标签:二级域名 tool add 图像 tco base err 学习 import
这次主要学习了替换各种标签,规范格式的方法。依然参考博主崔庆才的博客。
1.获取url
某一帖子:https://tieba.baidu.com/p/3138733512?see_lz=1&pn=1
其中https://tieba.baidu.com/p/3138733512?为基础部分,剩余的为参数部分。
def getPage(self, pagenum): try: url = self.baseurl + self.seelz + ‘&pn=‘ + str(pagenum) request = urllib2.Request(url) response = urllib2.urlopen(request) # print response.read() # print url return response.read().decode(‘utf-8‘) except urllib2.URLError, e: if hasattr(e, ‘reason‘): print ‘wrong !‘,e.reason return None

因为标题由<h3 class="core_title_txt...</h3>包围,所以利用正则表达式很容易获取。
def getTitle(self): page = self.getPage(1) pattern = re.compile(‘<h3 class="core_title_tx.*?>(.*?)</h3>‘, re.S) result = re.search(pattern, page) if result: print result.group(1) else: return None
3.获取帖子页数
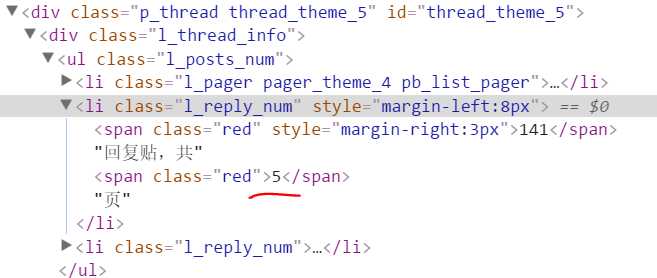
如上图,利用正则表达式如下:
def getPageNum(self): page = self.getPage(1) pattern = re.compile(‘<li class="l_reply_num.*?</span>.*?<span.*?>(.*?)</span>‘, re.S) result = re.search(pattern, page) if result: print result.group(1) else: return None
4.获取楼主正文内容
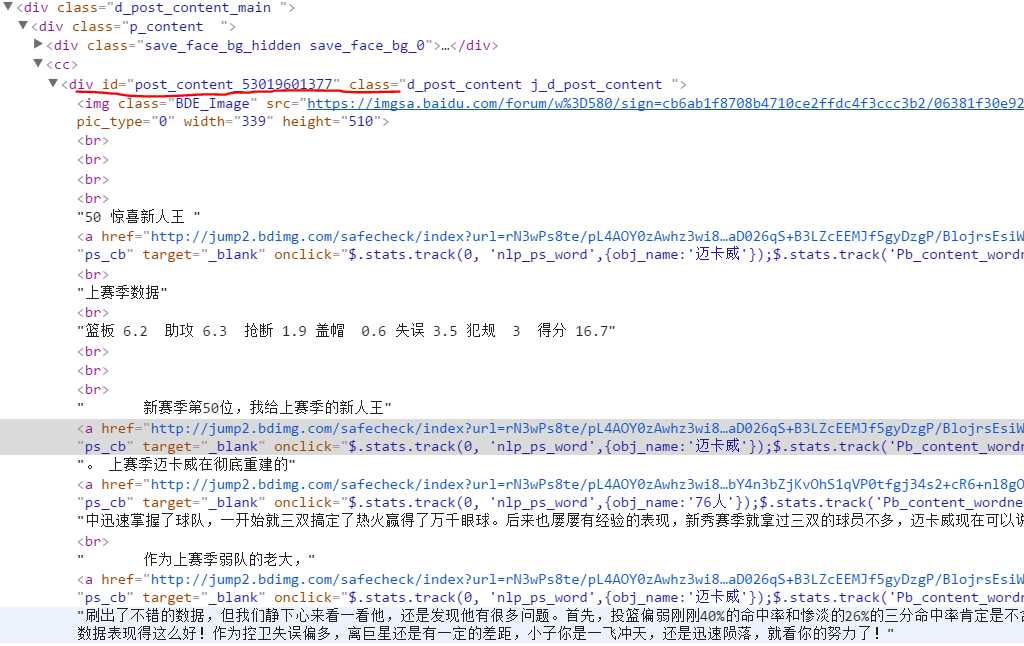
def getContent(self): page = self.getPage(1) pattern = re.compile(‘<div id="post_content_.*?>(.*?)</div>‘, re.S) items = re.findall(pattern, page) for item in items: print self.tool.replace(item)
