标签:order 打印 turn user ret head post bsp idt
python核心库
urllib2
实现对静态网页的抓取,不得不说,“人生苦短,我用python”这句话还是有道理的,要是用java来写,这估计得20行代码
(对不住了博客园了,就拿你开刀吧)
def staticFetch(): url = "http://www.cnblogs.com/" request = urllib2.Request(url) response = urllib2.urlopen(request) print response.read()
实现对动态网页的抓取,采用post请求,如果想用get方法,只需要把参数接在url后面,不需要data这个参数
def postFetch(): data = ‘Keywords:爬虫‘ url = "http://zzk.cnblogs.com/s/blogpost?Keywords=%E7%88%AC%E8%99%AB" request = urllib2.Request(url, data) response = urllib2.urlopen(request) print response.read()
|
正则表达式 |
解释 |
案例(伪代码) |
|
.* |
贪婪模式,匹配除了换行符之外的所有字符 |
str = abcbc regex = a.*c return abcbc |
|
.*? |
非贪婪模式 |
str = abcbc regex = a.*c return abc |
|
(.*?) |
表示只要匹配这一部分 如果是匹配多个则返回的是一个元组类型 |
str = abcbc regex = a(.*)c return b |
|
more |
|
|
urllib2.HTTPError: HTTP Error 403: Forbidden
当你在运行python的时候出现这个错误,则该网址设置过了禁止爬虫访问,需要伪装一下http的请求头,加入如下代码再运行就ok了。
head={‘User-Agent‘:‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘}
urllib2.Request(url,headers=head)
看看爬下来的html是什么编码格式的
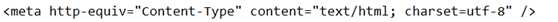
一般都是utf-8,也有gb2312和asic的,保证你的编码和网页的编码是同一种编码。
如果爬下来的网页打印的时候出现\xe6\x96\xb0\xe4\xba\xba这种信息,你可以用以下语句转换成字符串查看
‘,‘.join(str)
//一个python爬虫从入门到放弃的好博客
http://cuiqingcai.com/1052.html
标签:order 打印 turn user ret head post bsp idt
原文地址:http://www.cnblogs.com/ulysses-you/p/6875028.html