标签:筛选 int 原因 对象 read 无限 申请 状态 阻塞
闲来无事,学学python爬虫。
在正式学爬虫前,简单学习了下HTML和CSS,了解了网页的基本结构后,更加快速入门。
1.获取糗事百科url
http://www.qiushibaike.com/hot/page/2/ 末尾2指第2页
2.先抓取HTML页面
import urllib import urllib2 import re page = 2 url = ‘http://www.qiushibaike.com/hot/page/‘ + str(page) #对应第2页的url request = urllib2.Request(url) #发出申请 response = urllib2.urlopen(request) #收到回应
当然这里可能会产生error:主要有HTTPError和URLError。
产生URLError的原因可能是:
异常捕获解决办法:
import urllib2 requset = urllib2.Request(‘http://www.xxxxx.com‘) try: urllib2.urlopen(request) except urllib2.URLError, e: print e.reason
HTTPError是URLError的子类,利用urlopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中它包含一个数字”状态码”。举个例子,假如response是一个”重定向”,需定位到别的地址获取文档,urllib2将对此进行处理。常见的状态码:
200:请求成功 处理方式:获得响应的内容,进行处理
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
异常捕获解决办法:
import urllib2 req = urllib2.Request(‘http://blog.csdn.net/cqcre‘) try: urllib2.urlopen(req) except urllib2.HTTPError, e: print e.code print e.reason
注:HTTPError是URLError的子类,在产生URLError时也会触发产生HTTPError。因此应该先处理HTTPError。上述代码可改写为:
import urllib2 req = urllib2.Request(‘http://blog.csdn.net/cqcre‘) try: urllib2.urlopen(req) except urllib2.HTTPError, e: print e.code except urllib2.URLError, e: print e.reason else: print "OK"
如果无法获得回应,可能需要加入header模拟浏览器发出请求:
import urllib import urllib2 page = 1 url = ‘http://www.qiushibaike.com/hot/page/‘ + str(page) user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ headers = { ‘User-Agent‘ : user_agent } try: request = urllib2.Request(url,headers = headers) # 加入header response = urllib2.urlopen(request) print response.read() except urllib2.URLError, e: if hasattr(e,"code"): print e.code if hasattr(e,"reason"): print e.reason
3.分析页面获取段子
