标签:directory server 测试数据 groups html cat nbsp 格式 for
Flume是一个分布式的、高可用的海量日志收集、聚合和传输日志收集系统,支持在日志系统中定制各类数据发送方(如:Kafka,HDFS等),便于收集数据。其核心为agent,agent是一个java进程,运行在日志收集节点。
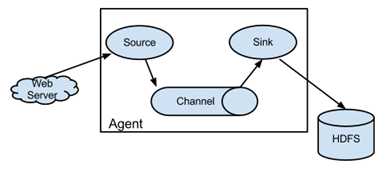
agent里面包含3个核心组件:source、channel、sink。
source组件是专用于收集日志的,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义,同时 source组件把数据收集
以后,临时存放在channel中。
channel组件是在agent中专用于临时存储数据的,可以存放在memory、jdbc、file、自定义等。channel中的数据只有在sink发送成功之后才会被删除。
sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
在整个数据传输过程中,流动的是event。事务保证是在event级别。flume可以支持多级flume的agent,支持扇入(fan-in)、扇出(fan-out)。
1)hadoop集群(楼主用的版本2.7.3,共6个节点,可参考http://www.cnblogs.com/qq503665965/p/6790580.html)
2)flume集群规划:
|
HOST |
作用 |
方式 |
路径 |
|
hadoop01 |
agent |
spooldir |
/home/hadoop/logs |
|
hadoop05 |
collector |
HDFS |
/logs |
|
hadoop06 |
collector |
HDFS |
/logs |
其基本结构官网给出了更加具体的说明,这里楼主就直接copy过来了:
1)系统环境变量配置
1 export FLUME_HOME=/home/hadoop/apache-flume-1.7.0-bin 2 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$FLUME_HOME/bin
记得 source /etc/profile 。
2)flume JDK环境
1 mv flume-env.sh.templete flume-env.sh 2 vim flume-env.sh 3 export JAVA_HOME=/usr/jdk1.7.0_60//增加JDK安装路径即可
3)hadoop01中flume配置
在conf目录增加配置文件 flume-client ,内容为:
1 #agent1名称 2 agent1.channels = c1 3 agent1.sources = r1 4 agent1.sinks = k1 k2 5 6 #sink组名称 7 agent1.sinkgroups = g1 8 9 #set channel 10 agent1.channels.c1.type = memory 11 agent1.channels.c1.capacity = 1000 12 agent1.channels.c1.transactionCapacity = 100 13 14 agent1.sources.r1.channels = c1 15 agent1.sources.r1.type = spooldir 16 #日志源 17 agent1.sources.r1.spoolDir =/home/hadoop/logs 18 19 agent1.sources.r1.interceptors = i1 i2 20 agent1.sources.r1.interceptors.i1.type = static 21 agent1.sources.r1.interceptors.i1.key = Type 22 agent1.sources.r1.interceptors.i1.value = LOGIN 23 agent1.sources.r1.interceptors.i2.type = timestamp 24 25 # 设置sink1 26 agent1.sinks.k1.channel = c1 27 agent1.sinks.k1.type = avro 28 #sink1所在主机 29 agent1.sinks.k1.hostname = hadoop05 30 agent1.sinks.k1.port = 52020 31 32 #设置sink2 33 agent1.sinks.k2.channel = c1 34 agent1.sinks.k2.type = avro 35 #sink2所在主机 36 agent1.sinks.k2.hostname = hadoop06 37 agent1.sinks.k2.port = 52020 38 39 #设置sink组包含sink1,sink2 40 agent1.sinkgroups.g1.sinks = k1 k2 41 42 #高可靠性 43 agent1.sinkgroups.g1.processor.type = failover 44 #设置优先级 45 agent1.sinkgroups.g1.processor.priority.k1 = 10 46 agent1.sinkgroups.g1.processor.priority.k2 = 1 47 agent1.sinkgroups.g1.processor.maxpenalty = 10000
