标签:系统 fail comment 统计 ase print 知识 rem 整数
MongoDB是面向文档的非关系型数据库,不是现在使用最普遍的关系型数据库,其放弃关系模型的原因就是为了获得更加方便的扩展、稳定容错等特性。面向文档的基本思路就是:将关系模型中的“行”的概念换成“文档(document)”模型。面向文档的模型可以将文档和数组内嵌到文档中。因此,实际中可以用一条数据表示非常复杂的结构。
MongoDB没有预定义模式:文档的键(key)和值(value)不再是固定的类型和大小,而且根据需求要添加或者删除字段变得更容易了。由于没有模式需要更改,通常不需要迁移大量数据。不必将所有数据都放到一个模子里面,应用层可以处理新增或丢失的键。这样开发者可以非常容易地变更数据模型。
实际应用中,随着数据量的增大,数据库都要进行扩展。扩展有纵向扩展和横向扩展。纵向扩展是使用计算能力更强的机器,也是最省力的方法,但是很容易达到物理极限,无论花多少钱也买不到最新的机器了。横向扩展就是通过分区将数据分散到更多的机器上。MongoDB的设计采用横向扩展。面向文档的数据模型使它很容易地在多台服务器之间进行数据分割。还可以自动处理跨集群的数据和负载,自动重新分配文档,以及将用户请求路由到正确的机器上。开发者根本不用考虑数据库层次的扩展问题,需要扩展数据库时,在集群中添加机器即可,MongoDB会自动处理后续的事情。
MongoDB有如上各种特性,但为了达到这些,他也放弃了关系型数据库的某些功能如表连接join和复杂的多行事务。
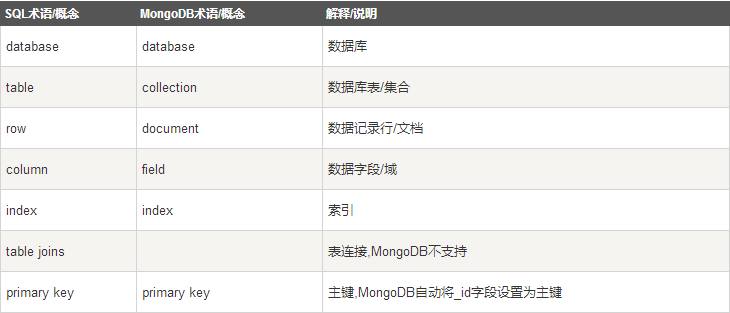
直观了解: 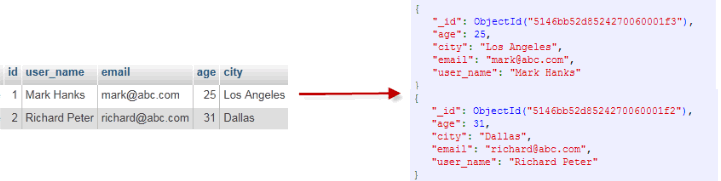
| 数据库 | MongoDB | MySQL |
|---|---|---|
| 数据库模型 | 非关系型 | 关系型 |
| 存储方式 | 以类JSON的文档的格式存储 | 不同引擎有不同的存储方式 |
| 查询语句 | MongoDB查询方式(类似JavaScript的函数) | SQL语句 |
| 数据处理方式 | 基于内存,将热数据存放在物理内存中,从而达到高速读写 | 不同引擎有自己的特点 |
| 成熟度 | 新兴数据库,成熟度较低 | 成熟度高 |
| 广泛度 | NoSQL数据库中,比较完善且开源,使用人数在不断增长 | 开源数据库,市场份额不断增长 |
| 事务性 | 仅支持单文档事务操作,弱一致性 | 支持事务操作 |
| 占用空间 | 占用空间大 | 占用空间小 |
| join操作 | MongoDB没有join | MySQL支持join |
下面是Mongodb与Mysql的操作命令的对比: 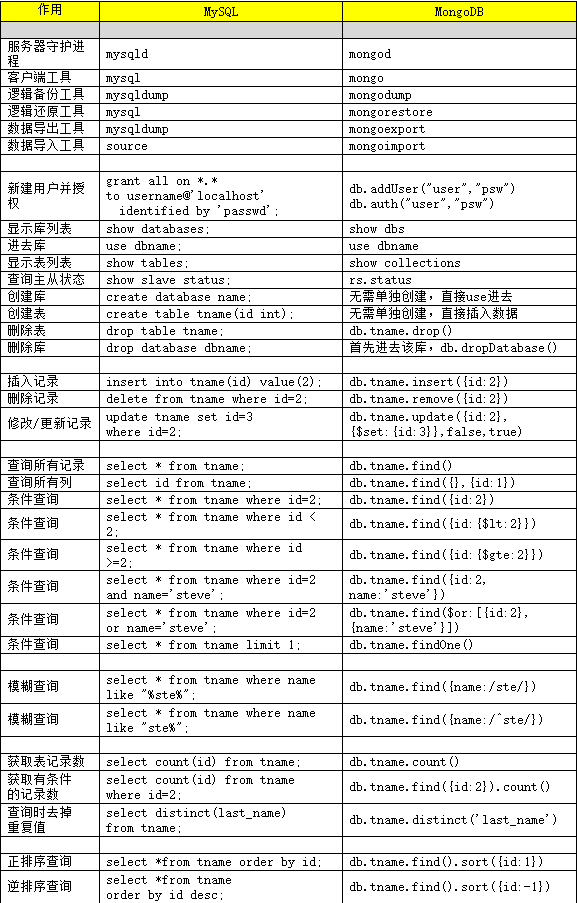
1.文档(document):相当于传统关系型数据库的“行”,但比传统行表示的信息更加复杂。例如:
{"name":"jack","age":18,"sex":"male"}
2.集合(collection):这个在MongoDB中代表一组文档,类似于关系型数据库中的表。但在MongoDB中的表(就是集合)是没有模式的,你可以将完全不同的文档放入同一个集合中.但在实际使用中,为特定集合隐性规定一种模式。注:当集合里没有任何文档时集合其实也是不存在的。当第一个文档插入时,集合就会被创建。
3.数据库(database):在MongoDB中,一组集合可以组成一个数据库。一个MongoDB实例可以承载多个数据库。每个数据库都有独立的权限控制。在实际应用中,通常,一个应用的所有数据放置在一个数据库中。
4.数据类型:MongoDB中的文档类似于JSON。JSON是一种简单的数据交换格式,在数据类型方面,只支持:null,布尔,数字,字符串,数组和对象。这几种类型在某些实际应用中表现力还是不够,比如JSON本身不直接支持日期类型,对于数字,JSON本身也没法区分整数和浮点数,更不能区分32位数字和64位数字。为此,MongoDB再保留了JSON的各类特性外,又为其添加了一些数据类型。
1.null:用于表示空值或不存在的字段。Shell中这样表示:{"x":null}
