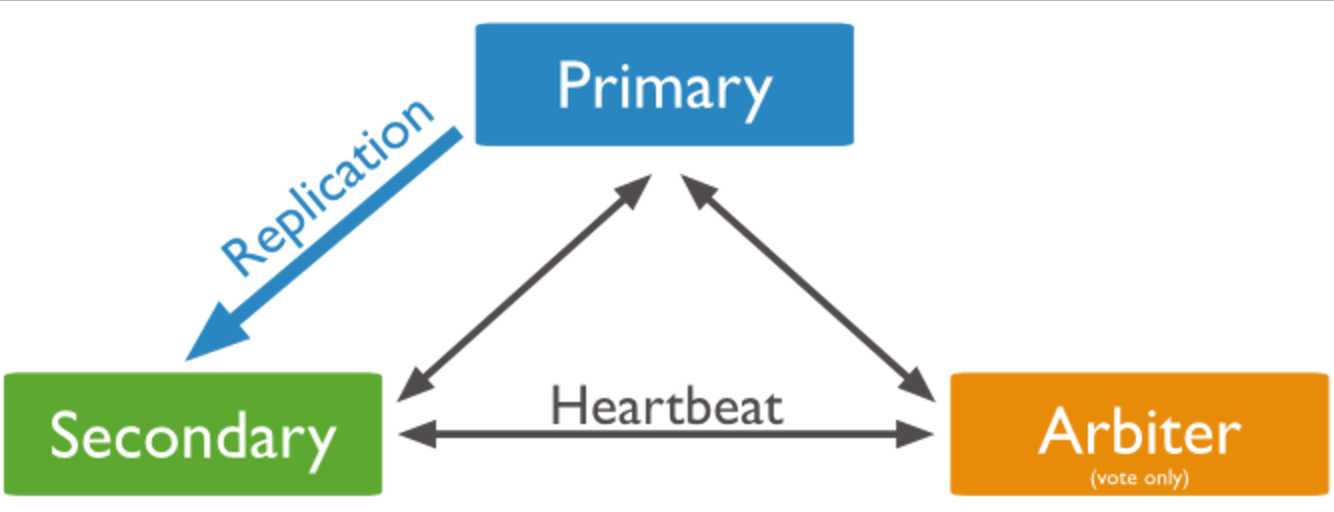
除了Primary和Secondary,在replica set中还可以存在存在另外一种节点:Arbiter。Arbiter与Secondary节点的区别在于,Arbiter不持久化数据(do not bearing data), 自然也不可能在Primary挂掉的时候被选举。Arbiter的作用在于投票:为了选出新的primary,secondary投票规则是少数服从多数,如果replica set中的节点数目是偶数,那么就可能出现“平局”的情况,所以加入一个Arbiter就可以以最小的代价解决这个问题。
所谓sharding就是将同一个集合的不同子集分发存储到不同的机器(shard)上,Mongodb使用sharding机制来支持超大数据量,将不同的CRUD路由到不同的机器上执行,提到了数据库的吞吐性能。由此可见,sharding是非常常见的scale out方法。
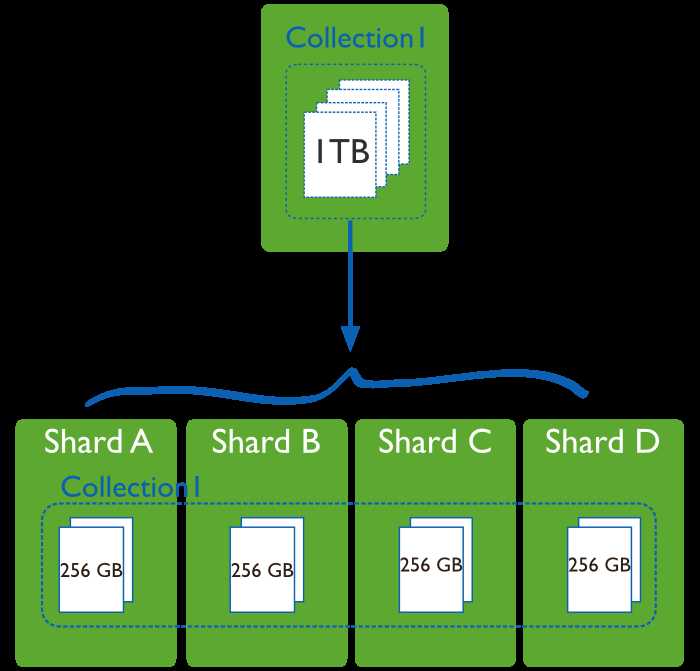
如上图所示,一个集合(Collection1)有1T的数据,原本放在一个单独的数据库中,通过sharding,将这个集合的数据放在四个独立的shard中,每一个shard存储这个集合256G的数据。每个shard物理上是独立的数据库,但逻辑上共同组成一个数据库。
一个sharded cluster由一下三部分组成:config server,shards,router。如图所示:
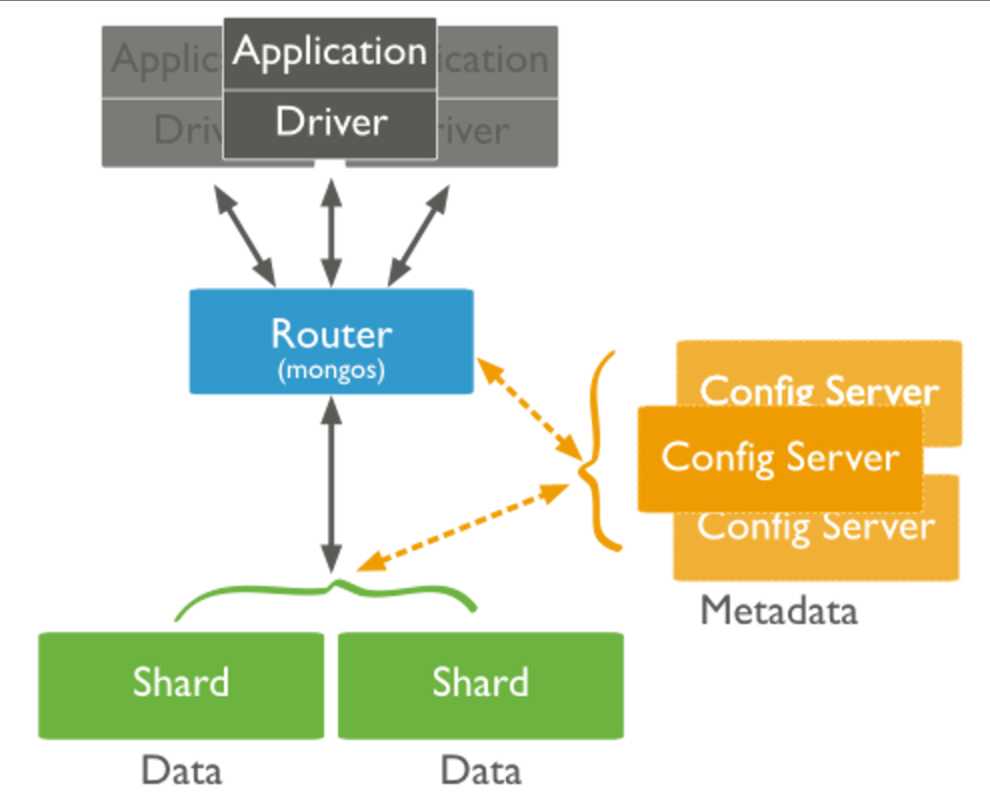
shards:
存储数据,可以是单个的mongod,也可以是replica set。在生产环境中,为了提高高可用性,都会使用replica set。存储在mongod上的数据以chunk为基本单位,默认的大小为64M,后面会介绍shard上数据的分裂(split)与迁移(migration)
config server:
存储集群的元数据(metadata),即数据的哪一部分放在哪一个shard上,router将会利用这些元数据将请求分发到对应的shards上,shards上chunk的迁移也是config server来控制的。
router:
mongos实例,在一个集群中直接为应用程序提供服务,利用config server上的元数据来制定最佳的查询计划。
数据分割(data partition):
从前文知道,MongoDB在collection这个级别进行数据的切块,称之为sharding。块的最小粒度是chunk,其大小(chunkSize)默认为64M。
当一个集合的数据量超过chunkSize的时候,就会被拆分成两个chunk,这个过程称为splitting。那么按照什么原则将一个chunk上的数据拆分成两个chunk,这就是Sharding key的作用,Sharding key是被索引的字段,通过sharding key,就可以把数据均分到两个chunk,每一个document在哪一个chunk上,这就是元数据信息。元数据信息存放在config server上,方便router使用。
