标签:跳过 break 开头 提高效率 执行 [1] 方案 模块 ext2
字符串
作为人机交互的途径,程序或多或少地肯定要需要处理文字信息。如何在计算机中抽象人类语言的信息就成为一个问题。字符串便是这个问题的答案。虽然从形式上来说,字符串可以算是线性表的一种,其数据储存区存储的元素是一个个来自于选定字符集的字符,但是字符串由于其作为一个整体才有表达意义的这个特点,显示出一些特殊性。人们一般关注线性表都会关注其元素和表的关系以及元素之间的关系和操作,而字符串常常需要一些对表整体的关注和操作。
字符串的基本概念如长度,比大小,子字符串等等这些,只要有点编程基础的人都懂就不多说了。关于字符串的抽象数据类型大概可以拟出这样一个ADT:
ADT String:
String(self,sseq) #基于字符序列sseq创建字符串
is_empty(self) #判断是否是空串
len(self) #返回字串长度
char(self,index) #返回指定索引的字符
substr(self,start,end) #对字符串进行切片,返回切得的子串
match(self,string) #查找串string在本字符串中第一次出现的位置,未出现返回-1
concat(self,string) #做出本字符串与另一字符串string的拼接串
subst(self,str1,str2) #做出将本字符串中的子串str1全部替换成str2的字符串
字符串类基本的操作就是以上这些了,其中大部分操作是比较简单的,只有match和subst操作可能比较复杂(因为牵扯到子串索引问题,后面会讲到这个)。
■ 字符串的基本实现
因为字符串本质上是一个线性表,根据线性表的分类,很容易想到可以采用顺序表或者链表两种形式来实现字符串。实际上的字符串储存形式可以居于两者中间,即将字符序列分段保存在一组储存块间并且用链接域把这些储存块连接起来。在C语言以及其他一脉相承的语言中,短一点的字符串通常还是会用顺序表的形式来实现。在顺序表中我们也知道,分成一体式顺序表和分离式顺序表,通常分离式顺序表还是可以动态扩容的动态顺序表。这个可以根据需要实现的需求来看。如果想让字符串是一种创建时就必须指定大小的类型的话,就可以通过一体式顺序表来实现,比如Python中的str类型是不可变类型,所以应该使用一体式顺序表实现的。在其他一些语言中可能要求字符串变量可以动态地变化内容,这样子的话就要用动态顺序表了。
此外,就不可变字符串的实现而言,还牵扯到一个问题就是串在何处终止。我们有两种解决方案,一是学顺序表在字符串中维护一些额外的信息比如串的长度,二是在字符串尾自动加上一个代表终止的编码,这个编码不能当做任何可显式的字符。C语言以及继承了C的Python中都是采用了第二种方法。
