标签:系统优化 use ble 单词 ifconfig 配置 字符串 写入 命令行
我们都知道,在Linux中一切皆文件,比如配置文件,日志文件,启动文件等等。如果我们相对这些文件进行一些编辑查询等操作时,我们可能会想到一些vi,vim,cat,more等命令。但是这些命令效率不高,这就好比一块空地准备搭建房子,请了10个师傅拿着铁锹挖地基,花了一个月的时间才挖完,而另外一块空地则请了个挖土机,三下五除二就搞定了,这就是效率。而在linux中的“挖土机”有三种型号:顶配awk,中配sed,标配grep。使用这些工具,我们能够在达到同样效果的前提下节省大量的重复性工作,提高效率。
sed 是Stream Editor(字符流编辑器)的缩写,简称流编辑器。什么是流?大家可以想象以下流水线,sed就像一个车间一样,文件中的每行字符都是原料,运到sed车间,然后经过一系列的加工处理,最后从流水线下来就变成货物了。
编辑文件也是这样,以前我们修改一个配置文件,需要移动光标到某一行,然后添加点文字,然后又移动光标到另一行,注释点东西.......可能修改一个配置文件下来需要花费数十分钟,还有可能改错了配置文件,又得返工。这还是一个配置文件,如果数十个数百个呢?因此当你学会了sed命令,你会发现利用它处理文件中的一系列修改是很有用的。只要想到在大约100多个文件中,处理20个不同的编辑操作可以在几分钟之内完成,你就会知道sed的强大了。
Sed命令是操作,过滤和转换文本内容的强大工具。常用功能有增删改查(增加,删除,修改,查询),其中查询的功能中最常用的2大功能是过滤(过滤指定字符串),取行(取出指定行)。
我们现在准备学习的sed版本是GNU开源版本
[root@chengliang mail]# sed --version GNU sed version 4.2.1
Sed软件从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行....
一次一行的设计使得sed软件性能很高,sed在读取非常庞大的文件时不会出现卡顿的想象。大家都用过vi命令,用vi命令打开几十M或更大的文件,会发现有卡顿现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开,因此卡顿的时间长短就取决于从磁盘到内存的读取速度了。而且如果文件过大的话还会造成内存溢出现象。Sed软件就很好的避免了这种情况,打开速度非常快,执行速度也很快。
现有一个文件person.txt,共有五行文本,sed命令读入文件person.txt的第一行“101,chensiqi,CEO”,并将这行文本存入模式空间(sed软件在内存中的一个临时缓存,用于存放读取到的内容,比喻为工厂流水线的传送带。)
文件person.txt在模式空间的完整处理流程
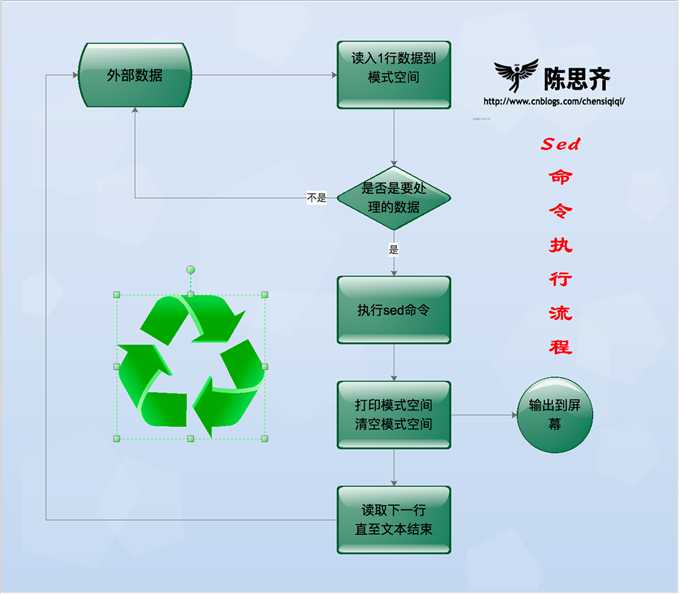
Sed软件有两个内置的存储空间:
[root@chengliang zcl]# cat zcl.txt [root@chengliang zcl]# cat > zcl.txt <<KOF > 101,chengliang,aa > 102,alex,bb > 103,eric,cc > 104,laonanhai,dd > KOF [root@chengliang zcl]# cat zcl.txt 101,chengliang,aa 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
KOF必须成对出现,表示终止输入
命令说明:使用一条cat命令创建多行文本,文件包含上面的内容,后面的操作都会使用这个文件。
1、增
比如我们平时往配置文件写入几行文本,最常用的是vi或vim命令,但是这2个命令是一种交互式的命令,还需要我们在vi/vim编辑器界面输入字符串然后保存退出,操作有些繁琐但是还能用。但是当我们学会了Shell脚本后,我们就会发现在脚本中不能正常使用vi或vim命令,为什么呢?同学们请自行体验。
这里我们需要用到2个sed命令,分别是:
在文件中增加一行文本,我们以前学过echo命令可以在文件的末尾追加文本,比较简单,但是我们还有其他的复杂需求,比如在第10行插入一行数字等等,这里就需要sed出马了。
[root@chengliang zcl]# sed "2a hahaha" zcl.txt 101,chengliang,aa 102,alex,bb hahaha #新增的那句 103,eric,cc 104,laonanhai,dd
