标签:字段 算法 启动 技术分享 运用 lis arch 基于 同名
概念:Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。Apache Solr 中存储的资源是以 Document 为对象进行存储的。每个文档由一系列的 Field 构成,每个 Field 表示资源的一个属性。Solr 中的每个 Document 需要有能唯一标识其自身的属性,默认情况下这个属性的名字是 id,在 Schema 配置文件中使用:<uniqueKey>id</uniqueKey>进行描述。
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。Solr是一个独立的企业级搜索应用服务器,目前很多企业运用solr开源服务。原理大致是文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
安装配置以及程序插入与查询
1、启动solr
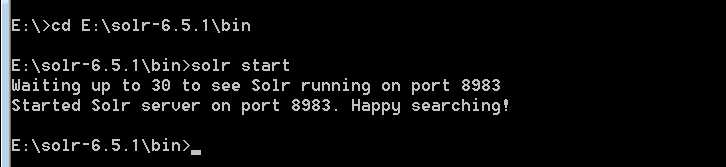
命令行窗口进入安装目录的bin下,直接使用solr start启动,不加参数默认使用8983端口
2、访问solr控制台
进入solr的控制台。
solr的工作核心名词为core,可以理解成数据库的表。 每个core都有自己的schema,可对应理解为数据库的字段。
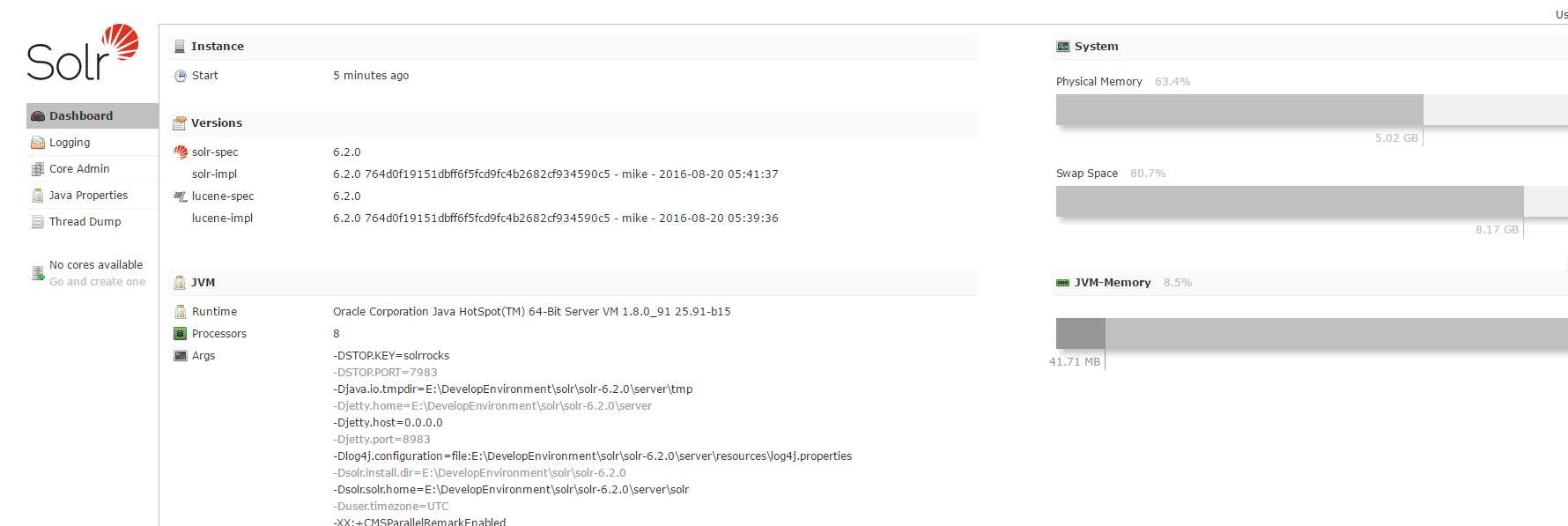
控制台如下图所示。
当前是没有core文件的,需要我们自己配置。
3、配置core
配置我们自己的core。
在控制台的左边菜单中,选择Core Admin,进入core新建页面。
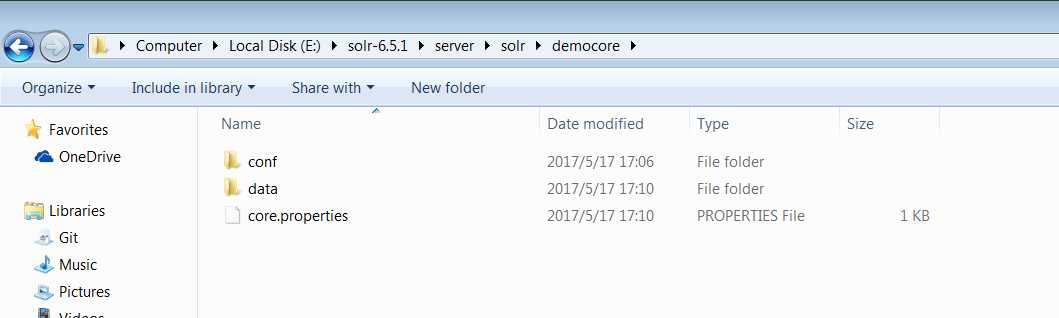
在点击Add Core 保存之前, 先进入solr的安装目录的 server - solr 下 新建一个和core同名的文件夹,如:
进入E:\DevelopEnvironment\solr\solr-6.2.0\server\solr 新建 democore 。
文件夹建好后,进入solr目录的 server\solr\configsets\basic_configs 下,拷贝conf文件夹到新建的文件夹下
如:进入E:\DevelopEnvironment\solr\solr-6.2.0\server\solr\configsets\basic_configs 拷贝conf文件夹到刚刚新建的democore