2.布尔:有两个值,true和false。Shell中这样使用:{"x":true}
3.数字:Shell中数字均为64位浮点数,如在Shell中{"x":3.14}和{"x":3}这两个文档中的值均是64位的浮点数。
4.字符串:这个用的最广,Shell中这样表示:{"x":"hello world!"}
5.日期:这个在数据存储时,存储的是从标准纪元开始的毫秒数,没有存储时区信息。
6.正则表达式:文档中可以包含正则表达式,采用JavaScript的正则表达式语法即可,Shell中这样表示:{"x":/foobar/i}。
7.数组:数组是一组值,既可以表示为有序对象(列表,栈,队列等)也可以表示无序对象(集合),Shell中这样表示一个数组:{"things":["pie",3.14]}。
8.内嵌文档:把一个文档整个作为另一个文档某一个键对应的值。
其他包括二进制数据,代码等。
运行mongo启动shell: 
shell是一个功能完备的JavaScript解释器,可运行任意的JavaScript程序。这里不做示例。
MongoDB的默认数据库为"db",该数据库存储在data目录中。
1.选择数据库
#选择名test数据库 use tset

如果忘记了数据库名称可以输入如下代码查询所有数据库名称:"show dbs" 命令可以显示所有数据的列表
show dbs

查看数据库中的集合名:
show collections
结果如图所示: 
下表列出了 RDBMS 与 MongoDB 对应的术语: 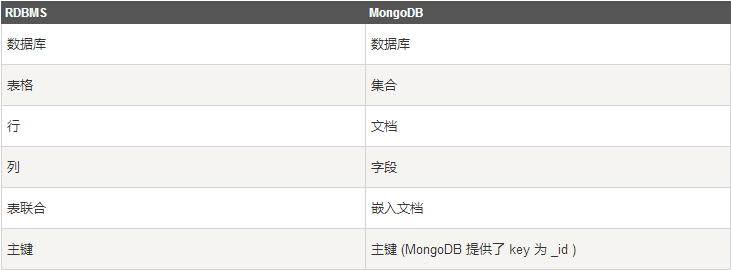
insert函数可将一个文档插入到集合中去。以一个博客举例。先创建一个叫post的变量(JavaScript对象)有三个键和对应的属性。插入代码:
db.blog.insert(post)
如图所示: 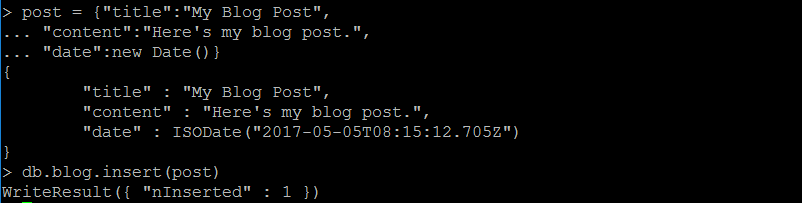
批量插入
db.blog.insertMany([{"_id":0},{"_id":1},{"_id":2}])

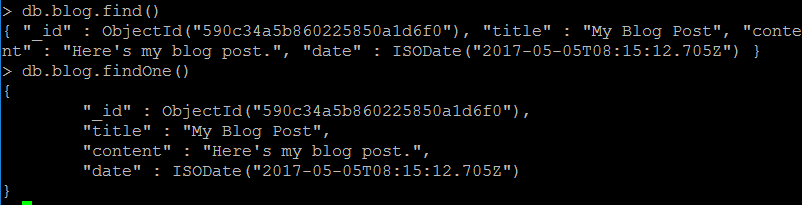
查询代码如下:
db.blog.find()
如图所示: 
多出来的"_id"就是MongoDB自动创建的默认为ObjectID类型的对象。在一个集合里,每个文档都由唯一的"_id",确保集合中的每个文档都能被唯一标识,它采用12字节的存储空间,由24个16进制数字组成,可分为四部分组成:
| {0,1,2,3} | {4,5,6} | {7,8} | {9,10,11} |
|---|---|---|---|
| 时间戳 | 机器码 | PID(线程码) | 自增计数器 |
如果插入文档时没有"_id"键,系统会为我们自动创建一个。
若只想查看一个文档,可以用findOne:
db.blog.findOne()
查询具体的某一个文档那么就要以json的形式添加查询条件,例如:
db.blog.find({"title":"My Blog Post"})
以上实例中类似于 WHERE 语句:WHERE title = ‘My Blog Post‘;
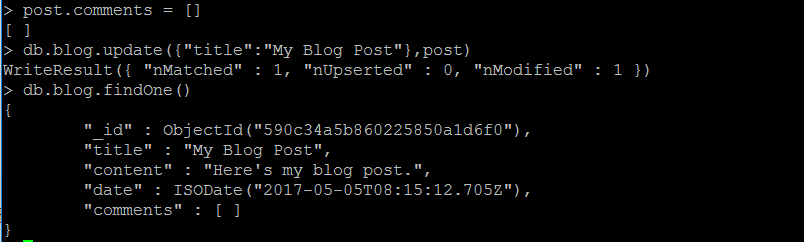
如果给博客新增一个评论功能,则需要新增key-value,用于保存评论数组。
post.comments = []
之后用新版本的文档替换旧版本:
db.blog.update({"title":"My Blog Post"},post)
"$Set":用来指定一个字段的值,若字段不存在,则创建它。db.users.update({"sex":"male"},{"$Set":{"gift":"happy birthday!"}})
/*这样只会更新一个文档,若要更新多个文档,则需要将update的第四个参数设置为true*/
db.users.update({"sex":"male"},{"$Set":{"gift":"happy birthday!"}},false,true)