sed使用的过程中用单引号还是双引号?这里给大家详细说说引号的区别。
[root@chengliang zcl]# cat zcl.txt 101,chengliang,aa 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# sed ‘2i $PATH‘ zcl.txt #单引号--文本内容原封不动插入 101,chengliang,aa $PATH 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# sed "2i $PATH" zcl.txt #双引号--变量$PATH被解析以后在当作文本进行插入 101,chengliang,aa /application/mysql/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# sed 2i $PATH zcl.txt #不加引号,linux无法辨认空格,不会把有空格的命令当成一条命令来执行 sed: -e expression #1, char 2: expected \ after `a‘, `c‘ or `i‘ [root@chengliang zcl]#
总结:
-e enable interpretation of backslash escapes //启用反斜杠转义解释
[root@chengliang zcl]# echo "zcl";echo "zcl" zcl zcl [root@chengliang zcl]# echo "zcl\nzcl" zcl\nzcl [root@chengliang zcl]# echo -e "zcl\nzcl" zcl zcl [root@chengliang zcl]#
命令说明:这里就“\n”派上用场了,行与行之间是以“\n”作为分隔符的,所以“chensiqi\nchensiqi”就等效于2行chensiqi。接下来我们用echo命令实验一下,其中-e参数表示字符串中如果出现以下特殊字符(\n代表换行,\t代表Tab键等),则加以特殊处理,而不会将它当成一般文字输出。
[root@chengliang zcl]# sed "2a wawawa\nhahaha" zcl.txt 101,chengliang,aa 102,alex,bb wawawa hahaha 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
当然还有另外一种方法添加多行文本,但这种方法并没有“\n”方便,所以在这里就简单说一下。这种方法利用了“\”,它也有换行的意思。如果大家在执行一行很长的命令时候,如果都写在一行,那太难看了也难以理解,因此就利用到了这个符号可以将一条完整的命令分成多行,举个例子:
[root@chengliang zcl]# echo my \ > name> is > zcl my nameis zcl [root@chengliang zcl]#
sed命令使用反斜线,首先输入完“sed ‘2a 106,dandan,CSO \”,然后敲回车键,这样窗口会显示一个符号“>”,我们在这个符号后面接着写命令的剩余部分“107,bingbing,CCO‘ person.txt”。
[root@chengliang zcl]# sed ‘2a 106,dandan,CSO > 107,bingibng,CCO‘ \ > zcl.txt 101,chengliang,aa 102,alex,bb 106,dandan,CSO 107,bingibng,CCO 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
sed软件使用命令i插入多行文本和命令和a的用法是一样的,因此这里不再详细列出,大家可以练习一下
在我们学习CentOS6系统优化时,有一个优化点:更改ssh服务远程登录的配置。主要的操作是在ssh的配置文件/etc/ssh/sshd_config加入下面5行文本。
Port 52113 #ssh服务端口 PermitRootLogin no #不允许root远程登陆 PermitEmptyPasswords no #不允许密码为空 UseDNS no GSSAPIAuthentication no
当然我们可以使用vi/vim命令编辑这个文本,但是这样就比较麻烦,现在想用一条命令增加5行文本到第13行前?