关于字符串的编码,在比较年轻的语言如Python,Java中都默认使用了Unicode字符集来编码字符串,而老语言中大多都还在默认使用ASCII和扩充ASCII。
■ Python中的字符串
下面从数据结构和算法的角度说明一下python中的字符串。关于字符串的一些具体操作方法和性质我之前也提到过好多,可以参看其他文章。
首先Python中的字符串是一个不可变的类型, 对象的长度和内容在创建的那一刻就固定下来,因为不同对象长度和性质可能有所不同,Python中对于字符串变量的表示是这样的:一块顺序表中被大致分成三个区域,分别盛放该字符串的长度信息,字符串的其他一些信息(比如提供给解释器用的,用于管理对象的信息)以及字符储存区。
str类的一些操作基本分成三类,获取str对象信息(如len,isdigital等等方法)、基于已有对象或凭空创造新的str对象(比如切片,格式化,替换等等)、字串检索(比如count,endwith,find等等)
在这些操作中,像len,访问字符等显而易见是O(1)操作,而其他操作基本上都是要扫描整个字符串的,包括检索,in,not in,isdigital等等都是O(n)的操作。
■ 字符串匹配
字符串和其操作的基本实现和线性表是类似的,就不多说了。但是着重需要讲一下的,是字符串匹配的问题。
字符串匹配看起来好像是很简单的一桩事,但实际上是非常有学问在里头的。首先是其重要性,在实际应用中用的地方实在是太多了。包括文本处理时的查找,对垃圾邮件的过滤,搜索引擎爬区数以亿万计的网页,甚至是做DNA检测时对于四种碱基序列的匹配(据说当今世界有一半以上的计算能力都在被用来匹配DNA序列)。因为字符串匹配如此重要,所以对这方面的研究非常多,也有各种各样的匹配算法纷繁复杂。下面说明两种匹配算法。
在介入具体算法之前,先明确几个概念。目标串是指被匹配的,长度较长的,作为素材的字符串。模式串是指去匹配的,长度较短的,作为工具的串。一般目标串长度总是大大大于模式串。
● 朴素匹配算法
朴素匹配顾名思义是非常简单的算法。它的基本想法很朴素,基于两点:
1. 用模式串从左到右依次逐个字符匹配目标串
2. 发现不匹配时结束此轮匹配然后考虑目标串中当前匹配中字符的下一个字符
朴素匹配算法实现十分简单:
def naive_matching(t,p): m , n = len(p) , len(t) i , j = 0 , 0 while i < m and j < n: if p[i] == t[j]: i , j = i+1 , j+1 else: i, j = 0 , j - i + 1 if i == m: return j - i #这里return的是模式串在目标串中的位置 return -1