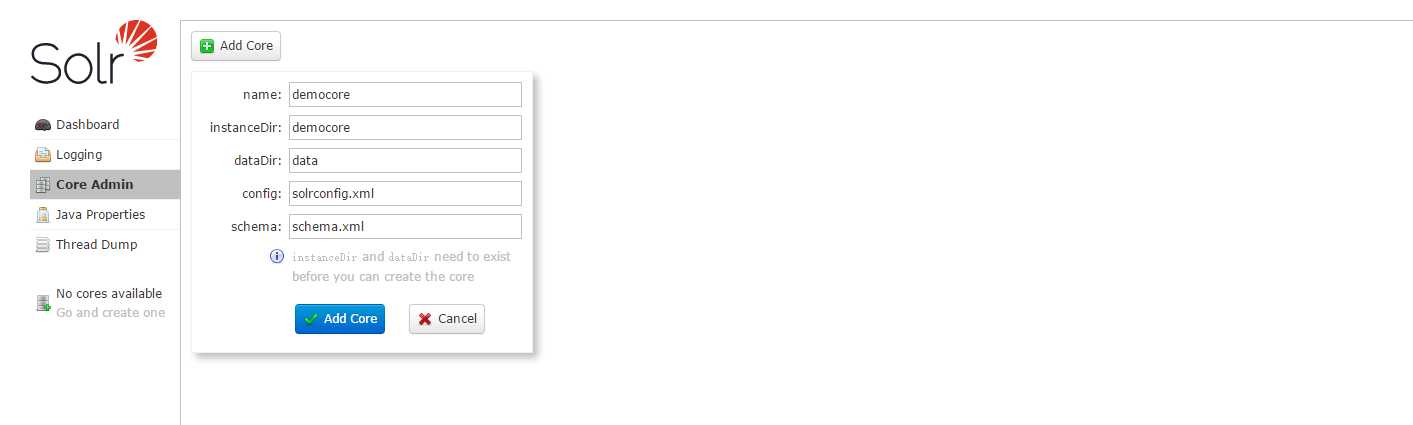
完成这一步准备工作后,回到控制台的Core Admin 录入name和dir 点击 Add Core 保存即可
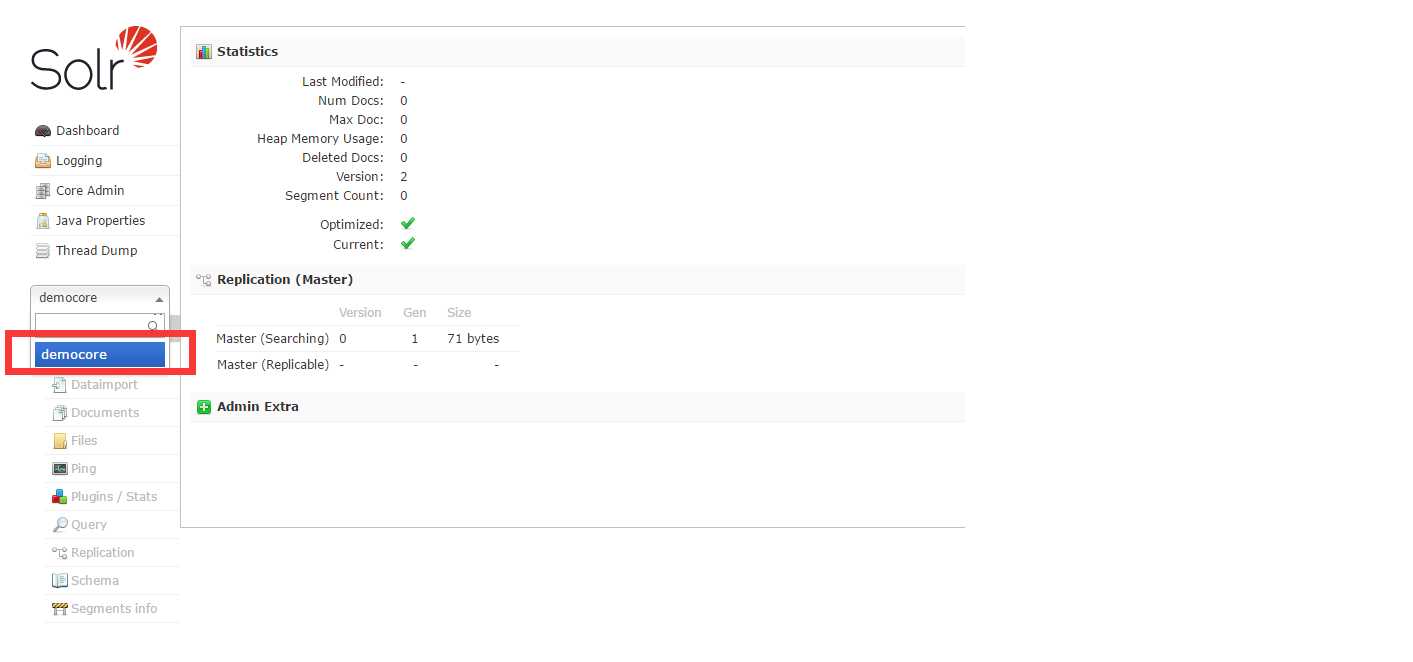
保存完成后,可看到该core:
对应的文件夹内容也改变为:
4、新建schema
core文件创建完成后,创建其对应的schema。
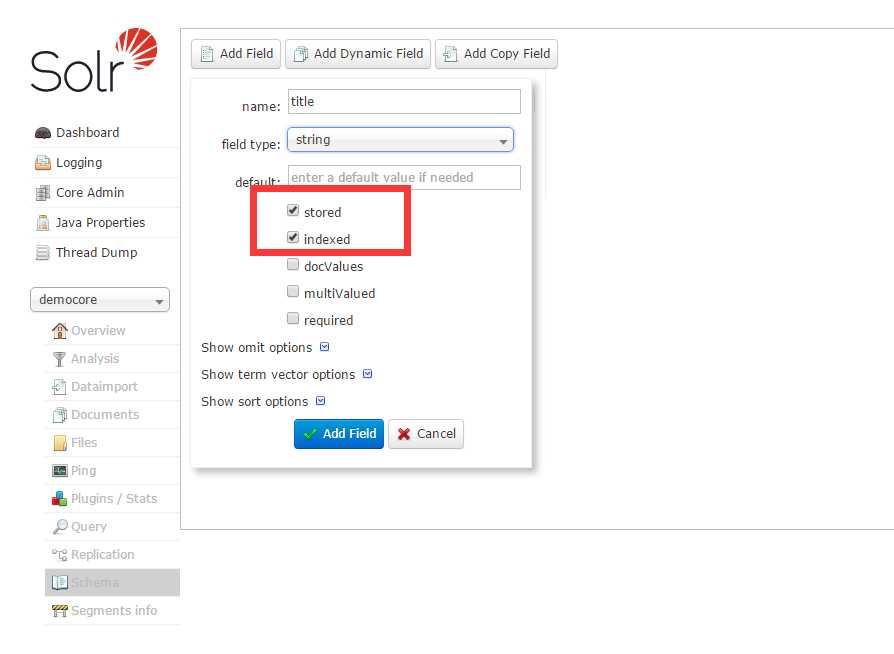
进入该core的Schema 菜单 ,点击Add Field ,在弹出的页面中,录入name和type,name代表字段的名称,type为类型 ,类型选择 text_general。
stored 意思为,将该字段的值进行存储,用来以后索引的时候直接取出。
indexed 表示 将该字段进行索引。
录入完成后,点击Add Field保存即可。
至此,core和schema都构建完成。接下来要向solr的这个core插入数据。
5、使用程序插入数据
新建Java项目,将solr的对应jar包拷贝到项目中。