如果sharding cluster中有多个shard,那么不同shard上的chunk数目可能是不一致的,这个时候会有一个后台进程(balancer)来迁移(migrate)chunk,从chunk数目最多的shard迁移到chunk数目最少的chunk,直到达到均衡的状态。迁移的过程对应用程序来说是透明的。
如下图所示,迁移之前ShardA ShardB上都有3个chunk,而Shard C上只有一个Chunk。通过从ShardB上迁移一个chunk到ShardC,就达到了一个均衡的状态。 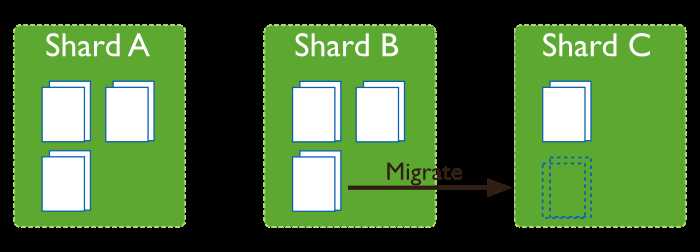
splitting和migration 的目的是为了让数据在shards之间均匀分布,其根本目标是为了将对数据的CRUD操作均衡地分发到各个shard,提高集群的并发性能。
1 #!/bin/bash 2 export BIN_HOME=/usr/local/mongodb/bin 3 export DB_PATH=/home/mongo_db/data 4 export LOG_PATH=/home/mongo_db/log 5 6 LOCAL=127.0.0.1 7 8 #config rs 9 export RS1_1_DB_PATH=$DB_PATH/rs1_1 10 export RS1_2_DB_PATH=$DB_PATH/rs1_2 11 export RS1_3_DB_PATH=$DB_PATH/rs1_3 12 export RS2_1_DB_PATH=$DB_PATH/rs2_1 13 export RS2_2_DB_PATH=$DB_PATH/rs2_2 14 export RS2_3_DB_PATH=$DB_PATH/rs2_3 15 16 export RS1_1_DB_LOG=$LOG_PATH/rs1_1.log 17 export RS1_2_DB_LOG=$LOG_PATH/rs1_2.log 18 export RS1_3_DB_LOG=$LOG_PATH/rs1_3.log 19 export RS2_1_DB_LOG=$LOG_PATH/rs2_1.log 20 export RS2_2_DB_LOG=$LOG_PATH/rs2_2.log 21 export RS2_3_DB_LOG=$LOG_PATH/rs2_3.log 22 23 export RS1_1_PORT=27018 24 export RS1_2_PORT=27019 25 export RS1_3_PORT=27020 26 export RS2_1_PORT=27021 27 export RS2_2_PORT=27022 28 export RS2_3_PORT=27023 29 30 export RS1=rs1 31 export RS2=rs2 32 33 #config config_server 34 export CONF1_DB_PATH=$DB_PATH/db_conf1 35 export CONF2_DB_PATH=$DB_PATH/db_conf2 