标签:matrix tar 归类 double 方法 .com pre imp new
SparkMLlib学习分类算法之逻辑回归算法
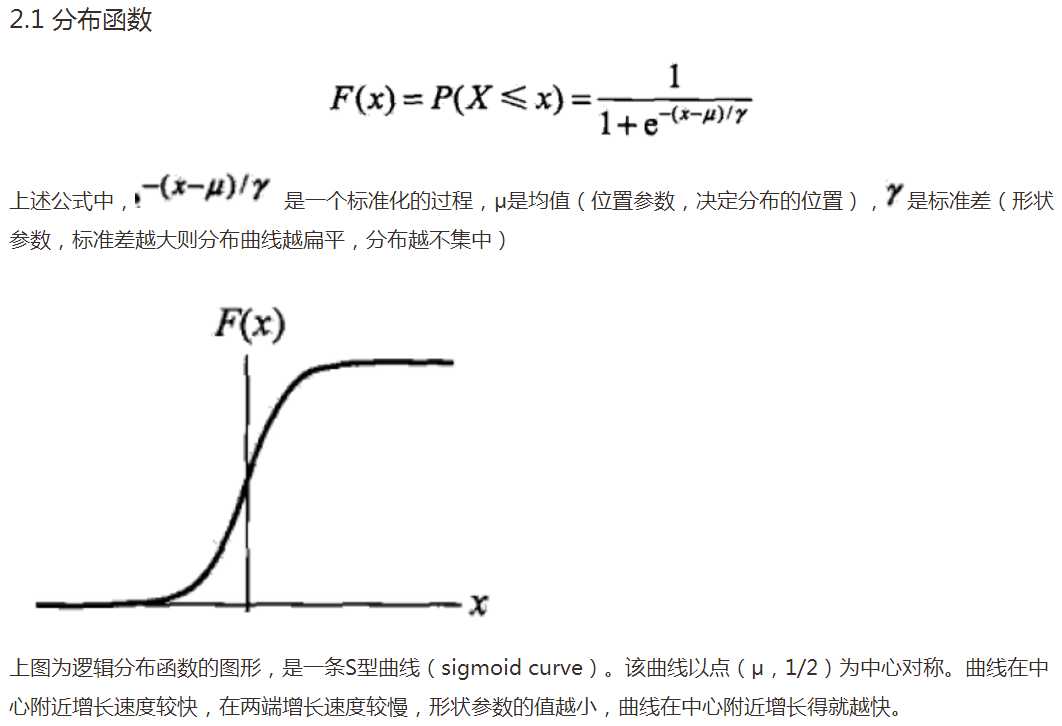
(一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693836)
逻辑回归与线性回归类似,但它不属于回归分析家族(主要为二分类),而属于分类家族,差异主要在于变量不同,因此其解法与生成曲线也不尽相同。逻辑回归是无监督学习的一个重要算法,对某些数据与事物的归属(分到哪个类别)及可能性(分到某一类别的概率)进行评估。
(二),SparkMLlib逻辑回归应用
1,数据集的选择:http://www.kaggle.com/c/stumbleupon/data 中的(train.txt和test.txt)
2,数据集描述:关于涉及网页中推荐的页面是短暂(短暂存在,很快就不流行了)还是长久(长时间流行)的分类
3,数据预处理及获取训练集和测试集
val orig_file=sc.textFile("train_nohead.tsv")
//println(orig_file.first())
val data_file=orig_file.map(_.split("\t")).map{
r =>
val trimmed =r.map(_.replace("\"",""))
val lable=trimmed(r.length-1).toDouble
val feature=trimmed.slice(4,r.length-1).map(d => if(d=="?")0.0
else d.toDouble)
LabeledPoint(lable,Vectors.dense(feature))
}.randomSplit(Array(0.7,0.3),11L)
val data_train=data_file(0)//训练集
val data_test=data_file(1)//测试集
4,逻辑回归模型训练及模型评价
val model_log=new LogisticRegressionWithLBFGS().setNumClasses(2).run(data_train) /* 有两种最优化算法可以求解逻辑回归问题并求出最优参数:mini-batch gradient descent(梯度下降法),L-BFGS法。我们更推荐使用L-BFGS,因为它能更快聚合,而且现在spark2.1.0已经放弃LogisticRegressionWithLSGD()模式了*/ /*性能评估:使用精确度,PR曲线,AOC曲线*/ val predictionAndLabels=data_test.map(point => (model_log.predict(point.features),point.label) ) val metricsLG=new MulticlassMetrics(predictionAndLabels)//0.6079335793357934 val metrics=Seq(model_log).map{ model => val socreAndLabels=data_test.map { point => (model.predict(point.features), point.label) } val metrics=new BinaryClassificationMetrics(socreAndLabels) (model.getClass.getSimpleName,metrics.areaUnderPR(),metrics.areaUnderROC()) } val allMetrics = metrics allMetrics.foreach{ case (m, pr, roc) => println(f"$m, Area under PR: ${pr * 100.0}%2.4f%%, Area under ROC: ${roc * 100.0}%2.4f%%") } /*LogisticRegressionModel, Area under PR: 73.1104%, Area under ROC: 60.4200%*/