使用到的jar包在 dist 文件夹下,主要包括 solrj这个jar包和solr-lib下的jar包,为了方便,直接全部拷贝过去即可。
如:E:\solr-6.5.1\dist E:\solr-6.5.1\dist\solrj-lib
以及运行程序插入程序
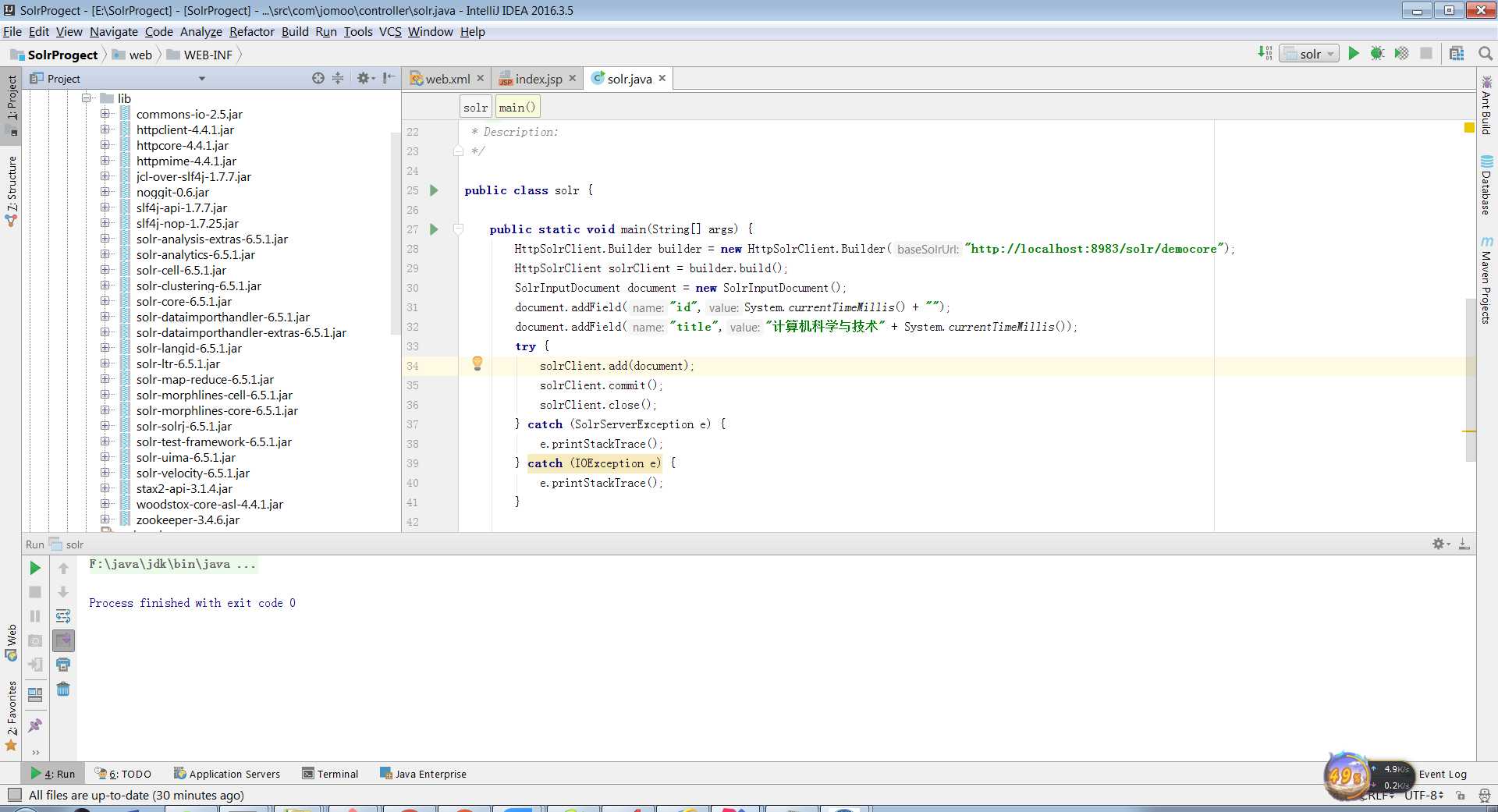
HttpSolrClient.Builder builder = new HttpSolrClient.Builder("http://localhost:8983/solr/democore");
HttpSolrClient solrClient = builder.build();
SolrInputDocument document = new SolrInputDocument();
document.addField("id", System.currentTimeMillis() + "");
document.addField("title", "计算机科学与技术" + System.currentTimeMillis());
solrClient.add(document);
solrClient.commit();
solrClient.close();
