标签:分享 auto 学习 经验 相关 问题 最小 样本 linear
机器学习是在模型空间中选择最优模型的过程,所谓最优模型,及可以很好地拟合已有数据集,并且正确预测未知数据。
那么如何评价一个模型的优劣的,用代价函数(Cost function)来度量预测错误的程度。代价函数有很多中,在Ng的视频中,Linear Regression用的是平方代价函数:
![]()
Logistic Regression 用的是对数似然代价函数:
![]()
对于给定的含m个样本的数据集,其平均损失称为经验风险。
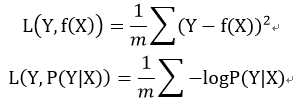
损失函数越小,模型就越好。
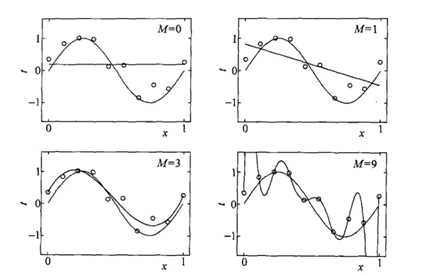
我们来分析那个房价预测问题,假设房价面积A,楼层L,房间数N相关,那我们的目标就是要通过机器学习得到一个关于A,L,N的模型,这个模型可以预测房价,但问题是我们输入是应该用A呢?还是A的平方,或者A 的三次方?(同样对L和N提问)这是个无穷尽的问题,理论上,次数越高,对于已有测试数据能拟合地越好,但是次数越高,就会使模型越复杂,这时就会出现过拟合的问题,例如下图中的第四张小图,用9次方去预测,模型能拟合每个点,但是这种模型往往对已知参数预测地很好,未知数据预测能力很差。
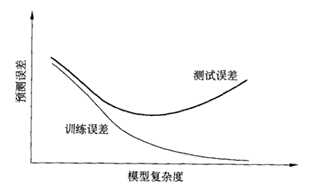
当模型复杂度增加时,训练误差会越来越小,以至于能拟合样本中的绝大部分点,但是测试误差却随着复杂度的增加先减小后增加,存在一个极小值。
为了解决过拟合的问题,我们引入“正则化项”,它的作用是选择经验风险和模型复杂度同时小。这样问题就转化为求经验风险和正则化项之和的最小值。
正则化项可以采取不同的形式,有L2范数,L1范数:
![]()
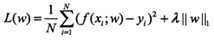
Machine Learning — 关于过度拟合(Overfitting)
标签:分享 auto 学习 经验 相关 问题 最小 样本 linear
原文地址:http://www.cnblogs.com/sharon123/p/6882028.html