标签:试题 code output attribute href tor head 执行 属性
一、作业要求:
1.在xml文件中创建新闻节点news,包含标题、作者、日期、正文等信息
2.创建HTML模板文件
3.读取xml中所有新闻信息,并使用新闻信息替换模板文件中占位符,从而为每一条新闻生成一个HTML静态页面
二、参考思路:
阶段1:创建xml
添加测试记录不少于三条
阶段2:创建HTML模板文件
阶段3:从xml读取新闻信息,保存在泛型集合中
阶段4:读取模板文件
训练要点:
Reader类
需求说明:
读取HTML模板文件news.template,为使用新闻信息替换其中的占位符做好准备
实现思路:
1. 使用Reader类或InputStream类读取模板文件
2. 通过工具类FileIO的String readFile(String filePath) 实现功能
阶段5:编写生成HTML文件的方法
训练要点:
Writer类
需求说明:
利用替换模板文件后的数据生成HTML文件
实现思路:
1、使用Writer类或OutputStream类完成该操作
2、通过FileIO的void writeFile(String filePath, String str) 实现该功能
阶段6:遍历集合,生成HTML文件
训练要点:
String类的replace() 方法
需求说明:
遍历保存在泛型集合中的新闻信息,替换模板文件中占位符,为每一条新闻生成一个HTML文件
实现思路:
1、通过NewsManager类的toHtml()方法完成该功能
2、替换占位符功能通过String类的replace() 实现
三、创建项目完成作业
1.创建项目,编写需要的文件(结构如下)
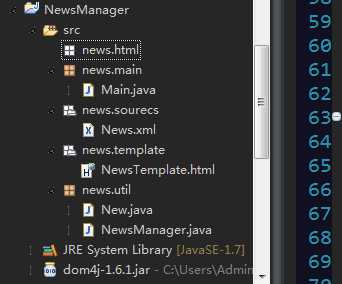
2.XML文件和HTML模版展示
1 <?xml version="1.0" encoding="UTF-8"?> 2 <news> 3 <new title="美国男篮邀请考辛斯参加训练营 厄文小乔丹同获邀" author="刘潇潇" createTime="2013-04-16"> 4 <!-- <title>美国男篮邀请考辛斯参加训练营 厄文小乔丹同获邀</title> 5 <author>刘潇潇</author> 6 <createTime>2013-04-16</createTime> --> 7 <content>根据最新消息,美国男篮已向几位优秀的年轻球员发出了训练营邀请,这些球员包括国王的考辛斯,快船的小乔丹,骑士的厄文,泽勒,威特斯等。美国男篮的迷你训练营将在7月末举行,去年夏天考辛斯曾参加训练营,和美国男篮的主力阵容进行对抗,当时美男篮主管科朗吉洛表示,考辛斯还有很多方面不成熟,需要更多的成长。对此考辛斯很不高兴,还找科朗吉洛质问。不过现在,现在知情人透露,在美国男篮高层进行了诸多争论后,考辛斯还是得到了邀请名额,参加这次迷你训练营,他将有机会正式入选美国队。你得把过去埋葬掉,然后继续向前,”科朗吉洛说道,“他受到了邀请,他绝对在我们的名单上。新的一年,新的夏天,新的机会。”考辛斯在国王效力了3个赛季,是目的前全联盟最有进攻才华的大个子球员,他具备在内线得分的多种手段,也有远距离投射能力,又会控球和传球。上赛季考辛斯场均可以交出17.1分,9.9篮板的数据。