[root@chengliang ~]# sed -i ‘13i Port 52113\nPermitRootLogin no\nPermitEmptyPasswords no\nUseDNS no\nGSSAPIAuthentication no‘ /etc/ssh/sshd_config 命令说明:题目要求在第13行前插入,那就需要使用命令13i。有同学做个题目时,是这样想的,在13行前,那不就是12行后吗,12a也是可以的。是的,这样也是没错的,这可以算是第二种方法。 最后插入的5行内容使用“\n”就可以变成一行了。 上面还有一个没讲过的选项"-i",这个选项能够实际的修改文件内容,大家练习时可以去掉,防止改掉了配置文件。如果使用了-i,可以用备份文件还原。当然,在生产环境修改配置文件那就需要用-i选项了。 [root@chensiqi1 ~]# sed -n ‘13,17p‘ /etc/ssh/sshd_config Port 52113 PermitRootLogin no PermitEmptyPasswords no UseDNS no GSSAPIAuthentication no
| 地址范围 | 含义 |
|---|---|
| 10{sed-commands} | 对第10行操作 |
| 10,20{sed-commands} | 对10到20行操作,包括第10,20行 |
| 10,+20{sed-commands} | 对10到30(10+20)行操作,包括第10,30行 |
| 1~2{sed-commands} | 对1,3,5,7.....行操作 |
| 10,\${sed-commands} | 对10到最后一行($代表最后一行)操作,包括第10行 |
| /chensiqi/{sed-commands} | 对匹配chensiqi的行操作 |
| /chensiqi/,/Alex/{sed-commands} | 对匹配chensiqi的行到匹配Alex的行操作 |
| /chensiqi/,\${sed-commands} | 对匹配chensiqi的行到最后一行操作 |
| /chensiqi/,10{sed-commands} | 对匹配chensiqi的行到第10行操作,注意:如果前10行没有匹配到chensiqi,sed软件会显示10行以后的匹配chensiqi的行 |
| 1,/Alex/{sed-commands} | 对第1行到匹配Alex的行操作 |
| /chensiqi/,+2{sed-commands} | 对匹配chensiqi的行到其后的2行操作 |
如果在sed命令前面不指定地址范围,那么默认会匹配所有行,然后使用d命令删除功能就会删除这个文件的所有内容
[root@chengliang zcl]# cat test.txt welcome to my blog:http://www.cnblogs.com/0zcl if you like my blog\‘s contents,please support me! bye! boys and girls. [root@chengliang zcl]# sed "d" test.txt [root@chengliang zcl]#
单行删除想必大家能理解,指定删除第2行的文本102,alex,bb
[root@chengliang zcl]# sed "2d" zcl.txt 101,chengliang,aa 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
"2,3d" 指定删除第2行到第3行的内容,d代表删除操作。
[root@chengliang zcl]# sed "2,3d" zcl.txt 101,chengliang,aa 104,laonanhai,dd [root@chengliang zcl]#
上面我们实验完了数字地址范围,接下来我们实验一下正则表达式的地址范围,虽然说可以使用正则表达式,但是我们还是习惯写出完整的匹配字符串,达到精确匹配的目的。
在sed软件中,使用正则的格式和awk一样,使用2个”/“包含指定的正则表达式,即“/正则表达式/”。"/alex/d"有哪一行有alex则删除这一行。
[root@chengliang zcl]# sed "/alex/d" zcl.txt 101,chengliang,aa 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
这是正则表达式形式的多行删除,也是以逗号分隔2个地址,最后结果是删除包含“alex”的行到包含“eric”的行
[root@chengliang zcl]# sed "/alex/,/eric/d" zcl.txt 101,chengliang,aa 104,laonanhai,dd [root@chengliang zcl]#
