标签:input bsp lin match parse 模块 web data 显示
今日爬取一听/扬天音乐都遇到了某些问题,现在对爬取过程中遇到的问题,做对于自己而言较为系统的补充与解释。主要问题有一下几点:
一:beautiful,urllib等库进行网页解析时,对于目标下的东西无法进行解析与显示
二:正则匹配虽然看过许多,但实际使用时仍然不够熟练,需要大量参考,故而,打算重新整理
三:对于乱码问题,曾在建mysql数据库时,头疼多次,现打算对于网页解析的乱码处理方法做些整理
这次目标是爬取扬天音乐“http://up.mcyt.net/”,需要获取的内容有:歌曲名,歌手以及打开浏览器即可播放的音乐链接(格式大致:http://up.mcyt.net/md5/53/******.mp3)
这个任务相对简单,至少在爬虫道路上遇到了又一新情形,故在此稍加叙述。
现在需要爬取截图中的音乐外接,如下图,以及与之对应的web元素

<label>
<span>音乐外链:</span>
<input type="text" name="name" value="http://up.mcyt.net/md5/53/MTcwMzYwMg_Qq4329912.mp3">
<br>
<span>a网页代码:</span>
<input type="text" name="name" onlick="select();" value="<object height="0" width="0" data="http://up.mcyt.net/p/37823.html"></object>">
<label>
一开始使用的是常规的BeautifulSoup框架进行解析:
response = urlopen(url)
bsObj = BeautifulSoup(response, "html.parser")
li=bsObj.findAll("input",{"type":"text" ,"name":"name"})li=bsObj.findAll("input", {"type": "text" })
print li
但是返回的结果,无法通过li.attrs[‘value‘]获取需求的字符串。原因:以上思路对应的网站元素的格式是
<a "attr1"=“xxx" “attr2”="xxx" "attr3"="xxxx">text</a>
解决方法:
首先解析到<input "attr1"="xxx" "attr2"="xxx">的上一层的target,然后再采用正则的方法获取对应的attrs,
def getInfo(html):
reg=r‘value="(.+?.mp3)" ‘ #传说中的 pattern
mp3=re.compile(reg)
mp3list=re.findall(mp3,html)
return mp3list
现在进入第二部分的整理:正则匹配。
1.Python支持的正则表达式元字符和语法
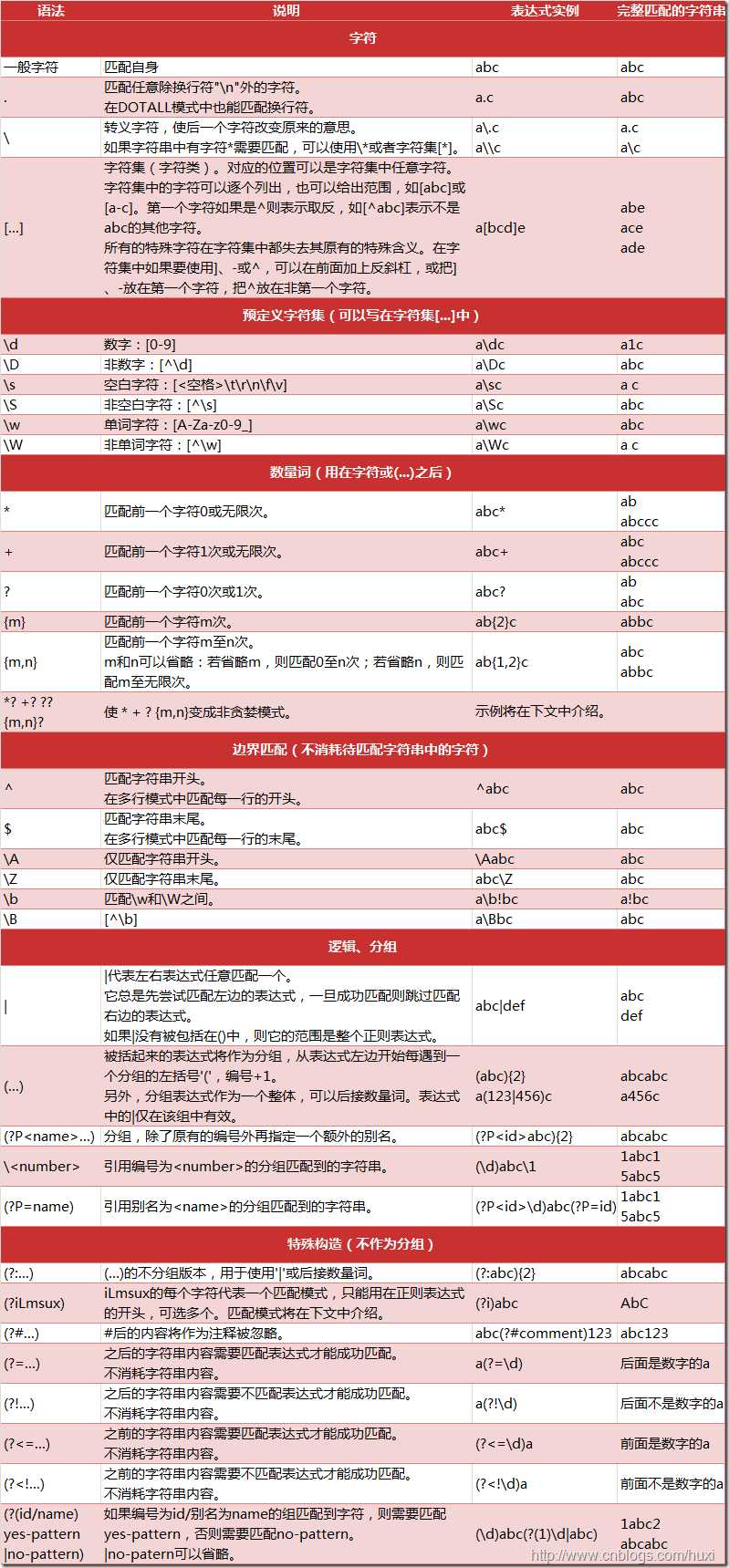
2.re模块:使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
import re# 将正则表达式编译成Pattern对象pattern = re.compile(r‘hello‘)# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回Nonematch = pattern.match(‘hello world!‘)if match: # 使用Match获得分组信息 print match.group()### 输出 #### hello3.本次使用以上 详细的正则可参考:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html#top 和 相关的拓展:www.cnblogs.com/animalize/p/4949219.html
标签:input bsp lin match parse 模块 web data 显示
原文地址:http://www.cnblogs.com/Zhouwl/p/6901225.html