标签:images 生成 方法 阶段 https 分享 href question logs
关于beam search
之前组会中没讲清楚的 beam search,这里给一个案例来说明这种搜索算法。
在 Image Caption的测试阶段,为了得到输出的语句,一般会选用两种搜索方式,一种是贪心采样的方法(sample),即:每个时刻都选择输出概率最大的那个单词,作为当前时刻的输出。
另一种常用的搜索方法就是:beam search。此处,借用知乎的一个案例:
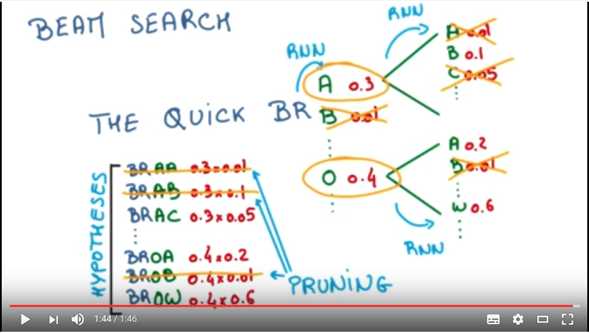
假设词表大小为3,内容为a,b,c。beam search size是2,那么在decoder解码的时候:
1: 生成第1个词的时候,选择概率最大的2个词,假设为a,c,那么当前序列就是a,c
2:生成第2个词的时候,我们将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa ab ac ca cb cc,然后从其中选择2个得分最高的,作为当前序列,假如为aa cb
3:后面会不断重复这个过程,直到遇到结束符为止。最终输出2个得分最高的序列。
这样,就可以根据一张图得到对应的2句描述,由于每一次都会有对应句子的总的概率输出乘积,也就可以选择一个最好的语句描述。下面是YouTube上关于该概念讲解的截图:
参考文献:
关于 Image Caption 中测试时用到的 beam search算法
标签:images 生成 方法 阶段 https 分享 href question logs
原文地址:http://www.cnblogs.com/wangxiaocvpr/p/6858950.html