标签:for closed 旋转 附加 相同 技术 sign sys .com
赛题为:
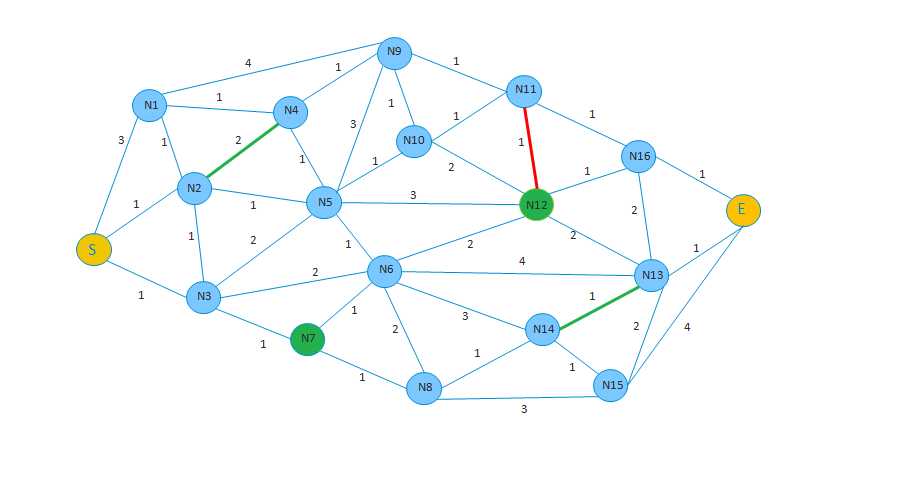
最强大脑中的收官蜂巢迷宫变态级挑战,相信大家都叹为观止!最强大脑收官战打响后,收视率节节攀升,就连蚁后也不时出题难为一下她的子民们。在动物世界中,称得上活地图的,除了蜜蜂,蚂蚁当仁不让。在复杂多变的蚁巢中, 蚂蚁总是能以最快、最高效的方式游历在各个储藏间(存储食物)。今天,她看完最新一期节目,又发布了一项新任务:小蚁同学,我需要玉米库的玉米,再要配点水果,去帮我找来吧。小蚁正准备出发,蚁后又说:哎呀,回来,我还没说完呢,还有若干要求如下:
1.小蚁同学,你需要尽可能以最少的花费拿到食物(附件图中路线上的数值表示每两个储物间的花费);
2.小蚁同学,你最多只能经过9个储藏间拿到食物(包含起止两个节点,多次通过同一节点按重复次数计算);
3.小蚁同学,你必须经过玉米间,水果间(附件图中标绿色节点);
4.别忘了,食蚁兽也在路上活动呢,一旦与食蚁兽相遇,性命危矣!不过小蚁微信群公告已经公布了敌人信息(附件图中标红色路段);
5.最后,千万别忘了,还有两段路是必须经过的,那里有我准备的神秘礼物等着你呢(附件图中标绿色路段)。
这下小蚁犯难了,这和它们平时找食物的集体活动规则不一样嘛,看来这次需要单独行动了。要怎么选路呢?小蚁经过一番苦思冥想,稿纸堆了一摞,啊,终于找到了!亲爱的同学们,你们能否也设计一种通用的路径搜索算法,来应对各种搜索限制条件,找到一条最优路径,顺利完成蚁后布置的任务呢?
