标签:begin 参考 没有 关键字 width blog images com idt
1. order by (排序)
通常使用一个字段作为参考标准,进行排序。
语法:order by 【字段】 asc|desc;(升序、降序)
tip : 校对规则 决定 排序关系。
允许多字段排序(先按第一个字段排序,当出现不能区分的时候,按第二个字段进行排序,依此类推)。
【举个栗子】 对于下表,输入select * from tb_name; 时,会按照输入顺序依次显示表中的数据:
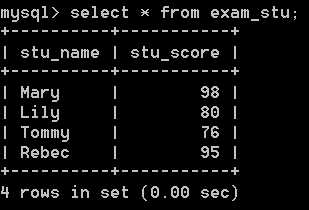
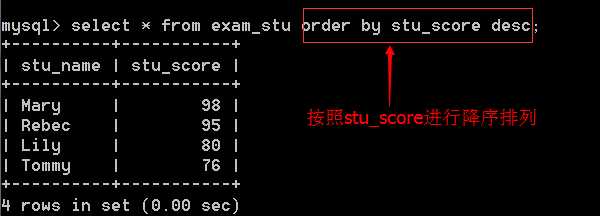
当需要对表中数据按照字段 stu_score 进行降序排列时,在输入语句后加上order by stu_score desc .
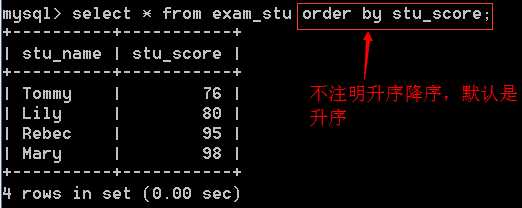
如果不注明升序、降序,默认使用升序:
若使用多字段排序,eg. 先按stu_score进行排序,若分数相同,再按照开课时间date_begin进行排序,语句为:
select * from tb_name order by stu_score desc , date_begin , asc;
tip : order by是对检索出来的信息进行排序,因此需要写在where语句后。
如果是分组,则应该使用对分组字段进行排序的group by语法。
2. limit(限制获得的记录数量)
limit 发生在排序、检索等行为之后,所以 limit 出现在最后。
对于下面的数据表,若限制只显示其中的1个数据,则输出结果为右图:
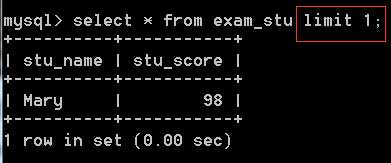
即会按照最初数据输入的顺序,取第一组数据进行输出。
也可以在进行完排序后,限制只输出前3名:
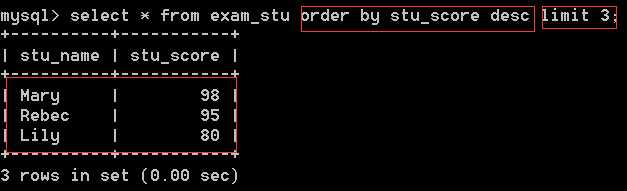
语法:limit 偏移量 总记录数;
偏移量:截取的开始点。 总记录数:截取的长度。
若不写偏移量,默认从0开始。
3. distinct(去除重复记录)(与all相对应)
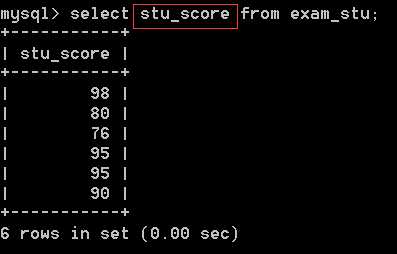
当在表exam_stu中,显示字段stu_score中的所有数据时,结果如下:
若想去除其中的重复记录,可使用一下语句,于是两个95分便只剩下了一个:
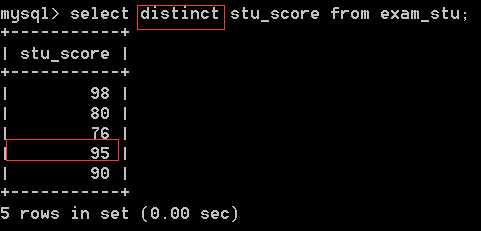
重复记录的标准是按照查询的字段来确定的,当语句为select distinct * 时,只有当所有字段都一样时,才认为两条数据重复;
当语句是 select distinct stu_score时,当两条数据的stu_score相同时,认为二者重复;
当语句是select distinct stu_score,stu_name时,必须分数和名字一样,才认为二者重复。
4. union查询(联合查询)
将多条 select 语句合并到一起,称为联合操作。
使用 union 关键字,联合两个 select 语句即可。
【举个栗子】要在表中查询给php0228班和php0331班上课天数最多的两个老师,语句为
select teacher_name,days from teacher_class where class_name=‘php0228‘ order by days desc limit 1;
select teacher_name,days from teacher_class where class_name=‘php0331‘ order by days desc limit 1;
这两个分开的语句的确可以查找出想要的结果,但是若要做联合查询呢?
语句是 :(语句1)union(语句2);
但这种写法会将重复的记录删除,若想保留所有记录,哪怕重复,可用一下格式:
(语句1)union all (语句2);
tip:在使用union的情况下,排序有几点需要注意。
子语句的排序:
① 将子语句包裹在子括号内;
② 子语句的order by只有在配合limit使用时,才生效。原因是:union会对没有limit的字句的order by优化(忽略)。
若相对union的结果进行排序,使用如下语句:
(语句1)union(语句2)order by days ;
注意: ① 多个 select 语句的检索到的字段数必须一致;更严格的是,数据类型上也应该要求一致(但是mysql内部会做类型转换处理,要 求是能转换成功)。
标签:begin 参考 没有 关键字 width blog images com idt
原文地址:http://www.cnblogs.com/zhqiang/p/6895738.html