36 export CONF3_DB_PATH=$DB_PATH/db_conf3 37 38 export CONF1_DB_LOG=$LOG_PATH/conf1.log 39 export CONF2_DB_LOG=$LOG_PATH/conf2.log 40 export CONF3_DB_LOG=$LOG_PATH/conf3.log 41 42 export CONF1_PORT=40000 43 export CONF2_PORT=40001 44 export CONF3_PORT=40002 45 46 export CONF1_HOST=$LOCAL:$CONF1_PORT 47 export CONF2_HOST=$LOCAL:$CONF2_PORT 48 export CONF3_HOST=$LOCAL:$CONF3_PORT 49 50 #config route_server 51 export ROUTE_DB_LOG=$LOG_PATH/route.log 52 53 export ROUTE_PORT=27017
可以在会话窗口中将这些命令执行一遍,不过更好的方式是将其保存在一个文件中(如mongodb_define.sh),然后执行这个文件就行了:source mongodb_define.sh
$BIN_HOME/mongod --port $RS1_1_PORT --dbpath $RS1_1_DB_PATH --fork --logpath $RS1_1_DB_LOG --replSet $RS1 --smallfiles --nojournal
$BIN_HOME/mongod --port $RS1_2_PORT --dbpath $RS1_2_DB_PATH --fork --logpath $RS1_2_DB_LOG --replSet $RS1 --smallfiles --nojournal
$BIN_HOME/mongod --port $RS1_3_PORT --dbpath $RS1_3_DB_PATH --fork --logpath $RS1_3_DB_LOG --replSet $RS1 --smallfiles --nojournal

_id : "rs1",
members : [
{_id : 0, host : "127.0.0.1:27018"},
{_id : 1, host : "127.0.0.1:27019"},
{_id : 2, host : "127.0.0.1:27020", arbiterOnly: true},
]
}
>rs.initiate(config)
mkdir -p $RS2_1_DB_PATH
mkdir -p $RS2_2_DB_PATH
mkdir -p $RS2_3_DB_PATH
$BIN_HOME/mongod --port $RS1_1_PORT --dbpath $RS1_1_DB_PATH --fork --logpath $RS1_1_DB_LOG --replSet $RS1 --smallfiles --nojournal