注:
1、蚁巢,有若干个储藏间(附件图中圆圈表示),储藏间之间有诸多路可以到达(各储藏间拓扑图见附件);
2、节点本身通行无花费;
3、该图为无向图,可以正反两方向通行,两方向都会计费,并且花费相同;
4、起止节点分别为附件图中S点和E点。
5、最优路径:即满足限制条件的路径。
一、算法思路:
我们把题目看成旅行商问题,然后用遗传算法求出最优解或者次优解。
二、模型建立
本题属于单源单点间附加必经点、必经边的问题,为将本题转化为旅行商问题,加上还需一条从源点S到终点T的附加边,该边的花费为源点到终点的花费,然后将该边当做一条必经边来处理。对于必经边,采用将必经边也处理成一个特殊的必经点的方法,该特殊必经点包含起点和终点。在染色体中只出现必经边u-v上的一点,如果是u则代表从必经边的u点进入,从v点出去;如果是v则代表从必经边的v点进入,从u点出去,然后本题就可以转化为存在一定数量必经点的旅行商问题。
初始化:生成SUM个初始解,初始解1为贪心解,其余SUM-1个解均为随机生成。贪心解的思想是,离源点S越近的必经点或必经边,越先放进解中,如例图,离远点最近的是属于必经边2-4的点2,所以将必经点2放进初始解(隐含了2-4这条边),接下来是点7,将其放进解中,然后是属于必经边(13-14)的点14,将点14放进初始解中(隐含了14-13这条边),然后是点12,最后把终点T到源点S的边放进去,生成第一个贪心的初始解,为2(4)-7-14(13)-12-17(0);其余SUM-1个初始解均为随机生成必经点必在解中,必经边中的一个点u在解中,隐含了u-v这条边,例如:上节随机初始化的另一组解4 13 12 7 17,其中点4代表路径4-2,13代表路径13-14,17代表路径17-0。
个体评价:以贪心生成的解2(4)-7-14(13)-12-17(0)为例:染色体中第一个基因是点2,属于必经边,现加上边2-4的权值,然后加上4到下一个结点7的权值;结点7不是必经边,直接加上结点7到下一个点14的权值;结点14属于必经边,先加上14-13的权值,再加上结点13-12的权值;结点12不是必经边,直接加上结点12到下一结点17(即终点)的权值;结点17属于必经边,先加上结点17到结点0(即源点)的权值,然后加上结点0到2的权值;然后最后减去源点到起点的权值,即为此路径的花费,上述贪心解的花费为13。
对于该染色体经历的结点数量使用的方法是提前通过弗洛伊德算法得到的最短路径信息得到所有必经点之间两两的最小花费经历结点数,然后对某一必经点组合,只需要遍历一遍所有节点然后加起来,就可以得到改染色体所经历的结点数;
选择运算:因为通过交叉得到的子代总是小于等于父代,所以这里直接选择交叉变异产生的子代。
记录最优:有两个记录最优的方面,一方面是记录满足结点数满足最少结点要求的最优解,一个室结点数不满足最少节点数的次优解;
交叉运算:选择两个参加交叉的染色体作为父代,例如:
A=2(4)-7-14(13)-12-17(0)
B=12-7-13(14)-4(2)-17(0)
染色体A的cost为13,染色体B的cost为19;首先比较结点4与7的权值为3,12与7之间的权值也为3;就以2(4)为头结点,将初始解右转动为(染色体B中没有特殊节点2(4),但是因为2与4均属于必经边2-4,在此将染色体B中的4(2)替换成2(4)代表从2点进入,然后从4点出):
A=2(4)-7-14(13)-12-17(0)
B=2(4)-17(0)-12-7-13(14)
然后比较4与7的权值为3,4与17的权值为4,所以就有:
A=*-7-14(13)-12-17(0)
B=*-7-13(14)-17(0)-12
由此规则计算可得:
O=2(4)-7-14(13)-12-17(0)
我们本来是2个不同的解,现在得到了一个比两个解都优的解,总不能让原来的两个解都等于现在的这个局部最优解吧,这样不利于下次交叉,我们可以用随机旋转的方法改变另外一个解的路径:Rotate(q.info, NUMmustp, rand() % NUMmustp);
变异运算:只需要在一个解中随机的选择两个基因,然后交换它们即可。
三、算法实现结果分析
读图(邻接表),将食蚁兽所在的路径花费设为0x3f3f3f,既不经过此路径(剪枝)。
1.弗洛伊德算法求取加权图中多源点之间最短路径
因为后期需要大量计算最短路径,选择迪杰斯特拉只能求取单源单汇之间的最短路径,多次调用的话时间消耗太大。所以这里使用弗洛伊德算法一次求取,后面直接调用。迪杰斯特拉算法复杂度为主要依赖于最小优先队列的实现,使用简单数组算法复杂度为O(V^2),使用二叉堆可以优化到O(ElgV),使用斐波那契堆可以优化到O(VlgV+E);而弗洛伊德时间复杂度为O(N^3),空间复杂度为O(N^2)。当图的规模比较大,并且必经点、必经边比较多的话,使用弗洛伊德算法可以大规模减少时间。
2.初始化初始种群
第一个解为贪心求得,其余SUM个解为随机生成;因为例图里面的点比较少,所以使用贪心求取的路径已经是局部最优了。
3.遗传全局优化
因为图比较小,通过贪心就直接获得最优了,所以这里我统计了每一代所有染色体的权值和的平均,种群规模SUM为10000,制成图。从上图可以看出来通过遗传可以很快收敛到最优附近,然后利用遗传的全局寻优能力寻找最优解。
4.输出
针对题中所给用例,通过我们的解题算法,在满足所有要求的情况下并未搜索一条最优的路径,经统计每一代最终的平均花费是逐渐变小并最终稳定在13,最终输出一组次优路径,路径为:0->2->4->5->6->7->8->14->13->12->16->17,经过12个点,花费为13。

