标签:联网 ext 合作伙伴 http协议 ... pycha blog 底部 logs
这是关于Python的第14篇文章,主要介绍下爬虫的原理。
提到爬虫,我们就不得不说起网页,因为我们编写的爬虫实际上是针对网页进行设计的。解析网页和抓取这些数据是爬虫所做的事情。
对于大部分网页来讲,它的代码构成主要包括三种语言:HTML、CSS、JavaScript,我们在爬取数据的时候大部分是从HTML和CSS中爬取。
那么,接下来在学爬虫前我们得了解点下面这些事儿。
首先,需要了解客户端与服务器的交换机制。
我们每次在访问页面时,实际上都是在向服务器发起请求,我们称之为request;服务器接到请求后,会给我们一个回应,称为response;这两种行为结合起来,即HTTP协议。
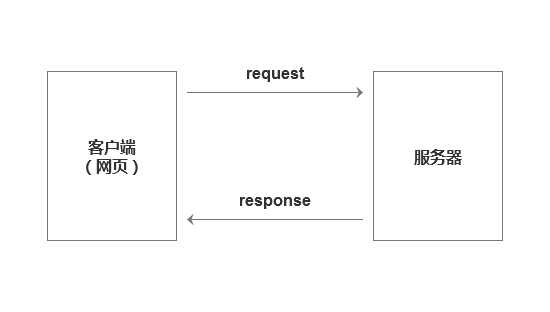
也就是说,HTTP协议是我们的客户端(网页)与服务器会话的一种方式。
在向服务器请求时,request主要包含了8种方法,get、post、head、put、options、connect、trace和delete,我们大多数时候使用到get方法即可,后续在实战操作中会详细展开。
Response是服务器回应给我们的信息。当我们以request向服务器发出请求时,服务器会返回给我们所要的信息。
其次,认识网页的基本构成
一个网页主要由三个部分构成,头部(header)、主体内容(content)和底部(footer)。
我们可以随便打开一个网页,比如PMCAFF的精选页:http://www.pmcaff.com/site/selection,用Google浏览器打开,仔细观察,它是由顶部的导航栏、logo等构成header,中间的文章为content,下面的合作伙伴等构成footer。
然后,我们单击右键选择【检查】,可以看到该页面的源代码,仔细观察下,常用的标签至少包含下面这几个:
最后,在爬虫前,我们需要学会解析网页。
那么,关于如何去解析网页,我们需要学会使用beautifulsoap。
具体内容将在下一篇的实战中详细讲解,用request+beautifulsoap来爬取真实网页的数据。
操作环境:Python版本,3.6;PyCharm版本,2016.2;电脑:Mac
----- End -----
作者:杜王丹,微信公众号:杜王丹,互联网产品经理。

标签:联网 ext 合作伙伴 http协议 ... pycha blog 底部 logs
原文地址:http://www.cnblogs.com/duwangdan/p/6877809.html