学过正则表达式后我们知道“$”代表行尾,但是在sed中就有一些变化了,“$”在sed中代表文件的最后一行。因此本例子的含义是删除第2行到最后一行的文本,包含第2行和最后一行,因此只剩下第1行的内容。
[root@chengliang zcl]# sed "2,$d" zcl.txt sed: -e expression #1, char 2: unexpected `,‘ [root@chengliang zcl]# sed "2,\$d" zcl.txt 101,chengliang,aa [root@chengliang zcl]# sed ‘2,$d‘ zcl.txt 101,chengliang,aa [root@chengliang zcl]#
在工作中我们最常用的还是数字地址这种精确匹配方式,像上面的正则地址或混合地址这种模糊匹配用的比较少,了解即可。
具体可参考: http://www.cnblogs.com/chensiqiqi/p/6382080.html
格式:“First~step”表示从开始,以步长step递增,这个在数学中叫做等差数列
例子:
[root@chengliang zcl]# seq 10 1 2 3 4 5 6 7 8 9 10 [root@chengliang zcl]# seq 10 | sed -n "1~2p" 1 3 5 7 9 [root@chengliang zcl]#
命令说明:seq命令能够生成从1到10的数字序列
命令说明:上面的命令主要验证特殊符号“~”的效果,其他sed命令用法n和p请见后文详解,大家只需要知道这个命令可以将“1~2”指定的行显示出来即可。
如果大家想生成奇数数列,其实上面的方法是为了举例,并不是一个很好的方法,因为seq命令自带这种功能。
[root@chengliang zcl]# seq 1 2 10 1 3 5 7 9 [root@chengliang zcl]#
命令说明:seq命令格式seq起始值 公差 结束值
[root@chengliang zcl]# sed "1~2d" zcl.txt 102,alex,bb 104,laonanhai,dd [root@chengliang zcl]# sed "1,+2d" zcl.txt 104,laonanhai,dd [root@chengliang zcl]#
命令说明:“1~2”这是指定行数的另一种格式,从第1行开始以步长2递增的行(1,3,5),因此删掉第1,3,5行,即所有的奇数行。
命令说明:这其实是做个加法运算,‘1,+2d’==>删除第1行到第3(1+2)行的文本。
[root@chengliang zcl]# sed ‘2,3!d‘ zcl.txt 102,alex,bb 103,eric,cc [root@chengliang zcl]#
命令说明:在地址范围“2,3”后面加上“ !”,如果不加“!”表示删除第2行和第3行,结果如下面的例子所示,然后加上“!”的结果就是除了第2行和第3行以外的内容都删除,这个方法可以作为显示文件的第2,3行题目的补充方法。
按行替换,这个功能用的很少,所以大家了解即可。这里用到的sed命令是:
“c”:用新行取代旧行,记忆方法:c的全拼是change,意思是替换。
[root@chengliang zcl]# sed "2c wahaha" zcl.txt 101,chengliang,aa wahaha 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
命令说明:使用sed命令c将原来第2行 “102,alex,bb” 替换成 “wahaha” , 整行替换
有工作经验的同学应该非常的熟悉,因为使用sed软件80%的场景就是使用替换功能。
这里用到的sed命令,选项:(重要)
sed软件替换模型 ===> sed -i ‘s#目标内容#替换内容#g‘
结果为第二行的“bb”替换为“i am bb”。
[root@chengliang zcl]# sed "s#bb#i am bb#g" zcl.txt 101,chengliang,aa 102,alex,i am bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
[root@chensiqi1 ~]
[root@chengliang zcl]# sed "3s#0#9#" zcl.txt 101,chengliang,aa 102,alex,bb 193,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
命令说明: 前面学习的例子在sed命令“s”前没有指定地址范围,因此默认是对所有行进行操作。 而这个案例要求只将第3行的0换成9,这里就用到了我们前面学过的地址范围知识,在sed命令“s”前加上“3”就代表对第3行进行替换
变量替换其实和前面的文本替换是一样的,就是具体的文本变成了变量,同时要求大家对引号的用法要有清晰的理解.
