标签:read cart each 网址 head 技术分享 sse random sel
抓取漫画的网址是:sf互动传媒
抓取漫画的由来也是看了知乎上有人说用爬取漫画,然后自己也玩玩
首页中每个漫画的url是类似这样存储的:
<tr> <td height="30" align="center" bgcolor="#FFFFFF"> <a href="http://comic.sfacg.com/HTML/KOL/" target="_blank">K.O.I 偶像之王</a> </td> </tr>
然后用lxml通过cssselect(tr>td>a)将能用到的解析出来,然后解析出来会有很多其他的页面的url和信息,然后我是通过url中包含"/mh/"或者是"/HTML/"进行过滤的
比较蠢的办法了
然后通过对象,将过滤出来的漫画的url和漫画的名字保存在一个这样的类中,然后通过列表进行存储
class Cartoon(): url = None name = None
然后用随便一个漫画作为例子:勇者赫鲁库
漫画一共很多章,并且所有章的信息都在如下标签中包含
<ul class="serialise_list Blue_link2">....</ul>
然后通过BS将每一章的信息进行存储,然后可以看到其完整的url是:http://comic.sfacg.com/HTML/YZHLK/096/
然后每一章会有很多的page,并且每一章的内容是ajax进行加载的,然后从检查->网络中可以看到有一个这样的请求
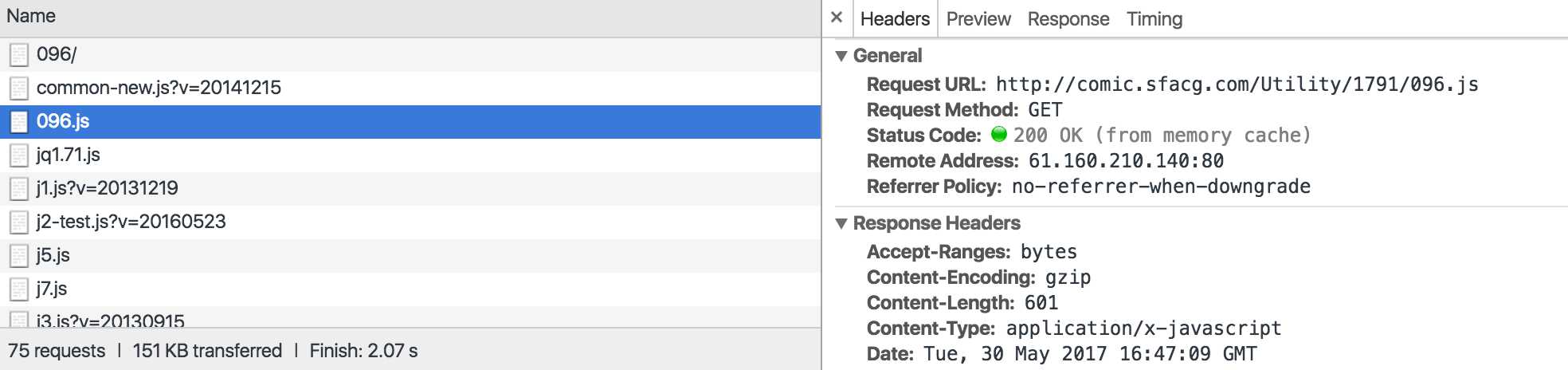
然后请求的response里面包含本章的所有图片,然后只需将在每一章的页面中将.js接口找到,然后将本章的图片信息存储,然后就可以得到本章的图片信息,然后存储到本地
# -*- coding: utf-8 -*- import re import urllib import urllib2 import os import stat import itertools import re import sys import requests import json import time import socket import urlparse import csv import random from datetime import datetime, timedelta import lxml.html from zipfile import ZipFile from StringIO import StringIO from downloader import Downloader from bs4 import BeautifulSoup from HTMLParser import HTMLParser from itertools import product import sys reload(sys) sys.setdefaultencoding(‘utf8‘) URL = ‘http://comic.sfacg.com‘ picture = ‘http://coldpic.sfacg.com‘ class Cartoon(): url = None name = None def download(url, user_agent=‘wswp‘, num_try=2): headers = {‘User_agent‘: user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print ‘Download error‘, e.reason html = None if num_try > 0: if hasattr(e, ‘code‘) and 500 <= e.code < 600: return download(url, user_agent, num_try - 1) elif e.code == 403: return None return html def get_section_url(url): html = download(url) if html == None: return None soup = BeautifulSoup(html, "html.parser") results = soup.find_all(name=‘ul‘, attrs={‘class‘: ‘serialise_list Blue_link2‘}) res = r‘<a.*?href="([^"]*)".*?>([\S\s]*?)</a>‘ links = re.findall(res, str(results),re.S | re.M) return links def get_section_page(url): html = download(url) if html == None: return None soup = BeautifulSoup(html, "html.parser") results = soup.find_all(name=‘script‘, attrs={‘type‘: ‘text/javascript‘}) tt = len(results) js = results[tt-1] mm = js.get(‘src‘) if mm == None: result = soup.find_all(name=‘script‘, attrs={‘language‘: ‘javascript‘}) js1 = result[1] mm = js1.get(‘src‘) html1 = download(URL+mm) list = html1.split(‘;‘) List = [] for each in list: if ‘picAy[‘ in each: src = each.split(‘=‘) List.append(picture+src[1][2:-1]) return List def download_cartoon(url, cartoon_name,Section,num): path = "自己定义的路径"+cartoon_name if not os.path.exists(path): os.mkdir(path) path = path + "/"+Section if not os.path.exists(path): os.mkdir(path) content = requests.get(url).content with open(path + ‘/‘ + str(num) + ‘.jpg‘, ‘wb‘) as f: f.write(content) print "Downloading cartoon_name " + path + str(num)+ "下载完成" f.close() if __name__ == ‘__main__‘: cartoon_list = [] html = download(URL) tree = lxml.html.fromstring(html) results = tree.cssselect(‘tr > td > a‘) for each in results: ti = each.get(‘href‘) if ‘/mh/‘ in ti or ‘/HTML/‘ in ti: if each.text_content() != "": cartoon = Cartoon() cartoon.url = each.get(‘href‘) cartoon.name = each.text_content().replace(‘ ‘,‘‘) cartoon_list.append(cartoon) for each in cartoon_list: print each.url print each.name links = get_section_url(each.url) links = list(reversed(links)) section = 0 for link in links: ul = URL + link[0] List = [] List = get_section_page(ul) section = section + 1 Section = r‘第‘+ str(section) + r‘章‘ num = 1 for mm in List: #print mm download_cartoon(mm,each.name,Section,num) num = num + 1 print each.name + Section + "下载完成"+str(num-1)+"张"
标签:read cart each 网址 head 技术分享 sse random sel
原文地址:http://www.cnblogs.com/chenyang920/p/6922162.html