不过考辛斯最大的问题在于他的易怒性格,情绪不稳定,和自己的俩个前任教练斯玛特,威斯特法尔都发生过争吵,和队友,其它队友的人事,媒体也都有过争执。在被问到最喜欢考辛斯打球的那些方面时,科朗吉洛回答:“个头,天赋。”快船的中锋小乔丹也透露自己同样收到邀请。“我很高兴能有这次机会,”乔丹说道,“我得把握住它。“乔丹上赛季场均数据是8.8分,7.2篮板,137盖帽。骑士的全明星控卫厄文和俩个队友威斯特,泽勒也都收到了邀请。美国男篮举办迷你训练营的地点在拉斯维加斯,时间从7月23日到26日。</content> 8 </new> 9 <new title="还在指望房贷打折?放弃吧,这个信号你要看懂" author="何小桃" createTime="2017-05-28"> 10 <!-- <title>还在指望房贷打折?放弃吧,这个信号你要看懂</title> 11 <author>何小桃</author> 12 <createTime>2017-05-28</createTime> --> 13 <content>房价收入比高得离谱的今天,按揭买房已经成为了绝大多数人的选择。因此,房贷利率成为了买房者关心的问题。 14 每经小编(微信号:nbdnews)了解到,近半年来,很多城市的银行都上调了房贷利率折扣,其中部分城市的房贷利率已经执行基准利率,而北京的二套房房贷利率更是执行基准利率上浮20%。 15 有网友就不无焦虑地说到,“有钱人还是一下子买得起,穷人负担更重了”。 16 那么,房贷利率为何上升呢?一个重要的原因是,一向不差钱的银行也“没钱”了。 17 银行成本收益出现倒挂 18 当然,银行缺钱更准确的说法,不是银行没钱了,而是“钱贵”了。 19 5月22日,上海银行间同业拆借利率(Shibor)一年期品种利率报4.3024%,创逾两年以来最高位,首次高于4.30%的上海银行间市场一年期贷款基础利率(LPR)。此后,1年期Shibor持续走高,截至5月27日,报4.3544%,已经高于央行4.35%的1年期贷款基准利率。</content> 20 </new> 41 </news>
1 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> 2 <html> 3 <head> 4 <title>{title}</title> 5 <meta http-equiv="keywords" content="keyword1,keyword2,keyword3"> 6 <meta http-equiv="description" content="this is my page"> 7 <meta http-equiv="content-type" content="text/html; charset=gbk"> 8 <!--<link rel="stylesheet" type="text/css" href="./styles.css">--> 9 </head> 10 <body> 11 <table align="center" width="70%" border="1"> 12 <tr> 13 <td width="10%"> 14 <b>标题:</b> 15 </td> 16 <td> 17 {title} 18 </td> 19 </tr> 20 <tr> 21 <td