"$inc":用来增加已有键的值,若键不存在,就创建它。(与"$Set"类似,专门用来增加数字的,只能用于整形,长整型,双精度浮点型)db.games.update({"game":"pinball","user":"joe"},{"$inc":{"score":50}})
"$push":会向已有的数组末尾加入一个元素,若数组不存在,则创建数组。与"$each"自操作符一同使用可以一次添加多个值。db.stock.ticker.update({"_id":"1"},{"$push":{"hourly":{"$each":[562.667,562.790,562.123]}}})
"$addToSet":可以避免重复插入。若数组内已有相同数据,则不差入。与"$each"自操作符一同使用可以一次添加多个值。db.users.update({"_id""1},{"$addToSet":{"emails":"joe@gmail.com"}})
"$push":删除数组里的元素.("$pop":将数组看成队列或栈,从两端删除。"$pull":将所匹配到的数组中的值删除,而不是只删除一个)db.blog.remove({"title":"My Blog Post"})

删除整个集合用drop()
db.blog.drop()
MongoDB使用 ensureIndex() 方法来创建索引。
db.COLLECTION_NAME.ensureIndex({KEY:1})
语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
当然也可以给多个字段建立索引
db.col.ensureIndex({"title":1,"description":-1})
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
);
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
db.article.find().limit
db.article.aggregate( { $skip : 5 });
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
连接数据库,你需要指定数据库名称,如果指定的数据库不存在,mongo会自动创建数据库。
所需jar包: mongo-java-driver-3.2.2.jar
连接数据库的Java代码如下:
1 import com.mongodb.MongoClient; 2 import com.mongodb.client.MongoDatabase; 3 public class MongoDBJDBC{ 4 public static void main( String args[] ){ 5 try{ 6 // 连接到 mongodb 服务 7 MongoClient mongoClient = new MongoClient( "localhost" , 27017 ); 8 // 连接到数据库 9 MongoDatabase mongoDatabase = mongoClient.getDatabase("test"); 10 System.out.println("Connect to database successfully"); 11 }catch(Exception e){ 12 System.err.println( e.getClass().getName() + ": " + e.getMessage() ); 13 } 14 } 15 }
创建集合:
我们可以使用 com.mongodb.client.MongoDatabase 类中的createCollection()来创建集合
代码片段如下:
import com.mongodb.MongoClient; import com.mongodb.client.MongoDatabase; public class MongoDBJDBC{ public static void main( String args[] ){ try{ // 连接到 mongodb 服务 MongoClient mongoClient = new MongoClient( "localhost" , 27017 ); // 连接到数据库 MongoDatabase mongoDatabase = mongoClient.getDatabase("test"); System.out.println("Connect to database successfully"); mongoDatabase.createCollection("test"); System.out.println("集合创建成功"); }catch(Exception e){ System.err.println( e.getClass().getName() + ": " + e.getMessage() ); } } }
//插入文档 /** * 1. 创建文档 org.bson.Document 参数为key-value的格式 * 2. 创建文档集合List<Document> * 3. 将文档集合插入数据库集合中 mongoCollection.insertMany(List<Document>) 插入单个文档可以用 mongoCollection.insertOne(Document) * */ Document document = new Document("title", "MongoDB"). append("description", "database"). append("likes", 100). append("by", "Fly"); List<Document> documents = new ArrayList<Document>(); documents.add(document); collection.insertMany(documents); System.out.println("文档插入成功");
//检索所有文档 /** * 1. 获取迭代器FindIterable<Document> * 2. 获取游标MongoCursor<Document> * 3. 通过游标遍历检索出的文档集合 * */ FindIterable<Document> findIterable = collection.find(); MongoCursor<Document> mongoCursor = findIterable.iterator(); while(mongoCursor.hasNext()){ System.out.println(mongoCursor.next()); }
//更新文档 将文档中likes=100的文档修改为likes=200 collection.updateMany(Filters.eq("likes", 100), new Document("$set",new Document("likes",200))); //检索查看结果 FindIterable<Document> findIterable = collection.find(); MongoCursor<Document> mongoCursor = findIterable.iterator(); while(mongoCursor.hasNext()){ System.out.println(mongoCursor.next()); }
//删除符合条件的第一个文档 collection.deleteOne(Filters.eq("likes", 200)); //删除所有符合条件的文档 collection.deleteMany (Filters.eq("likes", 200)); //检索查看结果 FindIterable<Document> findIterable = collection.find(); MongoCursor<Document> mongoCursor = findIterable.iterator(); while(mongoCursor.hasNext()){ System.out.println(mongoCursor.next()); }
标签:系统 fail comment 统计 ase print 知识 rem 整数
原文地址:http://www.cnblogs.com/zt110e5/p/6885746.html