容易看出,这样的一个算法其效率比较低。造成低效率的主要原因是执行过程中会发生回溯。即不匹配的时候模式串会只移动一个字符,到目标串的下一个字符开始又从下标0开始匹配。最坏的情况就是每次匹配只有到模式串遍历到最后一个字符才发现不匹配,然后匹配又发生在整个目标串的最后面时。比如模式串是00001,目标串是00000000000000000000000000001这样子的情况。对于长m的模式串和n的目标串,这种最坏情况需要做n-m+1轮比较,每次比较又需要进行m次操作,总的来看复杂度是m*(n-m+1)为O(m*n)即平方复杂度。
朴素匹配算法 的效率低,究其根源在于把每次字符匹配看做是一次独立的动作,而没有利用字符串本身是一个整体的特点。在数学上这样做是认为目标串和模式串里的字符都是完全随机的量,而且有无穷多种取值的可能,因此两次模式串对目标串的比较是互相独立的。为了改进朴素算法,下面说明一下KMP算法。
● KMP算法
KMP算法是由Knuth,Pratt和Morris提出的,所以KMP其实是人名。。
KMP算法的基本思想是在每轮模式串对目标串的匹配中都获取到一定信息,根据这些信息来跳过一些轮的匹配从而提升效率。比如看下面这个实例,目标串为ababccabcacbab,模式串是abcac。
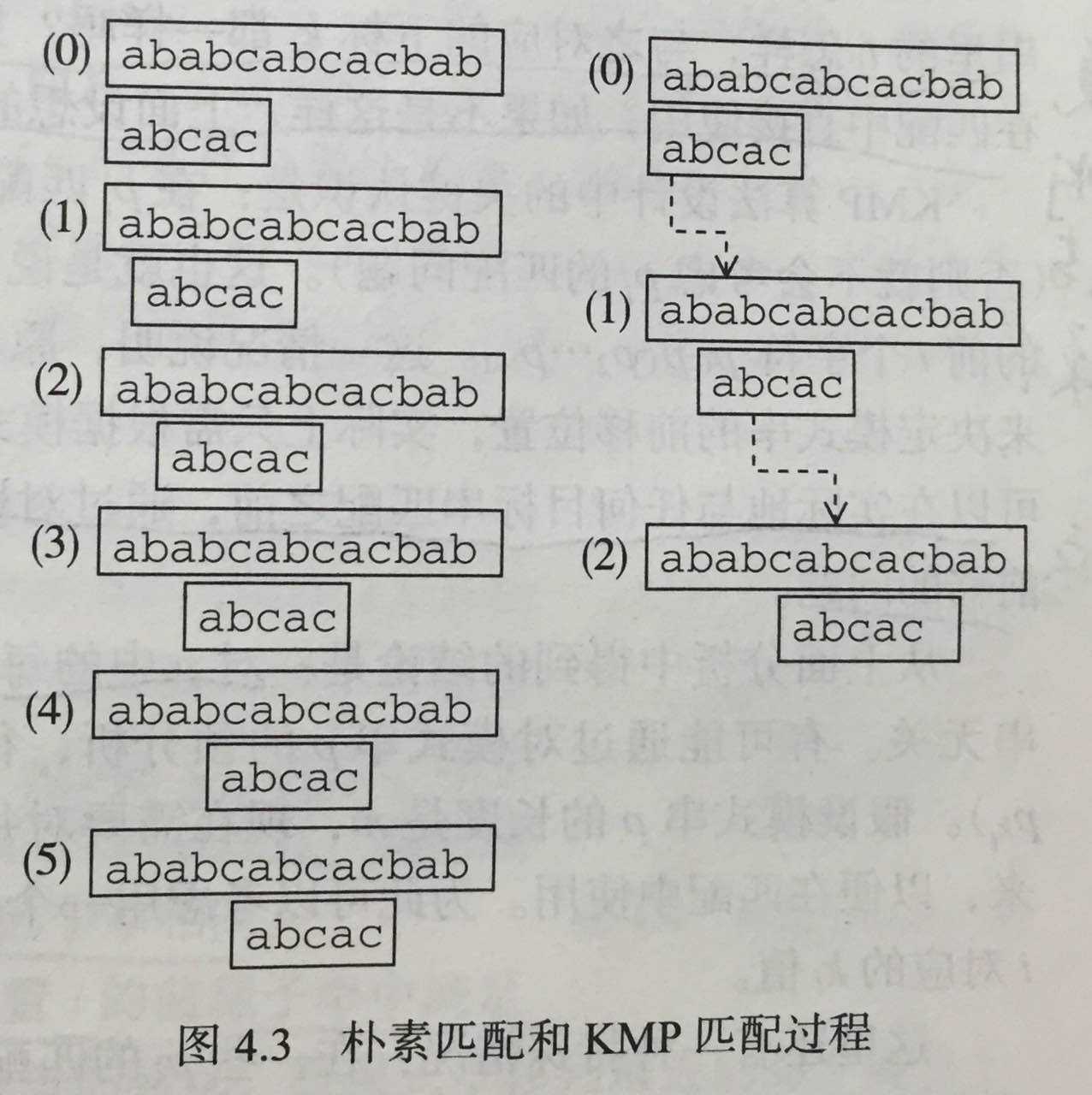
在完成第一轮匹配之后,其实可以有这样一个判断:在模式串的第2位(注意,说的是下标2,下同)匹配失败了,而之前的第0位和第1位都是匹配的,这就说明第1位字符是b,而因为第0位和第1位字符不一样是a,所以实际上根本不需要把模式串对准目标串的第1位匹配,肯定匹配不上。所以左边的(1)是不必要的,正如右边KMP过程显示的那样,模式串直接右移了两个字符到目标串的第2位匹配。同理,在朴素过程中的(3),(4)也是不需要的,因为在KMP过程的(1)中,模式串第0位到第三位完全匹配,到第四位匹配失败。因为模式串本身后面还有个,为了不错过正确匹配,这次只移动了三个字符到达了右边的(2)情况。试想,模式串是abcdc,而目标串是ababcdb...的话这里就可以是右移4个字符了。
归纳,抽象一下上面的KMP匹配方法,重点就是要找到前一次匹配中匹配失败的那个字符所在位置,然后从模式串中分析出一些信息,综合两者把模式串进行“大跨步”的移动,省去一些无用功。
那么就来了一些问题。比如,如何确定我可以移动几个字符?另外所谓“从模式串中分析出一些信息”太抽象了,具体怎么分析,要得到哪些信息?