width="10%"> 22 <b>作者:</b> 23 </td> 24 <td> 25 {author} 26 </td> 27 </tr> 28 <tr> 29 <td width="10%"> 30 <b>时间:</b> 31 </td> 32 <td> 33 {createTime} 34 </td> 35 </tr> 36 <tr> 37 <td width="10%"> 38 <b>内容:</b> 39 </td> 40 <td> 41 {content} 42 </td> 43 </tr> 44 </table> 45 </body> 46 </html>
3.解析XML文件的方法(使用DOM4J解析XML文件,并用Map集合保存)
1 //声明泛型集合用于保存读取的xml文件 2 Map<String,New> news = new HashMap<String, New>(); 3 4 //读取xml文件保存到泛型集合 5 public void readXml(){ 6 //声明news文档 7 Document newDoc = null; 8 try { 9 //加载news的DOM树 10 SAXReader reader = new SAXReader(); 11 newDoc = reader.read(new File("src/news/sourecs/News.xml")); 12 } catch (DocumentException e) { 13 e.printStackTrace(); 14 } 15 //获取XML的根节点 16 Element root = newDoc.getRootElement(); 17 //遍历所有的new标签 18 for (Iterator<?> itNews = root.elementIterator(); itNews.hasNext();) { 19 Element newEle = (Element)itNews.next(); 20 //获取title、author、createTime属性 21 String title = newEle.attributeValue("title"); 22 String author = newEle.attributeValue("author"); 23 String time = newEle.attributeValue("createTime"); 24 //遍历content标签 25 for (Iterator<?> contents = newEle.elementIterator(); contents.hasNext();) { 26 Element content = (Element) contents.next(); 27 //获取content标签的值 28 String text = content.getText(); 29 //实例化New对象,保存新闻信息 30 New newCon = new New(title,author,time,text); 31 //添加到泛型集合 32 news.put(title, newCon); 33 } 34 } 35 }
4.读取模版内容并替换新闻