5,模型优化
特征标准化处理


val orig_file=sc.textFile("train_nohead.tsv")
//println(orig_file.first())
val data_file=orig_file.map(_.split("\t")).map{
r =>
val trimmed =r.map(_.replace("\"",""))
val lable=trimmed(r.length-1).toDouble
val feature=trimmed.slice(4,r.length-1).map(d => if(d=="?")0.0
else d.toDouble)
LabeledPoint(lable,Vectors.dense(feature))
}
/*特征标准化优化*/
val vectors=data_file.map(x =>x.features)
val rows=new RowMatrix(vectors)
println(rows.computeColumnSummaryStatistics().variance)//每列的方差
val scaler=new StandardScaler(withMean=true,withStd=true).fit(vectors)//标准化
val scaled_data=data_file.map(point => LabeledPoint(point.label,scaler.transform(point.features)))
.randomSplit(Array(0.7,0.3),11L)
val data_train=scaled_data(0)
val data_test=scaled_data(1)
/*训练逻辑回归模型*/
val model_log=new LogisticRegressionWithLBFGS().setNumClasses(2).run(data_train)
/*在使用模型做预测时,如何知道预测到底好不好呢?换句话说,应该知道怎么评估模型性能。
通常在二分类中使用的评估方法包括:预测正确率和错误率、准确率和召回率、准确率 ? 召回率
曲线下方的面积、 ROC 曲线、 ROC 曲线下的面积和 F-Measure*/
val predictionAndLabels=data_test.map(point =>
(model_log.predict(point.features),point.label)
)
val metricsLG=new MulticlassMetrics(predictionAndLabels)//精确度:0.6236162361623616
val metrics=Seq(model_log).map{
model =>
val socreAndLabels=data_test.map {
point => (model.predict(point.features), point.label)
}
val metrics=new BinaryClassificationMetrics(socreAndLabels)
(model.getClass.getSimpleName,metrics.areaUnderPR(),metrics.areaUnderROC())
}
val allMetrics = metrics
allMetrics.foreach{ case (m, pr, roc) =>
println(f"$m, Area under PR: ${pr * 100.0}%2.4f%%, Area under ROC: ${roc * 100.0}%2.4f%%")
}
/*LogisticRegressionModel, Area under PR: 74.1103%, Area under ROC: 62.0064%*/
6,总结
1,如何能提高更明显的精度。。。。。
2,对逻辑回归的认识还不够。。。。
标签:matrix tar 归类 double 方法 .com pre imp new
原文地址:http://www.cnblogs.com/ksWorld/p/6882398.html