4)hadoop05配置
1 #设置 Agent名称 2 a1.sources = r1 3 a1.channels = c1 4 a1.sinks = k1 5 6 #设置channlels 7 a1.channels.c1.type = memory 8 a1.channels.c1.capacity = 1000 9 a1.channels.c1.transactionCapacity = 100 10 11 # 当前节点信息 12 a1.sources.r1.type = avro 13 #绑定主机名 14 a1.sources.r1.bind = hadoop05 15 a1.sources.r1.port = 52020 16 a1.sources.r1.interceptors = i1 17 a1.sources.r1.interceptors.i1.type = static 18 a1.sources.r1.interceptors.i1.key = Collector 19 a1.sources.r1.interceptors.i1.value = hadoop05 20 a1.sources.r1.channels = c1 21 22 #sink的hdfs地址 23 a1.sinks.k1.type=hdfs 24 a1.sinks.k1.hdfs.path=/logs 25 a1.sinks.k1.hdfs.fileType=DataStream 26 a1.sinks.k1.hdfs.writeFormat=TEXT 27 #没1K产生文件 28 a1.sinks.k1.hdfs.rollInterval=1 29 a1.sinks.k1.channel=c1 30 #文件后缀 31 a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
5)hadoop06配置
1 #设置 Agent名称 2 a1.sources = r1 3 a1.channels = c1 4 a1.sinks = k1 5 6 #设置channel 7 a1.channels.c1.type = memory 8 a1.channels.c1.capacity = 1000 9 a1.channels.c1.transactionCapacity = 100 10 11 # 当前节点信息 12 a1.sources.r1.type = avro 13 #绑定主机名 14 a1.sources.r1.bind = hadoop06 15 a1.sources.r1.port = 52020 16 a1.sources.r1.interceptors = i1 17 a1.sources.r1.interceptors.i1.type = static 18 a1.sources.r1.interceptors.i1.key = Collector 19 a1.sources.r1.interceptors.i1.value = hadoop06 20 a1.sources.r1.channels = c1 21 #设置sink的hdfs地址目录 22 a1.sinks.k1.type=hdfs 23 a1.sinks.k1.hdfs.path=/logs 24 a1.sinks.k1.hdfs.fileType=DataStream 25 a1.sinks.k1.hdfs.writeFormat=TEXT 26 a1.sinks.k1.hdfs.rollInterval=1 27 a1.sinks.k1.channel=c1 28 a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
1)启动collector,即hadoop05,hadoop06
1 flume-ng agent -n a1 -c conf -f flume-server -Dflume.root.logger=DEBUG,console
2)启动agent,即hadoop01
flume-ng agent -n a1 -c conf -f flume-client -Dflume.root.logger=DEBUG,console
agent启动后,hadoop05,hadoop06的控制台可看到如下打印信息:

