标签:res 技术分享 path ctime 查询 第一个 src sage blank
http://blog.csdn.net/chencheng126/article/details/50070021
参考于这个博主的博文。
1 #coding=utf-8 2 3 4 # import warnings 5 # warnings.filterwarnings(action=‘ignore‘, category=UserWarning, module=‘gensim‘) 6 import logging 7 from gensim import corpora, models, similarities 8 9 datapath = ‘D:/hellowxc/python/testres0519.txt‘ 10 querypath = ‘D:/hellowxc/python/queryres0519.txt‘ 11 storepath = ‘D:/hellowxc/python/store0519.txt‘ 12 def similarity(datapath, querypath, storepath): 13 logging.basicConfig(format=‘%(asctime)s : %(levelname)s : %(message)s‘, level=logging.INFO) 14 15 class MyCorpus(object): 16 def __iter__(self): 17 for line in open(datapath): 18 yield line.split() 19 20 Corp = MyCorpus() 21 dictionary = corpora.Dictionary(Corp) 22 corpus = [dictionary.doc2bow(text) for text in Corp] 23 24 tfidf = models.TfidfModel(corpus) 25 26 corpus_tfidf = tfidf[corpus] 27 28 q_file = open(querypath, ‘r‘) 29 query = q_file.readline() 30 q_file.close() 31 vec_bow = dictionary.doc2bow(query.split()) 32 vec_tfidf = tfidf[vec_bow] 33 34 index = similarities.MatrixSimilarity(corpus_tfidf) 35 sims = index[vec_tfidf] 36 37 similarity = list(sims) 38 39 sim_file = open(storepath, ‘w‘) 40 for i in similarity: 41 sim_file.write(str(i)+‘\n‘) 42 sim_file.close() 43 similarity(datapath, querypath, storepath)
贴一下我的test代码。
我的test文件querypath是一个问题,datapath是对这个问题的各种回答,我试图通过文本相似度来分析问题和哪个答案最匹配。。
原博客的测试是querypath是商品描述,datapath是商品的评论,通过文本相似度来分析,商品描述和实际的商品是否差异过大。
贴一下我的测试数据。很小的数据,就是测试一下这个:
注意所有的数据已经经过分词处理,分词怎么处理,可以用python的jieba库分词处理。可以参考http://www.cnblogs.com/weedboy/p/6854324.html
query

data

store(也就是结果)
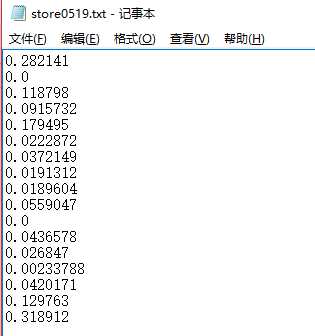
测试结果和问题实际上最应该匹配的对不上。。
总结:
1.gensim 除了提供了tf-idf 算法,好好利用
2.我用jieba分词的忘记删掉停用词了,给结果带来很大影响,jieba库里有函数可以删停用词的
3.问答系统中,关于问题和答案匹配,如果不用有监督的机器学习是不行的。。
标签:res 技术分享 path ctime 查询 第一个 src sage blank
原文地址:http://www.cnblogs.com/weedboy/p/6885588.html