#include<stdio.h> #include <stdlib.h> #include <memory.h> #define MAXN 10000 #define INF 0x3f3f3f #define SUM 10 //总共的染色体数量 #define MAXloop 10000 //最大循环次数 #define error 0.01 //若两次最优值之差小于此数则认为结果没有改变 #define crossp 0.7 //交叉概率 #define mp 0.1 //变异概率 int numnode = 0; int dis[MAXN][MAXN]; int pathmatirx[MAXN][MAXN]; int numofnodepath[MAXN][MAXN]; int S ; //起点 int T ; //终点 int mustp[MAXN]; int nummustp = 0; //必经点的个数,必经边算两个必经点 int NUMmustp = 0; //个体中的染色体个数 int ret[1000]; int ptri = 0; struct gen //定义染色体结构 { int info[MAXN]; //染色体结构,表示从0开始经过这个染色体结构之后,到达T int cost; //次染色体所对应的适应度函数值,在本题中为表达式的值 int numofnode; }; struct gen gen_group[SUM];//定义一个含有20个染色体的组 struct gen gen_result; //记录次优的染色体 struct gen gen_result2; //记录最优的染色体 int result_unchange_time; //记录在error前提下最优值为改变的循环次数 struct mustedge{ bool flag; int u; int v; }ismustedge[MAXN]; //**************************************普通函数声明*****************************// void reading(); //读图 void floyd(); //弗洛伊德求最短路径 void init(); //初始化 int randsign(float p); //按照概率p产生随机数0、1,其值为1的概率为p int randbit(int i,int j); //产生一个在i,j两个数之间的随机整数 void findway( int a , int b ); int numofnode( int i , int j ); //**************************************遗传函数声明*****************************// void gen_swap(gen *a,gen *b); //结构体交换 void gen_quicksort(gen *number,int left,int right); //种群排序 void initiate(); //初始化函数,主要负责产生初始化种群 void evaluation(int flag); //评估种群中各染色体的适应度,并据此进行排序 void Cross_group( gen &p, gen &q); //交叉函数 void selection(); //选择函数 int record(); //记录每次循环产生的最优解并判断是否终止循环 void Varation_group(gen group[]); //变异函数 int Search_son( int path[], int len, int city); int Search_son1( int path[], int len, int city); void Rotate(int path[],int len, int m); void evaluation(int flag) { int i , j , node1 , node2 ; struct gen *genp; genp = gen_group; for(i = 0 ; i < SUM ; i++)//计算各染色体对应的表达式值 { genp[i].cost = 0; int cost = 0; int num = 0; for( j = 0 ; j < NUMmustp - 1 ; ++j ){ if( !ismustedge[genp[i].info[j]].flag ){ node1 = genp[i].info[j]; node2 = genp[i].info[j + 1]; cost += dis[node1][node2]; num += numofnodepath[node1][node2]; } else{ node1 = genp[i].info[j]; node2 = ismustedge[genp[i].info[j]].v; cost += dis[node1][node2]; node1 = genp[i].info[j + 1]; cost += dis[node2][node1]; num += 1; num += numofnodepath[node2][node1]; } } if( !ismustedge[genp[i].info[NUMmustp - 1]].flag ){ node1 = genp[i].info[NUMmustp - 1]; node2 = genp[i].info[0]; cost += dis[node1][node2]; num += numofnodepath[node1][node2]; } else{ node1 = genp[i].info[NUMmustp - 1]; node2 = ismustedge[genp[i].info[NUMmustp - 1]].v; cost += dis[node1][node2]; node1 = genp[i].info[0]; cost += dis[node2][node1]; num += 1; num += numofnodepath[node2][node1]; } cost -= dis[T][S]; genp[i].cost = cost; genp[i].numofnode = num; } gen_quicksort(genp ,0 ,SUM-1 ); //对种群进行重新排序 } void calnodenum(){ int i , j; for(i = 0 ; i < nummustp ; i++) { for(j = 0 ; j < nummustp; j++ ) { if(mustp[i] == mustp[j]){ numofnodepath[mustp[i]][mustp[j]] = 0; } else{ numofnodepath[mustp[i]][mustp[j]] = numofnode(mustp[i] , mustp[j]); } /*if(i == j){ numofnodepath[i][j] = 0; } else{ numofnodepath[i][j] = numofnode(i , j); }*/ } } } int main(){ int i , j; reading(); floyd(); calnodenum(); result_unchange_time = 0; gen_result.cost = INF; gen_result2.cost = INF; initiate(); evaluation( 0 ); //对初始化种群进行评估、排序 for( i = 0 ; i < MAXloop && result_unchange_time < 10 ; i++ ) { printf("第%d次迭代:",i); for(int ii = 0 ; ii < SUM ; ++ii ){ printf("染色体%d: ",ii); for(j = 0 ; j < NUMmustp; ++j ){ printf("%d ",gen_group[ii].info[j]); } printf(" 花费为:%d,结点数为:%d\n",gen_group[ii].cost,gen_group[ii].numofnode); }printf("\n"); float temp = 0; for (j = 0; j < SUM; j+= 1) { temp += gen_group[j].cost; } printf("本代平均花费为:%f\n",temp/SUM); printf("\n\n\n\n"); if (gen_group[0].cost < gen_result.cost) { result_unchange_time = 0; memcpy(&gen_result, &gen_group[0], sizeof(gen)); } else{ result_unchange_time++; } for( j = 0; j < SUM ; ++j){ if(gen_group[j].numofnode <= 9 && gen_group[j].cost < gen_result2.cost){ result_unchange_time = 0; memcpy(&gen_result2, &gen_group[0], sizeof(gen)); } } for (j = 0; j < SUM / 2; j+= 1) { Cross_group(gen_group[j], gen_group[ SUM - j -1]); } evaluation( 0 ); Varation_group(gen_group); evaluation( 0 ); } if(gen_result2.cost != INF){ printf("有最优解:\n"); memcpy(&gen_result, &gen_result2, sizeof(gen)); } else{ printf("无最优解,输出次优解:\n"); } for(int ii=0;ii<NUMmustp - 1;ii++) { i = gen_result.info[ii]; j = gen_result.info[ii+1]; if(ismustedge[i].flag){ //printf(",V%d,",i); ret[ptri++] = i; findway(ismustedge[i].v , j); } else findway(i , j); } i = gen_result.info[NUMmustp-1]; j = gen_result.info[0]; if(ismustedge[i].flag){ //printf(",V%d,",i); ret[ptri++] = i; findway(ismustedge[i].v , j); } else findway(i , j); //printf("\n");printf("\n"); int pos1 = Search_son1( ret, ptri, S); Rotate(ret, ptri, pos1); for( i = 0 ; i < ptri ; ++i){ printf("%d->",ret[i]); } printf("\n"); system("pause"); return 0; } int numofnode( int i , int j ){ int k , retnum = 0; k=pathmatirx[i][j]; //取路径上Vi的后续Vk if(k==-1) { printf("顶点%d 和 顶点%d 之间没有路径\n",i,j);//路径不存在 } else { retnum++; while(k!