为回答这些问题,我们需要把模式串和目标串抽象化。目标串定义为"t0t1t2...tj...",模式串定义为"p0p1...pi..."。首先要明确一点,就是不论目标串是怎么样的,对于固定的模式串而言,在模式串中特定的字符上匹配失败的话,其进一步移动的字符数都是固定的。这听起来有点悬,但是细想,当pi匹配失败时就意味着p0到pi-1为止的所有字符都已经匹配成功。这也就是说我们已经可以确定一部分目标串的内容了。在这部分内容的基础上确定模式串可以后移几个字符也就不是那么不可思议了。这也从算法上给出了一个清晰的信号:在某个特定的字符匹配失败时向后移动几格,是模式串自身的性质,跟要匹配的目标串无关,所以在正式匹配之前我们可以先计算出模式串所有位置匹配失败时应该移动几个字符,以这组数据帮助提升正式匹配时的效率。姑且称这个分析模式串的过程为模式串预处理吧。预处理应该产出一个长度和模式串一样长的列表pnext,pnext中的每一项代表着对应位置的字符pi匹配失败时,从p0到pi-1为止的子串中最大相同前后缀的长度(最大相同前后缀的概念后面再详细说)
模式串预处理时还有可能会遇到一些特殊情况,比如对于任何模式串的首位,因为首位就匹配失败的话不存在之前匹配成功的串,也就无从谈起前后缀,所以一般规定其值为-1。
那么为什么要这么构造pnext呢?来看这张书上的图

当pi和tj匹配失败时,由于模式串第0位到第i-1位和目标串中相同,所以目标串也可以写成(1)这种形式,然后把模式串向右移动去进行下一轮匹配的话应该需要找到一个位置k,使得当pk和tj在匹配时,模式串中的第0位到第k-1位可以和目标串中的pi-k到pi-1位完全一致。而因为pi-k到pi-1是模式串的一个后缀,p0到pk-1又是模式串的一个前缀(后缀和前缀的概念就是s[n:-1]+s[-1]以及s[0:n],其中n为[0,len(s))的任何整数)。这样一来,寻找k的问题就转化成了确定这两个相同前后缀的长度的问题。显然,当k越小时表示移动的距离越远,前面也说过为了不错过任何正确匹配,移动应该尽量多次,所以当k有多个取值,即模式串有多个最大相同前后缀时应该取尽量长的(不包括p0到pi-1本身但包括空串,本身表示没有做任何移动而空串表示没有找到相关的最大相同前后缀子串而用p0去匹配tj)
● 如何求pnext
现在问题转化为如何求出pnext或者说如何求出模式串中每一字符匹配失败时,除去其本身而在其前面所有字符组成序列的最大相同前后缀。
对于简单的模式串,比如ababc,我们可以手工来算,规定了第0位是-1,第1位是求“a”的最大相同前后缀显然是0,第2位是求“ab”的最大相同前后缀,也是0;第3位是求“aba”的,因为有相同前缀和后缀“a”,其长度为1,所以是1;第4位类似的是2。最终我们得到的pnext结果是[-1,0,0,1,2]
如果想要通过函数来得到pnext,那么可以考虑通过数学归纳法来解决。即
1. 当pnext[0]时等于-1
2. 假设当pnext[i-1]时等于k-1,那么再为前缀和模式串本身都再算进各自的下一个字符pk和pi。若pk==pi,则自然是最大相同前后缀增加一个字符所以pnext[i]=k。若不相等,就意味着当前的前缀是无论如何也无法和后缀相同了。此时就应该退而求其次,试图在前缀中寻找一个更短的前缀看看能否靠这个短前缀加上一个字符来得到相同的后缀。这里需要注意的是,因为i-1长度下模式串的前后缀时相同的,当我取到那个短前缀(也就是前缀的前缀)时应该意识到其应该也是和后缀的后缀(也就是某个短一些的以pi-1结尾的子串)完全相同的。所以通过这个前缀+一个字符的模式来寻找后缀的后缀+pi的方法是正确的。这一点反映在代码中有点令人费解,今天想了一个下午+半个晚上才在一篇论文当中找到答案。
如此就可以得到生成pnext的函数了:
def gen_pnext(p): i, k, m = 0, -1, len(p) pnext = [-1] * m #初始化pnext while i < m - 1: if k == -1 or p[i] == p[k]: i, k = i + 1, k + 1 pnext[i] = k else: k = pnext[k] #这里就是所谓的费解的地方。一开始怎么也没想到前缀的前缀和后缀的后缀是相同的这一点,导致纠结为什么在前缀中直接取一个小前缀而不是一点点缩小前缀 return pnext
将一个模式串作为参数传给这个函数就可以得到这个模式串对应的pnext列表,根据这个列表就可以帮助之后的匹配了。哪里出现了匹配失败,查询pnext列表得到那个位置字符的k值,然后让模式串的p[k]号字符对准之前失败处目标串的那个字符,进行下一轮匹配。