正文主要包括在<div id="post.....></div>,但是明显正文中穿插了各种换行符、链接、图片、段落符等。所以需要将这些符号删除或替换。
替换代码如下:
class Tool: removeImg = re.compile(‘<img.*?>| {7}|‘) #去除图像和7位空格 removeAddr = re.compile(‘<a.*?>|</a>‘) #去除链接 replaceLine = re.compile(‘<tr>|<div>|<div></p>‘) #换行符替换成\n replaceTD = re.compile(‘<td>‘) #制表符换位\t replacePara = re.compile(‘<p.*?>‘) #段落符换位\n和两个空格 replaceBR = re.compile(‘<br>|<br><br>‘) #换行符或双换行符替换为\n removeExtraTag = re.compile(‘<.*?>‘) #去掉其他符号 def replace(self, x): x = re.sub(self.removeImg, "", x) x = re.sub(self.removeAddr, "", x) x = re.sub(self.replaceLine, ‘\n‘, x) x = re.sub(self.replaceTD, ‘\t‘, x) x = re.sub(self.replacePara, "\n ", x) x = re.sub(self.replaceBR, ‘\n‘, x) x = re.sub(self.removeExtraTag, "", x) return x.strip()
5.整体代码及结果
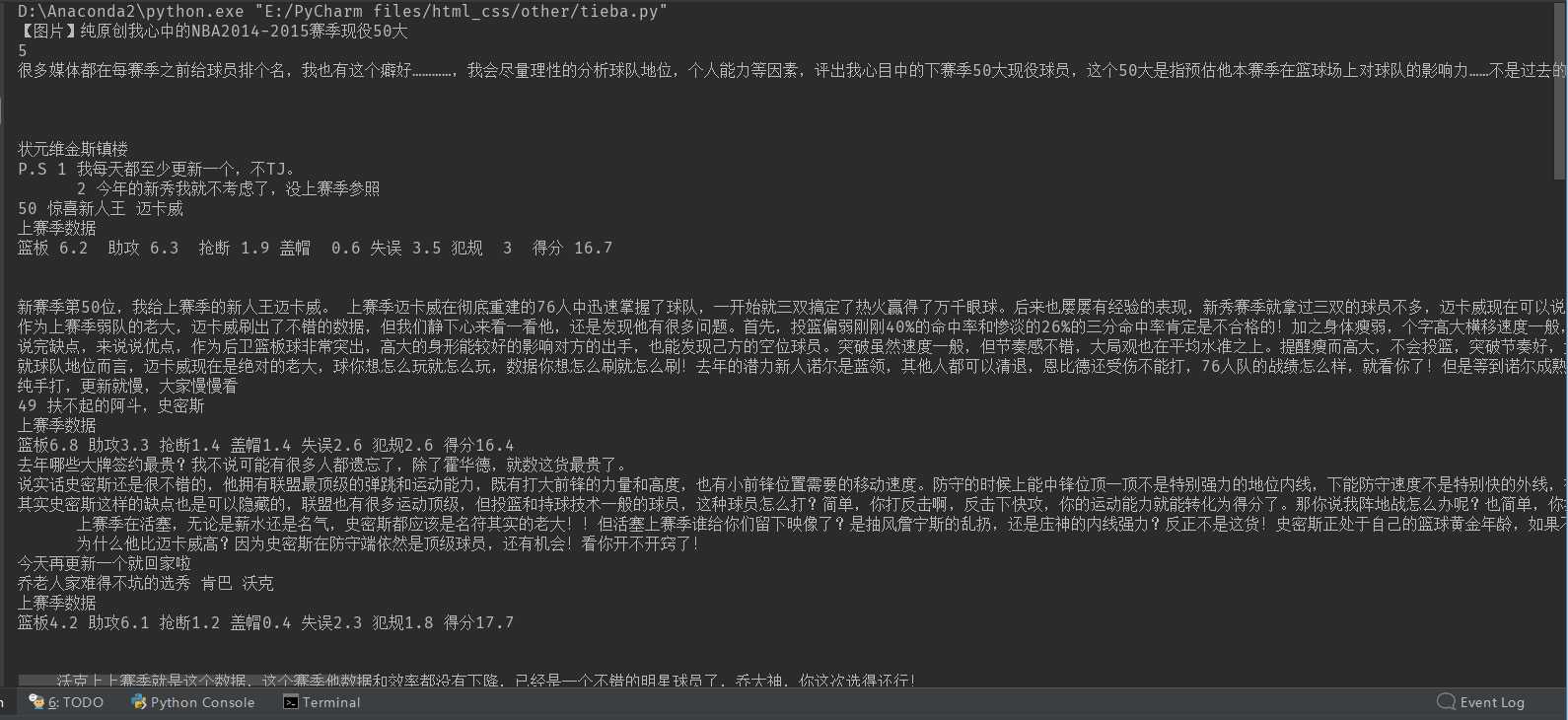
# coding:utf-8 import urllib import urllib2 import re class Tool: removeImg = re.compile(‘<img.*?>| {7}|‘) removeAddr = re.compile(‘<a.*?>|</a>‘) replaceLine = re.compile(‘<tr>|<div>|<div></p>‘) replaceTD = re.compile(‘<td>‘) replacePara = re.compile(‘<p.*?>‘) replaceBR = re.compile(‘<br>|<br><br>‘) removeExtraTag = re.compile(‘<.*?>‘) def replace(self, x): x = re.sub(self.removeImg, "", x) x = re.sub(self.removeAddr, "", x) x = re.sub(self.replaceLine, ‘\n‘, x) x = re.sub(self.replaceTD, ‘\t‘, x) x = re.sub(self.replacePara, "\n ", x) x = re.sub(self.replaceBR, ‘\n‘, x) x = re.sub(self.removeExtraTag, "", x) return x.strip() class tieba: def __init__(self, baseurl, seelz): self.baseurl = baseurl self.seelz = ‘?see_lz=‘ + str(seelz) self.tool = Tool() def getPage(self, pagenum): try: url = self.baseurl + self.seelz + ‘&pn=‘ + str(pagenum) request = urllib2.Request(url) response = urllib2.urlopen(request) # print response.read() # print url return response.read().decode(‘utf-8‘) except urllib2.URLError, e: if hasattr(e, ‘reason‘): print ‘wrong !‘,e.reason return None def getTitle(self): page = self.getPage(1) pattern = re.compile(‘<h3 class="core_title_tx.*?>(.*?)</h3>‘, re.S) result = re.search(pattern, page) if result: print result.group(1) else: return None def getPageNum(self): page = self.getPage(1) pattern = re.compile(‘<li class="l_reply_num.*?</span>.*?<span.*?>(.*?)</span>‘, re.S) result = re.search(pattern, page) if result: print result.group(1) else: return None def getContent(self): page = self.getPage(1) pattern = re.compile(‘<div id="post_content_.*?>(.*?)</div>‘, re.S) items = re.findall(pattern, page) for item in items: print self.tool.replace(item) baseURL = ‘https://tieba.baidu.com/p/3138733512‘ bdtb = tieba(baseURL, 1) # bdtb.getPage(1) bdtb.getTitle() bdtb.getPageNum() bdtb.getContent()
标签:二级域名 tool add 图像 tco base err 学习 import
原文地址:http://www.cnblogs.com/king-lps/p/6882507.html