=j) { retnum++; k=pathmatirx[k][j]; //求路径上下一顶点序号 } } return retnum; } void findway( int i , int j ){ int k ; k=pathmatirx[i][j]; //取路径上Vi的后续Vk if(k==-1) { printf("顶点%d 和 顶点%d 之间没有路径\n",i,j);//路径不存在 } else { ret[ptri++] = i; while(k!=j) { ret[ptri++] = k; k=pathmatirx[k][j]; //求路径上下一顶点序号 } } } void Varation_group(gen group[]) { int i, j, k; double temp; //变异的数量,即,群体中的个体以PM的概率变异,变异概率不宜太大 int num = SUM * mp; while (num--) { //确定发生变异的个体 k = rand() % SUM; //确定发生变异的位 i = rand() % NUMmustp; j = rand() % NUMmustp; //exchange temp = group[k].info[i]; group[k].info[i] = group[k].info[j]; group[k].info[j] = temp; } } int Search_son1( int path[], int len, int city) { int i = 0; for (i = 0; i < len; i++) { if (path[i] == city) { return i; } } return -1; } int Search_son( int path[], int len, int city) { int i = 0; for (i = 0; i < len; i++) { if (path[i] == city) { return i; } else if( ismustedge[ city ].flag && ismustedge[ city ].v == path[i] ){ path[i] = ismustedge[ path[i] ].v; return i; } } return -1; } //reverse a array //it‘s a auxiliary function for Rotate() void Reverse(int path[], int b, int e) { int temp; while (b < e) { temp = path[b]; path[b] = path[e]; path[e] = temp; b++; e--; } } //旋转 m 位 void Rotate(int path[],int len, int m) { if( m < 0 ) { return; } if (m > len) { m %= len; } Reverse(path, 0, m -1); Reverse(path, m, len -1); Reverse(path, 0, len -1); } void Cross_group( gen &p, gen &q) { //for(int ii = 0 ; ii < NUMmustp ; ++ ii){ // printf("%d ",p.info[ii]); //}printf("\n"); //for(int ii = 0 ; ii < NUMmustp ; ++ ii){ // printf("%d ",q.info[ii]); //}printf("\n");printf("\n");printf("\n"); int i = 0; int pos1, pos2; int len = NUMmustp; int first; double len1 ,len2 ; if( ismustedge[ p.info[0] ].flag ) len1 = dis[ismustedge[ p.info[0]].v][ p.info[1] ]; else len1 = dis[p.info[0] ][ p.info[1] ]; if( ismustedge[ q.info[0] ].flag ) len2 = dis[ismustedge[ q.info[0]].v][ q.info[1] ]; else len2 = dis[q.info[0] ][ q.info[1] ]; if (len1 <= len2) { first = p.info[0]; } else { first = q.info[0]; } pos1 = Search_son( p.info + i, len, first); pos2 = Search_son( q.info + i, len, first); Rotate(p.info + i, len, pos1); Rotate(q.info + i, len, pos2); while ( --len > 1) { i++; int span1 , span2 ; int temp; if(ismustedge[ p.info[i - 1] ].flag){ temp = ismustedge[ p.info[i - 1] ].v; } else{ temp = p.info[i - 1]; } span1 = dis[temp][ p.info[i] ]; if(ismustedge[ q.info[i - 1] ].flag){ temp = ismustedge[ q.info[i - 1] ].v; } else{ temp = q.info[i - 1]; } span2 = dis[temp][ q.info[i] ]; if ( span1 <= span2 ) { pos2 = Search_son( q.info + i, len, p.info[i]); Rotate(q.info + i, len, pos2); } else { pos1 = Search_son( p.info + i, len, q.info[i]); Rotate(p.info + i, len, pos1); } } Rotate(q.info, NUMmustp, rand() % NUMmustp); } void initiate(){ /*********第一个初始解定义为按离起点的距离的顺序*********************/ bool *flag = NULL; //用于标记必经点中的某点是否被选进染色体中 flag = (bool*)malloc(sizeof(bool) * nummustp); if(flag == NULL){ printf("error initiate\n"); exit(1); } for(int i = 0 ; i < nummustp; ++i )flag[i] = false; int i , j , z ; gen_group[0].info[NUMmustp - 1] = T ; flag[nummustp - 1] = true; flag[0] = true; for( i = 0 ; i < NUMmustp - 1 ; ++i ){ int min = INF;int k = INF; for( j = 0 ; j < nummustp ; ++j ){ if(!flag[j] && dis[S][mustp[j]] < min ){ min = dis[S][mustp[j]]; k = j; } } if(k != INF){ if( !ismustedge[mustp[k]].flag ){ //如果是必经点 gen_group[0].info[i] = mustp[k]; flag[k] = true; } else{ //如果是必经边 gen_group[0].info[i] = mustp[k]; flag[k] = true; for(z = 0 ; z < nummustp ; ++z ){ if( mustp[z] == ismustedge[mustp[k]].v ){ flag[z] = true;break; } } } } else{ break; } } /*********随机生成剩余初始解*********************/ int k; for( i = 1 ; i < SUM ; ++i ){ for(j = 0 ; j < nummustp; ++j )flag[j] = false; gen_group[i].info[NUMmustp - 1] = T; flag[0] = true; flag[nummustp - 1] = true; for(j = 0 ; j < NUMmustp - 1 ; ++j ){ k = randbit(0 , nummustp-1); while( flag[k] ){ k = randbit(0 , nummustp-1); } if( !ismustedge[mustp[k]].flag ){ //如果是必经点 gen_group[i].info[j] = mustp[k]; flag[k] = true; } else{ //如果是必经边 gen_group[i].info[j] = mustp[k]; flag[k] = true; for(z = 0 ; z < nummustp ; ++z ){ if( mustp[z] == ismustedge[mustp[k]].v ){ flag[z] = true;break; } } } } } free(flag); flag = NULL; } void reading(){ FILE *fp; if(NULL == (fp = fopen("case0.txt", "r"))) { printf("error reading\n"); exit(1); } S = 0; numnode = 0; char ch; while( ‘\n‘ != (ch=fgetc(fp)) ) //总的点的个数 { numnode = numnode*10 + ch - ‘0‘; //printf("%c", ch); } T = numnode - 1; //printf("起点为%d,终点为%d,结点数目为%d\n" , S, T, numnode); ch=fgetc(fp); nummustp = 0; memset(mustp,0,sizeof(mustp)); mustp[++nummustp] = S;++NUMmustp; while( ‘\n‘ != (ch=fgetc(fp)) ) //读取必经点 { if(ch == ‘ ‘){ ++nummustp;++NUMmustp; } else{ mustp[nummustp] = mustp[nummustp]*10 + ch - ‘0‘; //printf("%c", ch); } } ch=fgetc(fp); init(); int temp[3] = {0,0,0} , j = 0; while( ‘\n‘ != (ch=fgetc(fp)) ) //读取图 { temp[0] = 0 ,temp[1] = 0 ,temp[2] = 0 , j = 0; while(ch != ‘\n‘){ if( ch == ‘ ‘ ){ ++j; } else{ temp[j] = temp[j]*10 + ch - ‘0‘; } ch = fgetc(fp); } dis[temp[0]][temp[1]] = temp[2]; dis[temp[1]][temp[0]] = temp[2]; pathmatirx[temp[0]][temp[1]] = temp[0]; pathmatirx[temp[1]][temp[0]] = temp[1]; } while( ‘\n‘ != (ch=fgetc(fp)) ) //必经边的权值设为0 { temp[0] = 0 ,temp[1] = 0 ,temp[2] = 0 , j = 0; while(ch != ‘\n‘){ if( ch == ‘ ‘ ){ ++j; } else{ temp[j] = temp[j]*10 + ch - ‘0‘; } ch = fgetc(fp); } mustp[++nummustp] = temp[0]; mustp[++nummustp] = temp[1]; ++NUMmustp; ismustedge[temp[0]].flag = true; ismustedge[temp[0]].u = temp[0]; ismustedge[temp[0]].v = temp[1]; ismustedge[temp[1]].flag = true; ismustedge[temp[1]].u = temp[1]; ismustedge[temp[1]].v = temp[0]; } while( ‘\n‘ != (ch=fgetc(fp)) ) //惩罚边的权值设为INF { temp[0] = 0 ,temp[1] = 0 ,temp[2] = 0 , j = 0; while(ch != ‘\n‘){ if( ch == ‘ ‘ ){ ++j; } else{ temp[j] = temp[j]*10 + ch - ‘0‘; } ch = fgetc(fp); } dis[temp[0]][temp[1]] = INF; dis[temp[1]][temp[0]] = INF; } ++NUMmustp; mustp[++nummustp] = T; ismustedge[S].flag = true; ismustedge[S].u = S; ismustedge[S].v = T; ismustedge[T].flag = true; ismustedge[T].u = T; ismustedge[T].v = S; ++nummustp; //必经点的数量+1 //printf("\n"); fclose(fp); } void floyd(){ //计算所有顶点到所有顶点的最短路径 int k , i , j; for( i = 0 ; i <= numnode ; ++i ){ for( j = 0 ; j <= numnode ; ++j ){ if(dis[i][j] < INF) pathmatirx[i][j] = j; //初始化路径数组 else pathmatirx[i][j] = -1; } } for(k = 0 ; k < numnode ; ++k ) { for( i = 0 ; i < numnode ; ++i ) { for( j = 0 ; j < numnode ; ++j ) { if( dis[i][j] > dis[i][k] + dis[k][j] ) { //如果经过下标为k顶点路径比原两点间路径更短 dis[i][j] = dis[i][k] + dis[k][j]; //更新当前两点间权值 pathmatirx[i][j] = pathmatirx[i][k]; //路径设置为经过下标为K的顶点 } } } } } void gen_swap(gen *a,gen *b) { gen temp; temp = *a; *a = *b; *b = temp; } void gen_quicksort(gen *number,int left,int right)//快速排序,用于结构体排序 { int i ,j ,s ; if(left < right) { s = number[(left + right) / 2].cost ,j = right+1 ,i = left-1; while(1) { while(number[++i].cost < s ) ; while(number[--j].cost > s ) ; if(i>=j) break; gen_swap(&number[i] ,&number[j] ); } gen_quicksort(number ,left ,i-1 ); gen_quicksort(number ,j+1 ,right ); } } void init(){ int i , j ; for( i = 0 ; i <= numnode ; ++i ){ for( j = 0 ; j <= numnode ; ++j ){ //pathmatirx[i][j] = j; //初始化路径数组 if(i == j ) dis[i][j] = 0; else dis[i][j] = INF; } } for(i = 0 ; i < MAXN ; ++i ){ ismustedge[i].flag = false; } } int randsign(float p)//按概率p返回1 { if(rand() > (p * 32768)) return 0; else return 1; } int randbit(int i, int j)//产生在i与j之间的一个随机数 { int a , l; l = j - i + 1; a = i + rand() * l / 32768; return a; }
标签:for closed 旋转 附加 相同 技术 sign sys .com
原文地址:http://www.cnblogs.com/jhmu0613/p/6930146.html
