标签:ons load 最优 平面 and 分类 处理 strong ict
svm是一种分类算法,一般先分为两类,再向多类推广一生二,二生三,三生。。。
大致可分为:
线性可分支持向量机
? 硬间隔最大化hard margin maximization
? 硬间隔支持向量机
? 线性支持向量机
? 软间隔最大化soft margin maximization
? 软间隔支持向量机
? 非线性支持向量机
? 核函数kernel function
基本概念:
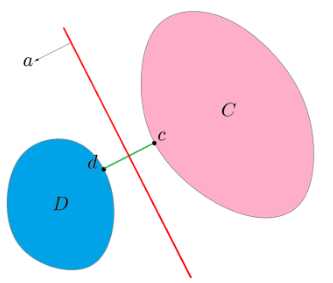
分割超平面
设C和D为两不相交的凸集,则存在超平面P,
P可以将C和D分离。
线性可分支持向量机
SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大
? 给定线性可分训练数据集,通过
间隔最大化得到的分离超平面为
相应的分类决策函数
该决策函数称为线性可分支持向量机。
? φ(x)是某个确定的特征空间转换函数,它的作用是
将x映射到(更高的)维度。
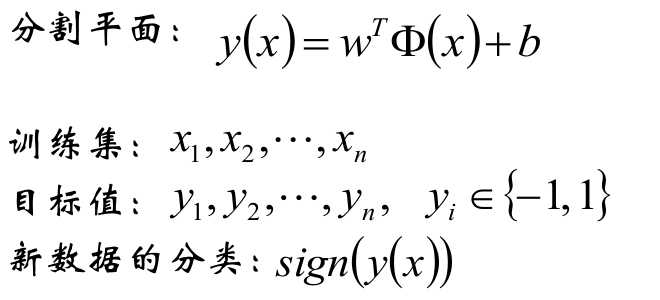
线性支持向量机
分类线能将两类分开(训练错误率大于0,存在个别样本点分错),且使分类间隔最大
非线性支持向量机
存在非线性分割超平面,讲样本分开
sparkmllib代码实现
package mllib import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD} import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.util.MLUtils import org.apache.spark.rdd.RDD import org.apache.spark.sql.SQLContext import org.apache.spark.{SparkContext, SparkConf} //二分类 object SVMwithSGD { def main(args: Array[String]) { val conf = new SparkConf().setAppName("test").setMaster("local") val sc = new SparkContext(conf) val sql = new SQLContext(sc); val data: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, "svm.txt") val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L) val training = splits(0).cache() val test = splits(1) // data.foreach( x => println(x.toString())) // data.foreach( x => println(x.label)) data.foreach( x => println(x.features)) val numIterations = 100 val model: SVMModel = SVMWithSGD.train(training, numIterations) model.clearThreshold()//为了模型拿到评分 不是处理过之后的分类结果 val scoreAndLabels: RDD[(Double, Double)] = test.map { point => // 大于0 小于0 两类 val score = model.predict(point.features) (score, point.label) } scoreAndLabels.foreach(println) } }

评分>0表示样本点在分割面之上,<0表示在分割面之下
标签:ons load 最优 平面 and 分类 处理 strong ict
原文地址:http://www.cnblogs.com/xiaoma0529/p/6928092.html