$BIN_HOME/mongod --port $RS1_2_PORT --dbpath $RS1_2_DB_PATH --fork --logpath $RS1_2_DB_LOG --replSet $RS1 --smallfiles --nojournal
$BIN_HOME/mongod --port $RS1_3_PORT --dbpath $RS1_3_DB_PATH --fork --logpath $RS1_3_DB_LOG --replSet $RS1 --smallfiles --nojournal
mongo --port $RS2_1_PORT
>config = {
_id : "rs2",
members : [
{_id : 0, host : "127.0.0.1:27021"},
{_id : 1, host : "127.0.0.1:27022"},
{_id : 2, host : "127.0.0.1:27023", arbiterOnly: true},
]
}
>rs.initiate(config)
mongodb官方建议config server需要三个mongod实例组成,每一个mongod最好部署在不同的物理机器上。这个三个mongod并不是复制集的关系,
step1:创建db目录
mkdir -p $CONF1_DB_PATH
mkdir -p $CONF2_DB_PATH
mkdir -p $CONF3_DB_PATH
step2:启动三个mongod实例:
$BIN_HOME/mongod --port $CONF1_PORT --dbpath $CONF1_DB_PATH --fork --logpath $CONF1_DB_LOG --configsvr --smallfiles --nojournal
$BIN_HOME/mongod --port $CONF2_PORT --dbpath $CONF2_DB_PATH --fork --logpath $CONF2_DB_LOG --configsvr --smallfiles --nojournal
$BIN_HOME/mongod --port $CONF3_PORT --dbpath $CONF3_DB_PATH --fork --logpath $CONF3_DB_LOG --configsvr --smallfiles --nojournal
同样启动参数中nojournal只是为了节省存储空间,在生产环境中一定要使用journaling。与创建replica set时mongod的启动不同的是,这里有一个configsvr 选项,表明这些节点都是作为config server存在。
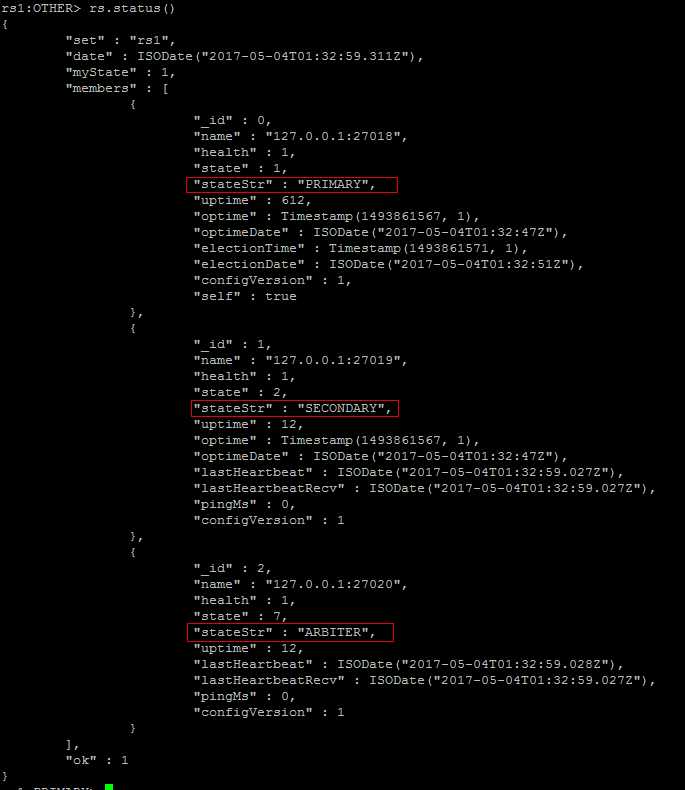
再启动这三个mongod之后,不会有类似replica set那样讲三个mongod绑定之类的操作,也说明了config server之间是相互独立的
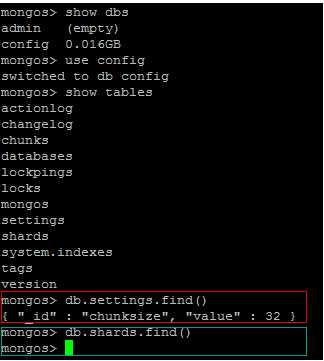