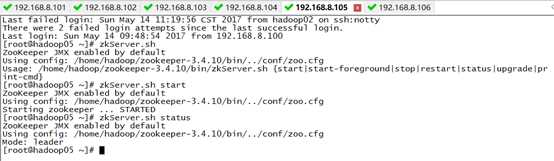
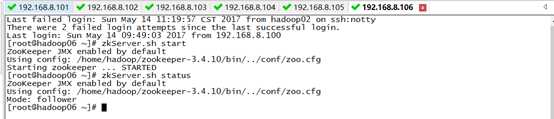
1)启动zookeeper集群(未搭建zookeeper的同学可以忽略)

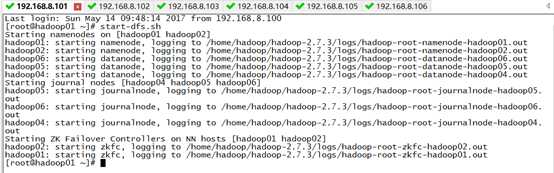
2)启动hdfs start-dfs.sh
3)模拟网站日志,楼主这里随便弄的测试数据
4)上传到/hadoop/home/logs
hadoop01输出:

hadoop05输出:

由于hadoop05设置的优先级高于hadoop06,因此hadoop06无日志写入。
我们再看hdfs上,是否成功上传了日志文件:
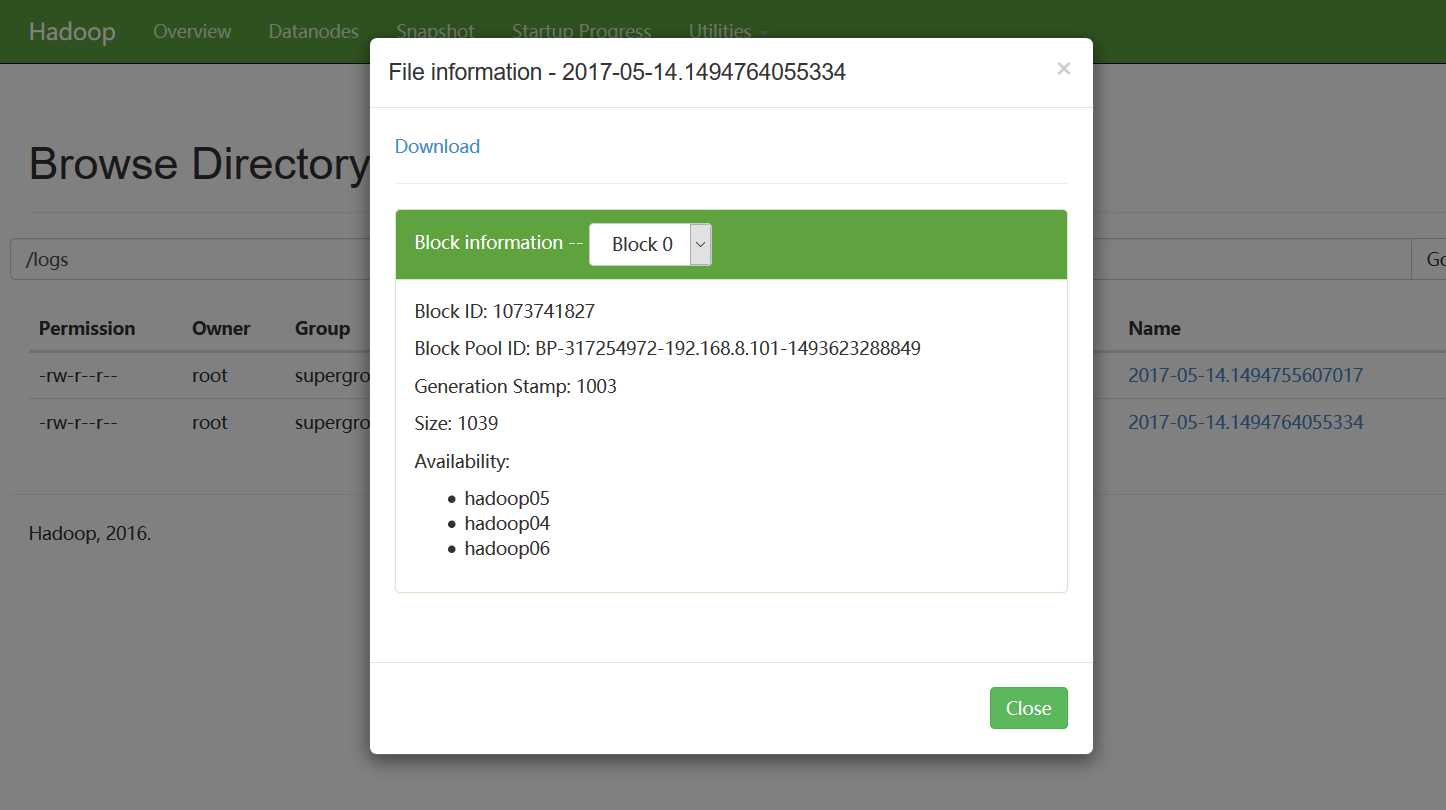
由于楼主设置的hadoop05的优先级要高于hadoop06,这也是上面的日志收集hadoop05输出而不是hadoop06输出的原因。现在我们干掉优先级高的hadoop05,看hadoop06是否能正常进行日志采集工作。
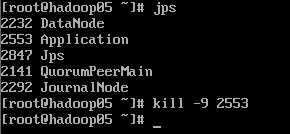