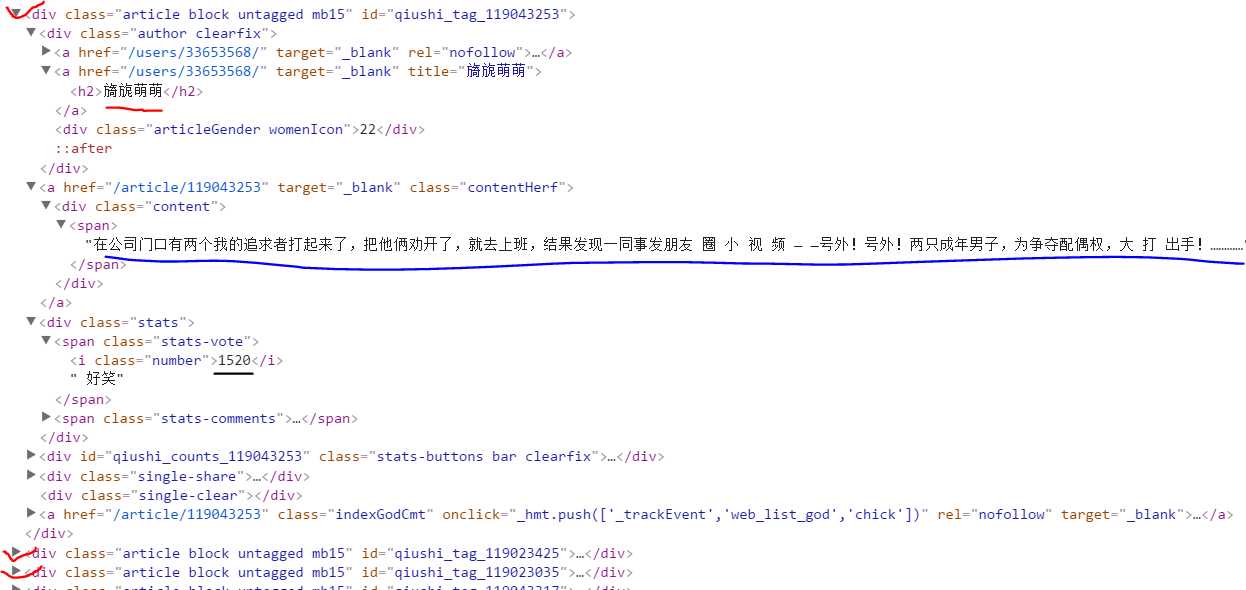
如上图所示,划红对勾的是不同的段子,每个段子都由<div class="article block untagged mb15" id="...">...</div>包裹起来。我们点开其中一个,获取其中的用户名、段子内容和点赞数这三个信息。这三个信息分别用红、蓝、黑下划线圈起来。解析过程主要由正则表达式实现。
正则表达式解释:(参考崔庆才博客)
1).*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
2)(.*?)代表一个分组,在这个正则表达式中我们匹配了五个分组,在后面的遍历item中,item[0]就代表第一个(.*?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
content = response.read().decode(‘utf-8‘)
pattern = re.compile(‘<div class="author clearfix">.*?<h2>(.*?)</h2>.*?<div.*?span>(.*?)</span>.*?<div class="stats">.*?"number">(.*?)</i>‘,re.S)
items = re.findall(pattern,content) # 参考python中的re模块,作用是在content中寻找可以匹配pattern的串,即段子
但是有个问题,上面的表达式将有图和无图的段子都爬取下来了,但是在图片一般不会显示,所以需要去掉有图的段子,只爬取无图片的段子。需要稍微改动正则表达式。
上图是无图的段子html代码,下图是有图的段子的html代码:
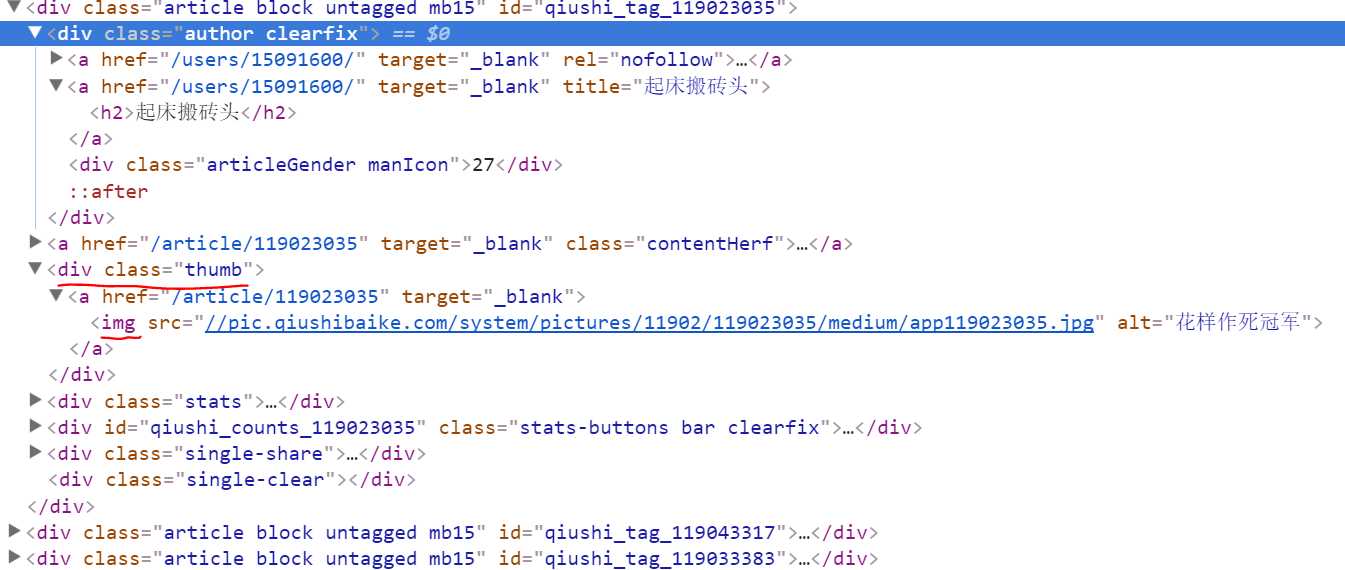
红线划的<div class="thumb">包含了图片部分,而这条语句在无图段子的html中是不存在的,所以利用这条语句中的“img”(上图下划线)来过滤段子。同时注意到这条语句处在段子内容和点赞数中间。
所以在段子内容和点赞这两个正则语句之间加上一个(.*?)即可,这样一来,只要检测到包括“img”,就过滤掉。
content = response.read().decode(‘utf-8‘) pattern = re.compile(‘<div class="author clearfix">.*?<h2>(.*?)</h2>.*?<div.*?span>(.*?)</span>(.*?)<div class="stats">.*?"number">(.*?)</i>‘ # 注意这个(.*?) ,re.S) items = re.findall(pattern,content) # items就是根据正则表达式筛选到的字符串(html串) for item in items: haveImg = re.search("img", item[2]) # 0,1,2,3分别表示用户名,段子内容,图片,点赞数。所以用item[2]来检测过滤 if not haveImg: print item[0], item[1], item[3]
好,以上代码就是可以实现将一页中的无图段子全部爬取出来:代码:
import urllib import urllib2 import re page = 2 url = ‘http://www.qiushibaike.com/hot/page/‘ + str(page) user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ headers = {‘User-Agent‘:user_agent} request = urllib2.Request(url, headers=headers) response = urllib2.urlopen(request) content = response.read().decode(‘utf-8‘) pattern = re.compile(‘<div class="author clearfix">.