1 //读取新闻模版并替换指定内容 2 public void editHtml(){ 3 this.readXml(); 4 try { 5 //创建输入流读取模版文件 6 FileReader fr = new FileReader("src/news/template/NewsTemplate.html"); 7 BufferedReader reader = new BufferedReader(fr); 8 //使用StringBuffer类 9 String line = null; 10 StringBuffer sbf = new StringBuffer(); 11 //循环读取并追加字符 12 while((line=reader.readLine())!=null){ 13 sbf.append(line+"\n"); 14 } 15 //遍历Map集合提取news 16 Set<String> titles = news.keySet(); 17 Iterator<String> it = titles.iterator(); 18 while(it.hasNext()){ 19 String title = it.next();//提取key 20 New new1 = news.get(title); 21 //替换内容 22 String str = sbf.toString(); 23 str = str.replace("{title}", new1.getTitle()); 24 str = str.replace("{author}", new1.getAuthor()); 25 str = str.replace("{createTime}",new1.getTime()); 26 str = str.replace("{content}",new1.getContent()); 27 //创建输出流写出html文件 28 FileWriter fw = new FileWriter("src/news/html/"+new1.getTitle()+".html"); 29 BufferedWriter writer = new BufferedWriter(fw); 30 writer.write(str); 31 writer.close(); 32 fw.close(); 33 reader.close(); 34 fr.close(); 35 } 36 } catch (FileNotFoundException e) { 37 e.printStackTrace(); 38 } catch (IOException e) { 39 e.printStackTrace(); 40 } 41 System.out.println("已创建Html文件!\n文件在src/news/html文件夹下!"); 42 }
5.最终生成的HTML文件
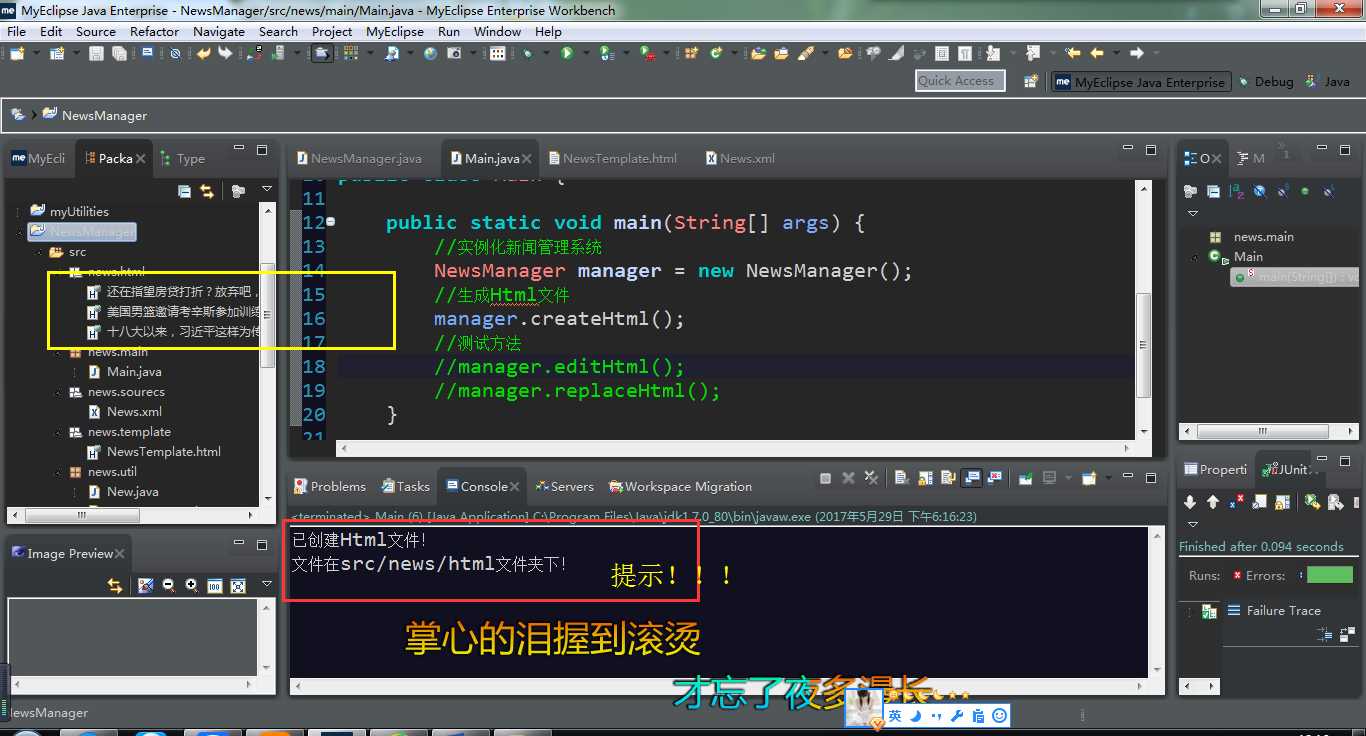
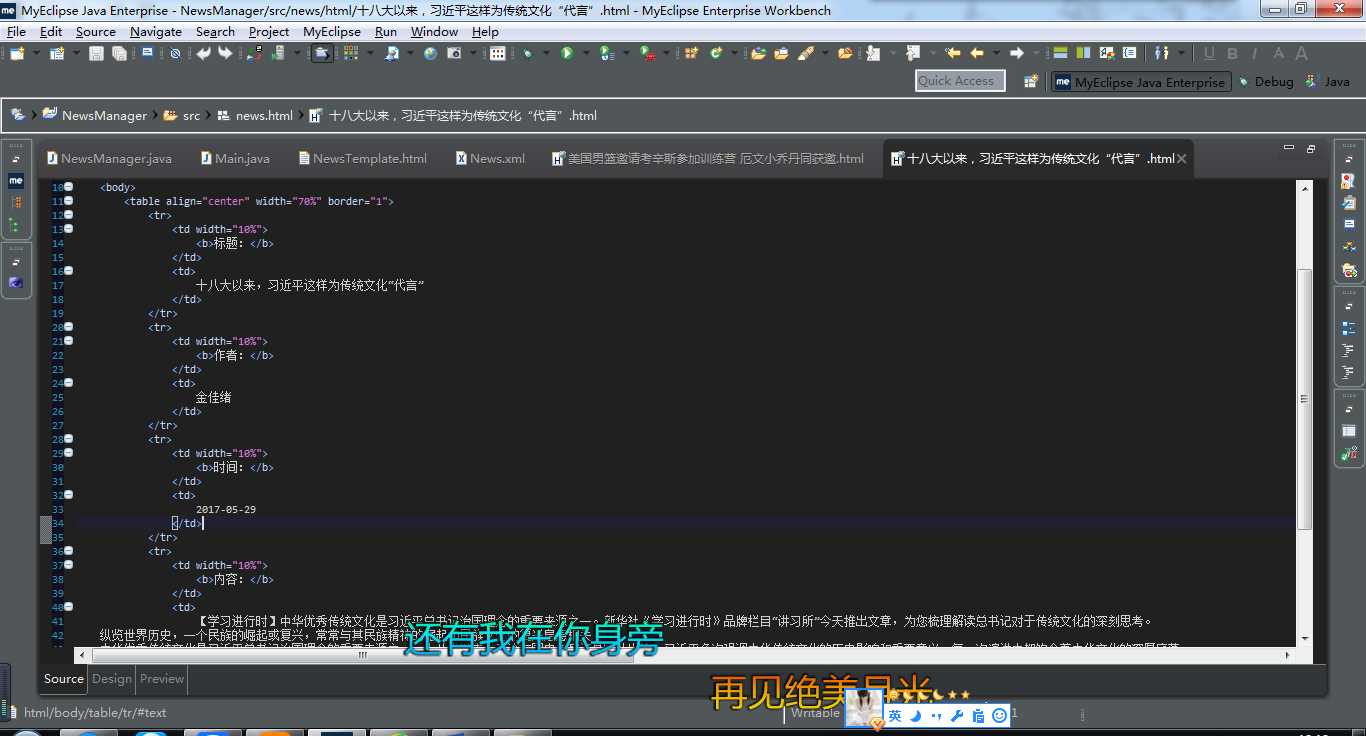
【U1结业机试题】新闻内容管理系统:解析XML文件读取Html模版生成网页文件
标签:试题 code output attribute href tor head 执行 属性
原文地址:http://www.cnblogs.com/tengqiuyu/p/6918683.html