[root@chengliang zcl]# cat > person.txt<<KOF > a > b > a > KOF [root@chengliang zcl]# cat person.txt a b a [root@chengliang zcl]# x=a [root@chengliang zcl]# y=b [root@chengliang zcl]# echo $x ##-->设置变量x并 赋值a a [root@chengliang zcl]# echo $b [root@chengliang zcl]# echo $y b [root@chengliang zcl]#
不使用引号
[root@chengliang zcl]# sed s#$x#$y#g person.txt
b
b
b
[root@chengliang zcl]# sed ‘s#‘$x‘#‘$y‘#g‘ person.txt
b
b
b
[root@chengliang zcl]# sed ‘s#$x#$y#g‘ person.txt
a
b
a
[root@chengliang zcl]#
命令说明:表面看起来单引号是可以用的,但其实这里用了障眼法,在你们眼中分段‘$x’和‘$y‘,但其实分段是‘s#’和‘#’和‘#g’,所以$x和$y并没有被引号扩起来,和上面的例子就一样了。
使用eval命令:
[root@chengliang zcl]# sed ‘s#$x#$y#g‘ person.txt a b a [root@chengliang zcl]# eval sed ‘s#$x#$y#g‘ person.txt b b b [root@chengliang zcl]#
命令说明:这里给大家扩展一个Linux内置命令eval,这个命令能读入变量,并将他们组合成一个新的命令,然后执行。首先eval会解析变量$x和变量$y,最后达到的效果和双引号是一样的
拓展: 最快速的获取IP地址的方法
[root@chengliang zcl]# hostname -I 192.168.179.133 [root@chengliang zcl]#
sed软件的()的功能可以记住正则表达式的一部分,其中,\1为第一个记住的模式即第一个小括号中的匹配内容,\2第二个记住的模式,即第二个小括号中的匹配内容,sed最多可以记住9个。
例:echo "I am chensiqi teacher." 如果想保留这一行的单词chengliang,删除剩下部分,使用圆括号标记想保留的部分。
[root@chengliang zcl]# echo "I am chengliang student." | sed ‘s#^.*am \([a-z]\+\) stu.*$#\1#g‘ chengliang [root@chengliang zcl]# echo "I am chengliang student." | sed -r ‘s#^.*am ([a-z]+) stu.*$#\1#g‘ chengliang [root@chengliang zcl]# echo "I am chengliang student." | sed -r ‘s#I (.*) (.*) stu.*$#\1#g‘ am [root@chengliang zcl]# echo "I am chengliang student." | sed -r ‘s#I (.*) (.*) stu.*$#\1\2#g‘ amchengliang [root@chengliang zcl]#
再来看个题目:请执行命令取出linux中的eth0的IP地址?