*?<h2>(.*?)</h2>.*?<div.*?span>(.*?)</span>(.*?)<div class="stats">.*?"number">(.*?)</i>‘ ,re.S) items = re.findall(pattern,content) for item in items: haveImg = re.search("img", item[2]) if not haveImg: print item[0], item[1], item[3]
4.以上代码是核心,但是略有简陋,稍加修补:
# coding:utf-8 import urllib import urllib2 import re class Spider_QSBK: def __init__(self): self.page_index = 2 self.enable = False self.stories = [] self.user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ self.headers = {‘User-Agent‘:self.user_agent} def getPage(self, page_index): url = ‘http://www.qiushibaike.com/hot/page/‘ + str(page_index) try: request = urllib2.Request(url, headers=self.headers) response = urllib2.urlopen(request) content = response.read().decode(‘utf-8‘) return content except urllib2.URLError, e: print e.reason return None def getStories(self,page_index): content = self.getPage(page_index) pattern = re.compile(‘<div class="author clearfix">.*?<h2>(.*?)</h2>.*?<div.*?span>(.*?)</span>(.*?)<div class="stats">.*?"number">(.*?)</i>‘ ,re.S) items = re.findall(pattern,content) for item in items: haveImg = re.search("img", item[2]) if not haveImg: self.stories.append([item[0], item[1], item[3]]) return self.stories def ShowStories(self, page_index): self.getStories(page_index) for st in self.stories: print u"第%d页\t发布人:%s\t点赞数:%s\n%s" %(page_index, st[0], st[2], st[1]) del self.stories def start(self): self.enable = True # while self.enable: self.ShowStories(self.page_index) self.page_index += 1 spider = Spider_QSBK() spider.start()
结果一样:

标签:筛选 int 原因 对象 read 无限 申请 状态 阻塞
原文地址:http://www.cnblogs.com/king-lps/p/6879803.html