标签:出栈 ddl 递归算法 tle visit print amp 初始化 png
算法概述
递归算法简洁明了、可读性好,但与非递归算法相比要消耗更多的时间和存储空间。为提高效率,我们可采用一种非递归的二叉树遍历算法。非递归的实现要借助栈来实现,因为堆栈的先进后出的结构和递归很相似。
对于中序遍历来说,非递归的算法比递归算法的效率要高的多。其中序遍历算法的实现的过程如下:
(1).初始化栈,根结点进栈;
(2).若栈非空,则栈顶结点的左孩子结点相继进栈,直到null(到叶子结点时)退栈;访问栈顶结点(执行visit操作)并使栈顶结点的右孩子结点进栈成为栈顶结点。
(3).重复执行(2),直至栈为空。
算法实现
package datastructure.tree;
import datastructure.stack.ArrayStack;
import datastructure.stack.Stack;
public class UnrecOrderBTree implements Visit{
private Stack stack = new ArrayStack();
private BTree bt;
@Override
public void visit(BTree btree) {
System.out.print("\t" + btree.getRootData());
}
public void inOrder(BTree boot) {
stack.clear();
stack.push(boot);
while(!stack.isEmpty()) {
//左孩子结点进栈
while((bt = ((BTree)(stack.peek())).getLeftChild()) != null) {
stack.push(bt);
}
//如果该结点没有右孩子,则逐级往上出栈
while(!stack.isEmpty() &&!( (BTree)stack.peek() ).hasRightTree()) {
bt = (BTree)stack.pop();
visit(bt);
}
//如果该结点有右孩子,则右孩子进栈
if(!stack.isEmpty() && ( (BTree)stack.peek() ).hasRightTree()){
bt = (BTree)stack.pop();
visit(bt);
stack.push(bt.getRightChild());
}
}
}
}
测试:
package datastructure.tree;
/**
* 测试二叉树
* @author Administrator
*
*/
public class BTreeTest {
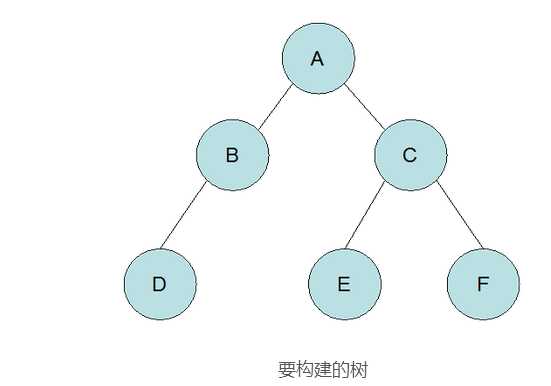
public static void main(String args[]) {
BTree btree = new LinkBTree(‘A‘);
BTree bt1, bt2, bt3, bt4;
bt1 = new LinkBTree(‘B‘);
btree.addLeftTree(bt1);
bt2 = new LinkBTree(‘D‘);
bt1.addLeftTree(bt2);
bt3 = new LinkBTree(‘C‘);
btree.addRightTree(bt3);
bt4 = new LinkBTree(‘E‘);
bt3.addLeftTree(bt4);
bt4 = new LinkBTree(‘F‘);
bt3.addRightTree(bt4);
RecursionOrderBTree order = new RecursionOrderBTree();
System.out.println("\n中序遍历:");
order.inOrder(btree);
}
}
结果如下:
中序遍历:
D B A E
C F
转载至:http://blog.csdn.net/luoweifu/article/details/9079799
标签:出栈 ddl 递归算法 tle visit print amp 初始化 png
原文地址:http://www.cnblogs.com/web424/p/6912759.html