[root@chensiqi1 ~]# ifconfig eth0 | sed -n ‘2p‘
inet addr:192.168.197.133 Bcast:192.168.197.255 Mask:255.255.255.0
[root@chensiqi1 ~]# ifconfig eth0 | sed -n ‘2p‘ | sed -r ‘s#^.*addr:(.*) Bcast:.*$#\1#g‘
192.168.197.133
也可以进行组合
[root@chensiqi1 ~]# ifconfig eth0 | sed -rn ‘2s#^.*addr:(.*) Bcast:.*$#\1#gp‘
192.168.197.133
命令说明:
这道题是需要把ifconfig eth0执行结果的第2行的IP地址取出来,上面答案的思路是用IP地址来替换第2行的内容。
这是一个特殊技巧,在适合的场景使用特别方便。下面用特殊符号“&”与分组替换一起使用,进行对比。
[root@chengliang zcl]# cat zcl.txt 101,chengliang,aa 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# sed -r ‘s#(.*),(.*),(.*)#& ----- \1 \2 \3#‘ zcl.txt 101,chengliang,aa ----- 101 chengliang aa 102,alex,bb ----- 102 alex bb 103,eric,cc ----- 103 eric cc 104,laonanhai,dd ----- 104 laonanhai dd [root@chengliang zcl]#
上面命令的&符号代表每一行,即模型中‘s#目标内容#替换内容#g’的目标内容。
当前目录下有文件如下所示:
[root@chengliang test_1]# find ./ -name "*_finished.jpg" ./stu_102999_4_finished.jpg ./stu_102999_1_finished.jpg ./stu_102999_5_finished.jpg ./stu_102999_3_finished.jpg ./stu_102999_2_finished.jpg [root@chengliang test_1]#
要求用sed命令重命名,效果为:
stu_102999_1_finished.jpg==>stu_102999_1.jpg,即删除文件名的_finished
mv - move (rename) files
解题思路:因为这是文件名,不能直接yongsed命令替换,因此还需要借助mv命令重命名
格式为:mv stu_102999_1_finished.jpg stu_102999_1.jpg. 我们需要拼凑这样的格式,然后使用bash命令执行即可。
[root@chengliang test_1]# find ./ -name "*_finished.jpg" | sed -r ‘s#^(.*)_finished(.*)#\1\2#g‘ ./stu_102999_4.jpg ./stu_102999_1.jpg ./stu_102999_5.jpg ./stu_102999_3.jpg ./stu_102999_2.jpg [root@chengliang test_1]# find ./ -name "*_finished.jpg" | sed -r ‘s#^(.*)_finished(.*)#mv & \1\2#g‘ mv ./stu_102999_4_finished.jpg ./stu_102999_4.jpg mv ./stu_102999_1_finished.jpg ./stu_102999_1.jpg mv ./stu_102999_5_finished.jpg ./stu_102999_5.jpg mv ./stu_102999_3_finished.jpg ./stu_102999_3.jpg mv ./stu_102999_2_finished.jpg ./stu_102999_2.jpg [root@chengliang test_1]# find ./ -name "*_finished.jpg" | sed -r ‘s#^(.*)_finished(.*)#mv & \1\2#g‘ | bash [root@chengliang test_1]# ls stu_102999_1.jpg stu_102999_2.jpg stu_102999_3.jpg stu_102999_4.jpg stu_102999_5.jpg [root@chengliang test_1]#
命令说明:
我们想查看文件中的某些行,以前最常用的是cat或more或less命令等,但这些命令有些缺点,就是不能查看指定的行。而我们用了很久的sed命令就有了这个功能了。而且我们前面也说过使用sed比其他命令vim等读取速度更快!
“p”:输出指定内容,但默认会输出2次匹配的结果,因此使用-n选项取消默认输出,记忆方法:p的全拼是print,意思是打印。
按行查询
[root@chengliang zcl]# sed "2p" zcl.txt 101,chengliang,aa 102,alex,bb 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# sed -n "2p" zcl.txt 102,alex,bb [root@chengliang zcl]# 命令说明:选项-n取消默认输出,只输出匹配的文本,大家只需要记住使用命令p必用选项-n。 [root@chengliang zcl]# sed -n "2,3p" zcl.txt 102,alex,bb 103,eric,cc [root@chengliang zcl]# 命令说明:查看文件的第2行到3行,使用地址范围“2,3”。取行就用sed,最简单 [root@chengliang zcl]# sed -n "1~2p" zcl.txt 101,chengliang,aa 103,eric,cc 命令说明:打印文件的1,3,5行。~代表步长 [root@chengliang zcl]# sed -n "p" zcl.txt 101,chengliang,aa 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# 命令说明:不指定地址范围,默认打印全部内容。
