标签:表达 logs 多少 开头 int 正则 对比 数据 awk
grep 摘取字符串(以整行输出)
-a 将文档以text格式进行搜索
-c 计算找到"搜索的字符串"的次数
-i 忽略大小写的不同
-n 顺便输出行号
-v 取反向选择,即显示出没有"搜索字符串"的内容的那一行
[] 无论里面多少个字符,都表示里面某一个字符
[^] 反向选择,即显示出没有里面的字符串的那一行
[-] 表示从什么到什么之间的内容
‘^‘ 表示以什么开头
$ 表示以什么结尾
^$ 显示出空白行
. 表示绝对有一个字符的意思
* 表示重复0个或多个前面的RE字符(注意:它允许空字符)
.* 表示0个或者多个任意字符的意思
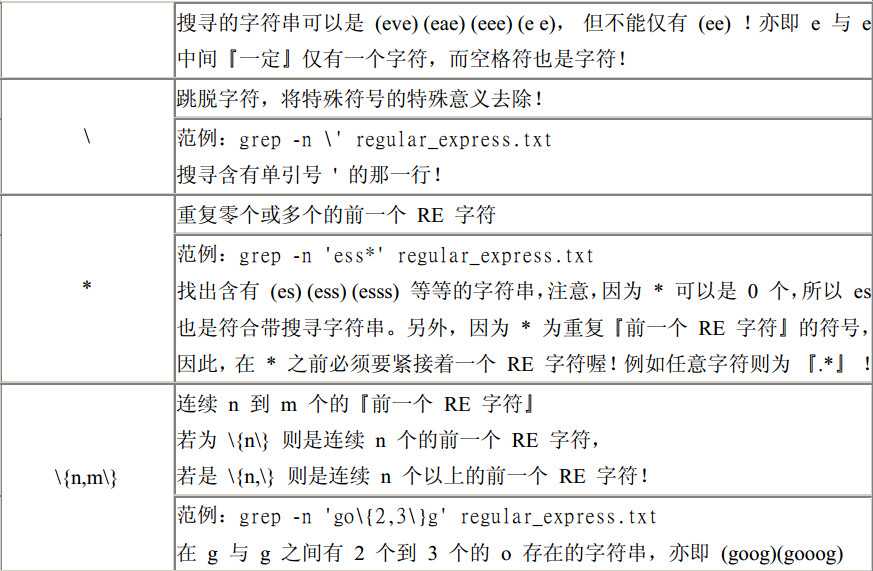
\ 跳脱字符,让某个特殊字符失去意义
{2,} 表示两个以上的前面的RE字符


+ 重复一个或一个以上的前一个RE字符
? 零个或一个的前一个RE字符
| 用或(or)的方式找出数个字符串
() 找出群组字符串
printf 格式化打印
\n 输出新的一行
\r 即Enter按键
\t 水平得【tab】按键
sed -a 新增字符串,这些字符串会在新的一行出现(即目前的下一行)
-c 取代字符串 ,这些字符串取代n1,n2之间的行
-d 删除字符串
-i 插入字符串,这些字符串会在新的一行出现(即目前的下一行)
-s 取代
-p 打印字符串,即显示出来。
AWK
NF:每一行($0)拥有的字段总数
NR:目前awk所处理的是第几行的数据
FS:目前饿分割字符,预设是空格键
diff 对比两个档案之间的差异
pr 文档打印准备
标签:表达 logs 多少 开头 int 正则 对比 数据 awk
原文地址:http://www.cnblogs.com/linhaobin555/p/6910693.html