在上面截图蓝色框中可以看出,现在还没有任何shard的信息,原因是到现在为止,config servers与replica set还没有任何关系
mongos> sh.addShard(‘rs1/127.0.0.1:27018‘)
mongos> sh.addShard(‘rs2/127.0.0.1:27021‘)
PS:为什么需要在rs1后面指定一个mongod的ip port,这个是用来找到对应的mongod,继而找到相应rs
再次查看结果:

为了演示,我们假设添加一个db叫test_db, 其中有两个collection,一个是需要sharding的,叫sharded_col;另一个暂时不用sharding,叫non_sharded_col, 当然之后也可以增加新的集合,或者把原来没有sharding的集合改成sharding。
一下操作都需要登录到router进行: mongo --port $ROUTE_PORT
step1:首先得告知mongodb test_db这个数据库支持sharding
mongos> sh.enableSharding("test_db")
{ "ok" : 1 }
这个时候可以查看数据库的状态,注意,是在config这个db下面的databases集合
mongos> use config
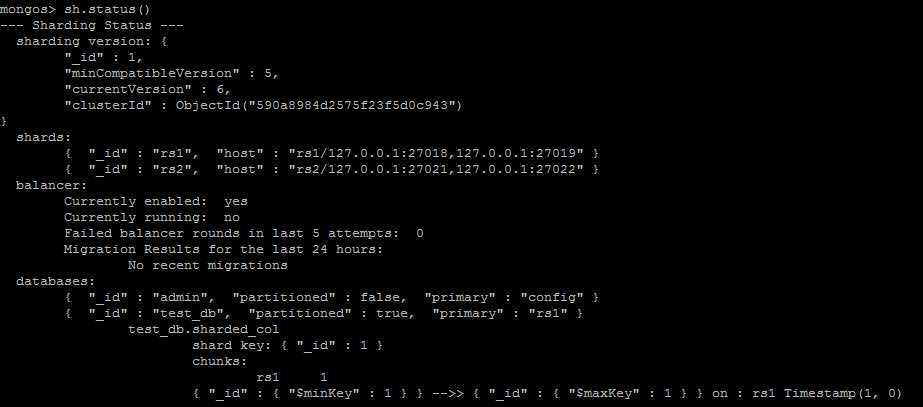
sh.status()反应的内容事实上也是来自config整个数据库的内容,只不过做了一定程度的整合。从上面可以看到,有两个shard,rs1, rs2;test_db允许sharding,test_db.sharded_col整个collection的sharding key为{"_id": 1},且目前只有一个chunk在rs1整个shard上。
到目前为止,我们已经搭建了一个有三个config server,两个shard的sharded cluster,其中每一个shard包含三个节点的replica set,且都包含一个Arbiter。我们可以查看一下刚创建好之后各个mongod实例持久化的数据大小:
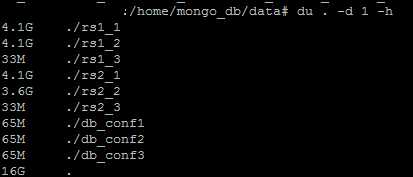
可以看到,两个Arbiter(rs1_3, rs2_3)所占的空间要小得多。
对于应用程序来说,集群(sharded cluster)和单点(standalone)是有一定差异的,如果需要发挥sharded cluster高性能、高可用的特点,需要根据应用场景精心选择好sharding key,而sharding key的选择跟索引的建立以及CRUD语句息息相关,这一部分以后再聊。对于目前搭建的这个实例,简单测试的话,往sharded_col插入足够多条document就能看到chunks的拆分和迁移。
references:
deploy-replica-set-for-testing
通过一步步创建sharded cluster来认识mongodb
标签:exist .sh migrate 分解 prim rate ide 应用 演示
原文地址:http://www.cnblogs.com/xybaby/p/6832296.html