按字符串查询
[root@chengliang zcl]# sed -n "/alex/p" zcl.txt ==>命令说明:打印含CTO的行 102,alex,bb [root@chengliang zcl]# [root@chengliang zcl]# sed -n "/alex/,/chengliang/p" zcl.txt 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# sed -n "/alex/,/eric/p" zcl.txt ==>命令说明:打印含alex的行到含eric的行 102,alex,bb 103,eric,cc [root@chengliang zcl]#
混合查询
[root@chengliang zcl]# sed -n "2, /cc/p" zcl.txt 102,alex,bb 103,eric,cc 命令说明:打印第2行到含cc的行。 [root@chengliang zcl]# sed -n "/cc/,2p" zcl.txt 103,eric,cc [root@chengliang zcl]# 命令说明:特殊情况,前两行没有匹配到cc,就向后匹配,如果匹配到cc就打印此行。所以这种混合地址不推荐使用。
过滤多个字符
[root@chengliang zcl]# sed -rn "/alex|cc/p" zcl.txt 102,alex,bb 103,eric,cc [root@chengliang zcl]#
命令说明: 使用扩展正则“|”,为了不使用转义符号“\”,因此使用-r选项开启扩展正则表达式模式
[root@chengliang zcl]# ls a a.bak ac ae ae.bak afff person.txt test.txt test_1 zcl.txt [root@chengliang zcl]# sed -i.bak "s#chengliang#Fuck#g" zcl.txt [root@chengliang zcl]# ls a a.bak ac ae ae.bak afff person.txt test.txt test_1 zcl.txt zcl.txt.bak [root@chengliang zcl]# cat zcl.txt 101,Fuck,aa 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]# cat zcl.txt.bak 101,chengliang,aa 102,alex,bb 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
命令行说明: 在-i参数的后边加上.bak(.任意字符),sed会对文件进行先备份后修改
[root@chengliang zcl]# sed ‘=‘ zcl.txt 1 101,Fuck,aa 2 102,alex,bb 3 103,eric,cc 4 104,laonanhai,dd 命令说明:使用特殊符号“=”就可以获取文件的行号,这是特殊用法,记住即可。从上面的命令结果我们也发现了一个不好的地方:行号和行不在一行。 [root@chengliang zcl]# sed ‘1,3=‘ zcl.txt 1 101,Fuck,aa 2 102,alex,bb 3 103,eric,cc 104,laonanhai,dd 命令说明:只打印1,2,3行的行号,同时打印输出文件中的内容 [root@chengliang zcl]# [root@chengliang zcl]# sed ‘/alex/=‘ zcl.txt 101,Fuck,aa 2 102,alex,bb 103,eric,cc 104,laonanhai,dd 命令说明:只打印正则匹配行的行号,同时输出文件中的内容 [root@chengliang zcl]# sed -n ‘/alex/=‘ zcl.txt 2 命令说明:只显示行号但不显示行的内容即取消默认输出 [root@chengliang zcl]# sed -n ‘$=‘ zcl.txt 4 [root@chengliang zcl]# 命令说明:“$”代表最后一行,因此显示最后一行的行号,变相得出文件的总行数。
方法改进:
[root@chengliang zcl]# sed ‘=‘ zcl.txt | sed ‘N;s#\n# #‘ 1 101,Fuck,aa 2 102,alex,bb 3 103,eric,cc 4 104,laonanhai,dd [root@chengliang zcl]#
sed如何取不连续的行
[root@chengliang zcl]# sed -n "1p;3p;4p" zcl.txt 101,Fuck,aa 103,eric,cc 104,laonanhai,dd [root@chengliang zcl]#
特殊符号{}的使用
[root@chengliang zcl]# sed -n ‘2,3p;=‘ zcl.txt
1
102,alex,bb
2
103,eric,cc
3
4
[root@chengliang zcl]# sed -n ‘2,3{p;=}‘ zcl.txt
102,alex,bb
2
103,eric,cc
3
[root@chengliang zcl]#
参考博客: http://www.cnblogs.com/chensiqiqi/p/6382080.html
标签:系统优化 use ble 单词 ifconfig 配置 字符串 写入 命令行
原文地址:http://www.cnblogs.com/0zcl/p/6855740.html