6、使用程序查询数据
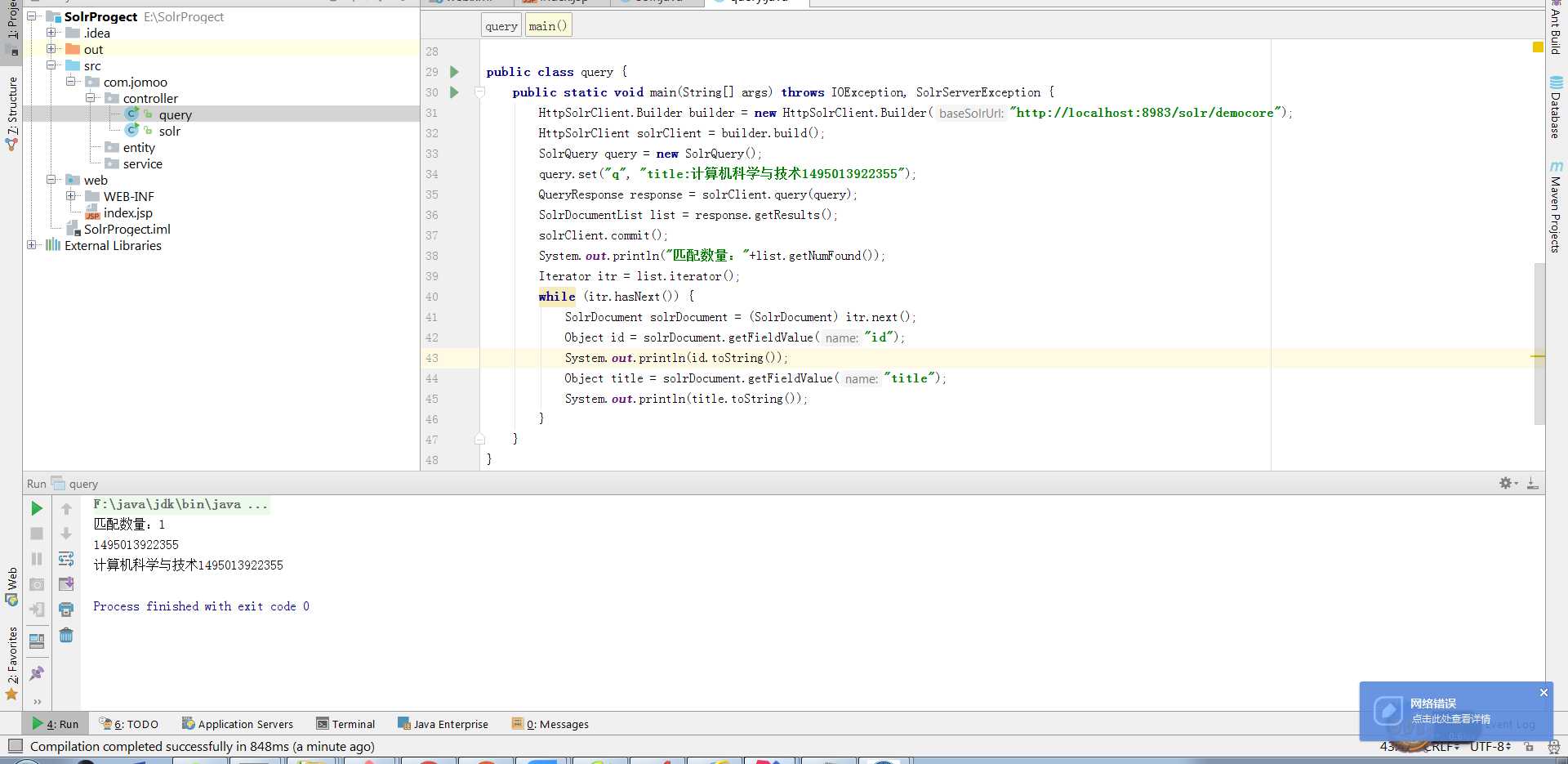
HttpSolrClient.Builder builder = new HttpSolrClient.Builder("http://localhost:8983/solr/democore");
HttpSolrClient solrClient = builder.build();
SolrQuery query = new SolrQuery();
query.set("q", "title:计算机科学与技术1495013922355");
QueryResponse response = solrClient.query(query);
SolrDocumentList list = response.getResults();
solrClient.commit();
System.out.println("匹配数量:"+list.getNumFound());
Iterator itr = list.iterator();
while (itr.hasNext()) {
SolrDocument solrDocument = (SolrDocument) itr.next();
Object id = solrDocument.getFieldValue("id");
System.out.println(id.toString());
Object title = solrDocument.getFieldValue("title");
System.out.println(title.toString());
}
至此,全部完成。上述只是最基本的使用配置,对于中文的分词还是停留在最原始的每个中文都当作一个词汇的分词算法上。这是比较暴力不可取的,需要替换对应的中文分词器。
常用的几个命令:
启动:solr start
指定端口启动:solr start -p 8984
停止solr:solr stop -p 8983
删除指定的core文件:solr delete -c corename
创建core:solr create -c corename
solr状态查看:solr status
Apache solr(一)
标签:字段 算法 启动 技术分享 运用 lis arch 基于 同名
原文地址:http://www.cnblogs.com/jmcui/p/6874778.html