我们向日志源添加一个测试日志文件:

hadoop06输出:

查看hdfs:
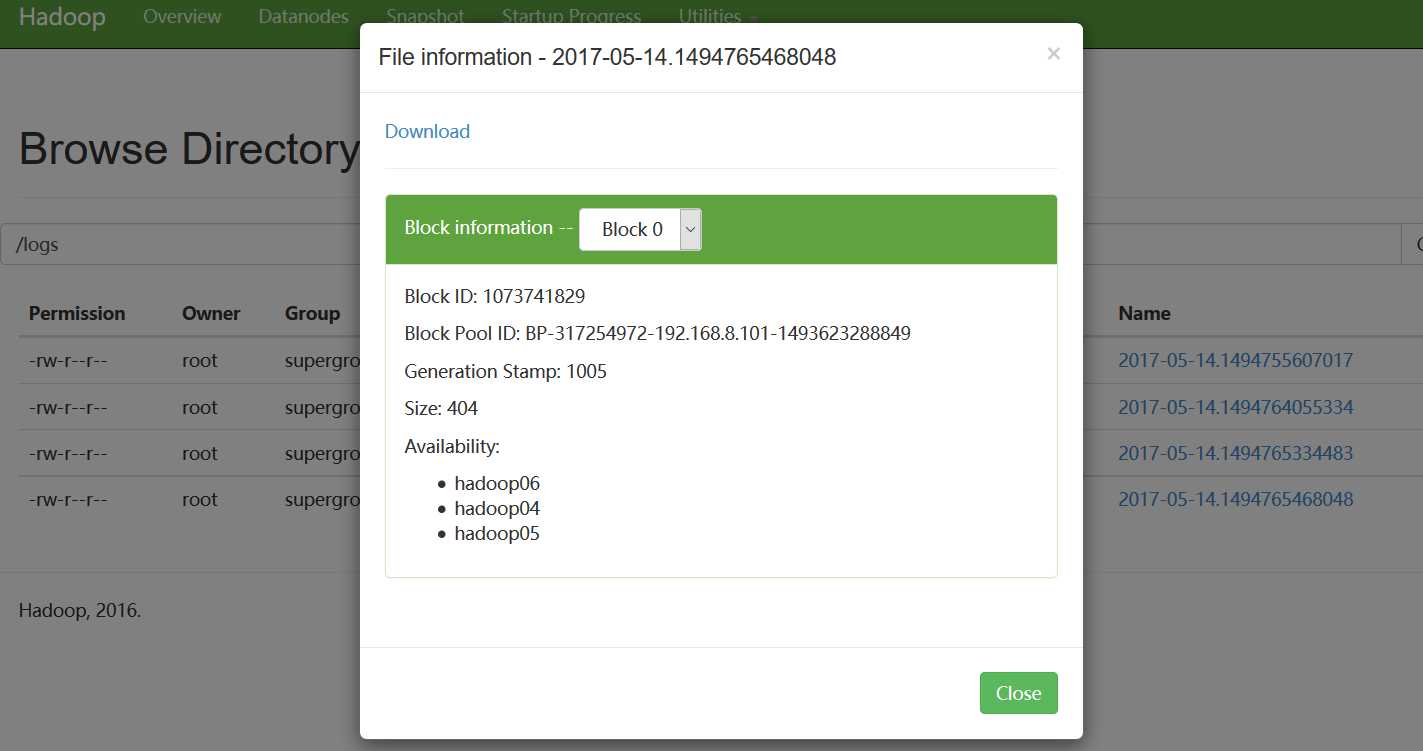
好了!flume集群配置及日志收集就介绍到这里,下次楼主楼主会具体介绍利用mapreduce对日志进行清洗,并存储到hbase相关的内容。
标签:directory server 测试数据 groups html cat nbsp 格式 for
原文地址:http://www.cnblogs.com/qq503665965/p/6853209.html