比如可以套用上面那个abcac的例子,如果它去匹配目标串ababcabcacbab,第一次失败在第2位,其k值是0,所以就把第0位的a对准目标串中第2位的a,进行第二次匹配;第二次匹配失败在第4位的c,k值是1,就把p[1]的b对准目标串的第6位的b进行第三次匹配。第三次匹配获得成功。
把上述过程抽象化一下,结合pnext的生成函数就可以得到完整的KMP算法的表达了:
def matching_KMP(t,p,pnext): j,i = 0,0 n,m = len(t),len(p) while j < n and i < m: if i == -1 or t[j] == p[i]: #i=-1的情况只可能是第一个字符,而p[i]正是之前所说的,p[k]移动到上一次匹配出错的地方的那个p[k] j,i = j+1,i+1 else: i = pnext[i] if i == m: #如果i=m了,表明全部匹配完成 return j - i return -1
再来看一下KMP算法的复杂性。首先是生成pnext的函数时间复杂性是O(m),m为模式串长度。匹配函数结构和生成pnext函数还蛮像的,其时间复杂度是O(n),n是目标串的长度。综合起来看,整个MSP算法的复杂度就是O(m+n)。因为一般情况下m<<n,所以近似认为复杂度就是O(n)。绕了这么一大圈,终于把朴素匹配的O(n**2)给降到了O(n)。。
● 生成pnext函数的改进
在pnext的生成算法中,设置pnext[i]的那部分还可以再改进一下子。因为在匹配失败的时候一定会有pi != tj,如果此时pi == pk那么就可以说明pk和tj不用比较,肯定是不同的。即分析出最大相同前后缀的前缀的后一个字符和发生匹配失败的那个字符如果相同,那么就没有必要把模式串右移pnext[i]个字符了,反正也是匹配失败的,而是可以直接右移pnext[k]个字符。这一修改可以把模式串移动得更远,有可能提高效率(虽然我没看懂。。)。修改后的函数如下:
def gen_pnext2(p): i, k, m = 0, -1, len(p) pnext = [-1] * m while i < m - 1: if k == -1 or p[i] == p[k]: i, k = i + 1, k + 1 if p[i] == p[k]: #多了这个判断,这里的p[i]和p[k]不一定是前后缀中相同的内容,前面i和k都已经+=1了。所以当两者相同时有这么个改进点 pnext[i] = pnext[k] else: pnext[i] = k else: k = pnext[k] return pnext
● KMP适合场景以及其他的算法
许多场景中需要一个模式串反复地匹配多个目标串,此时可以一次性地生成模式串的pnext然后重复使用提高效率。这是最适合KMP算法的场景
因为执行中不回溯,所以KMP算法也支持一边读入一边匹配,不回头重读就不需要保存被匹配的串。在处理从外部获得大量信息的场景也很适合KMP算法。
另外还有其他的一些算法,比如BM算法在其他一些场景中可能会比KMP算法要快很多。总之字符串匹配算法这是个大学问。
■ 正则表达式
以上说到的串匹配,其实只是基于固定模式串的简单匹配。实际问题中的匹配需求可能要远比其可提供的匹配方式复杂。另外,之前有提到过关于模式匹配的问题,之前所说的子串简单匹配其实就是模式匹配的一种特殊情况,而真正的模式匹配往往要通过一个模式串来匹配得到一组目标串。当目标串很多很长,甚至有无穷多的可能的时候,就需要设计一种有效的匹配方法。
一种有效的方法就是设计一种模式语言,以一个字符串的形式来表达一种模式,然后用这种模式串来匹配多个目标串。关于模式语言,前人有过很多研究,但是当设计的模式语言越来越复杂的时候,匹配的算法可能就只能设计出直属复杂性的算法,模式匹配问题在这种算法下会成为一种耗费很高,甚至不可解的问题。也就是说,这种情况下的模式语言是没有价值的。实际情况中,有意义的模式语言是描述能力和处理能力之间得到的平衡。
正则表达式就是经过了实践检验,几乎已经成为了一种技术规范的模式语言。正则表达式的基本成分也是字符,但是它在设定上把字符分成了普通字符和有特殊意义的字符。对于普通字符,在正则表达式中指代的就是它本身,对于特殊字符,就有特殊的意义。如果想要把特殊字符变成普通字符就需要在正则表达式中添加转义符号。正则表达式有基本的性质如下:
正则表达式中的普通字符只和该字符本身匹配
如果有正则表达式α和β,那么他们之间可以形成组合,"αβ"这个正则式代表顺序组合匹配,比如α能匹配字符串s,β能匹配t,那么这个正则式就可以匹配s+t
α和β还有选择组合"α|β"。这个正则既可以匹配s也可以匹配t
正则表达式有通配符的设定,即用某种符号代表一切可能字符,配合上对于其数量匹配的一些符号可以匹配任意长度,任意内容的相关字符。比如".*"就是这样一个正则式
关于正则表达式的一些特殊字符的具体意义和用法不多说了,可以参见python的re模块那篇笔记,这里给出几个书上的例子来体验一下。比如"abc"只能和"abc"匹配,"a(b*)(c*)"可以匹配所有一个a开头后后面跟着若干个b然后跟着若干个c的字符串,"a((b|c)*)"可以匹配任何一个a开头,后面由任意多个b和c组成的字符串。
● 正则表达式的实现算法
真正的正则式实现算法肯定是非常复杂的,这里给出一种简化版的正则表达式,包括了一些正则中常用的特殊符号并且试图用python来对这样一个简化正则系统进行实现。
这种简化版的正则系统中的特殊符号包括:
. 匹配任意单个字符
^ 从目标串的开头开始匹配
$ 匹配到目标串的结尾
* 在星号前的单个字符可以匹配从0到任意多个相同字符
这个正则系统的正则式的实例:"a*b." ; "^ab*c.$" ; "aa*bc.*bca"
下面考虑一种朴素的正则匹配算法,给出一个函数match,将正则式和目标串作为参数传递进去然后返回匹配到的子串在目标串中的位置。
def match(re,text): rlen = len(re) tlen = len(text) def match_at(re,i,text,j): """检查text[j]开始的正文是否与re[i]开始的模式匹配, 之所以不设置成默认就从re的头开始匹配是因为要留出接口来处理星号符 """ while True: if i == rlen: #表示模式串匹配到最后为止一直都是匹配成功 return True if re[i] == "$": #如果当前处理中字符的下一字符是$,以为着必须i和j+=1之后两个字符都来到各自串尾上 return i+1 == rlen and j == tlen if i+1 < rlen and re[i+1] == "*": #如果模式串下一个字符是星号,就要进行星号符匹配 return match_star(re[i],re,i+2,text,j) #可以看到re[i]是星号前面的那个字符,i+2是星号后面的那个字符的下标 if j == tlen or (re[i] != ‘.‘ and re[i] != text[j]): """当j==tlen表示匹配到目标串尾但是模式串还是有剩余内容,说明匹配失败 当re的第i位是通配符不是通配符.,而且此位置和目标串不匹配就说明本次匹配失败。需要跳出函数进行下一轮匹配 """ return False i,j = i+1,j+1 def match_star(c,re,i,text,j): """匹配星号符,即当在text中跳过若干个字符c之后检查匹配 """ for n in range(j,tlen): if match_at(re,i,text,n):#每扫描一个目标串中的元素就检查是否开始和模式串中跳过星号的部分匹配,检查到目标串结尾仍然都匹配就可return True了。 return True if text[n] != c and c != ‘.‘: #当发现任何一个没有开始和跳过星号部分匹配,但是却和给定的c不同,c还不是统配符的字符,就表明匹配失败了 break return False if re[0] == "^": if match_at(re,1,text,0): #因为模式串开头是^,说明从头开始匹配。反映到函数中来i应该取1,让模式串从第1位开始匹配目标串 return 1 for n in range(tlen): #这个循环扫描目标串,每次循环体都用模式串从头匹配一部分目标串,目标串渐渐往后缩小。直到有一个匹配出现就中断循环return 出来。 if match_at(re,0,text,n): return n return -1
更多的正则表达式的补充,看了一下还是补充在了re模块的说明中更加合理,就记录在那边了。以上。
标签:跳过 break 开头 提高效率 执行 [1] 方案 模块 ext2
原文地址:http://www.cnblogs.com/franknihao/p/6901321.html