标签:结果 查询条件 设置 date span .com 兴趣 精简 不能
一、业务场景
我们在实际生产环境中遇到了这样一种需求,即需要检索一个父子关系的子树数据
估计大家也遇到过类似的场景,最典型的就是省市数据,其中path字段是按层级关系生成的行政区路径:
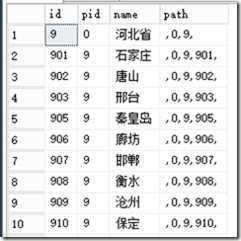
如果我们已知某市名,想查出同级和高一级的省名,如保定市同级和上级河北省,那么我们有什么实现方式呢
给大家10秒钟,快速抢答
.
.
.
时间到
大概有以下几种方法:
a.2008中新添加的层级数据类型
b.cte递归方式
c.直接程序处理
d.比较傻的方式:全文索引。。。
层级关系是实现这种业务逻辑的最好方式,比较经典的方式是递归方式,但是,我们不讲这两个方法内容和实现,因为今天的主题是:全文索引中的坑,因为这是我实实在在遇到的案例
我们的业务逻辑是这样的,已知一个或者几个ID,但并不了解这个ID的层次关系,需要的数据是提取对应ID的所有层次,比如按上图来说,我传入id in(9,910)那么就要所有河北省的数据,如果我传入id in(910),那么所取的数据就是保定市以及下属所有行政区
二、问题出现
为了简化说明问题,我把数据精简为表pathtest,数据为下图形式
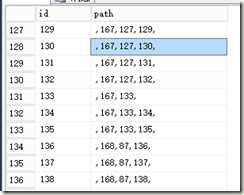
按照上段说明的业务需求,在path需要建立一个全文索引方便检索,这个过程相信大家都知道如何建,就不描写过程了
我们先看一下实际包含66的数据行有多少?(或者说ID=66及以下的子树数据集)
select * from pathtest where path like ‘%,66,%‘
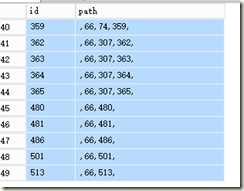
(49 行受影响)
结果省略一部分,但可以看出是49行
之后我运行如下的查询,查询路径下包含66的数据集,也就是ID=66以及之下的子树
select * from pathtest where freetext(path,‘"66"‘)
(17 行受影响)

显示是17行结果??
差这么多啊?就说是全文索引不精确,这也差太多了吧
OK,我们继续
select * from pathtest where freetext(path,‘"66,480"‘)
同样,按逻辑上说,这个查询同样是检索66层次ID下的子树(PS:这里480是在66子树下)
但是:
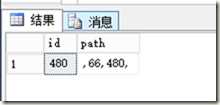
这下更方便看了,根本就没有数据,这是怎么回事?
三、问题研究
有些经验的同学肯定已经想到这是全文索引建立的时候分词出现了问题,那么我们就看一下
sys.dm_fts_parser 这个函数是对字符串按全文索引方式进行关键字拆分,具体使用请查阅MSDN
我分别取两个路径串
1.path=’,66,73,’
2.path=’,66,480,’
我们来看一下拆分的结果
select * from sys.dm_fts_parser (‘",66,73,"‘,1033,0,1)
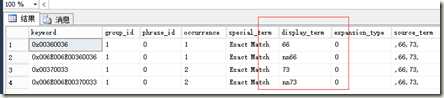
嗯,把66,73分别拆分成字符串关键字“66”、“73”以及数值(nn开头)的66、73一共四条记录,没有问题
select * from sys.dm_fts_parser (‘",66,480,"‘,1033,0,1)

这下问题出现了,字符串并没有按我们想的那样拆分成“66”与“480”的关键字,而是生成了”66,480”与66480的两个关键字
所以我们在进行freetext(path,‘"66,480"‘)检索的时候返回了一条满足条件的记录,且freetext(path,‘"480"‘)的时候没有满足关键字的记录。
这里涉及到一个全文索引关键词拆分算法的问题,sqlserver把类似66,480这种字符串当成了有千分位分隔符的纯数字,所以不再进行拆分
但是像66,73这种字符串,不是数字的千分位分隔表示方法,所以进行了拆分
假如我们把66,480这个字符串改写成66,480,1,则会进行字符串方式的拆分,如下:
select * from sys.dm_fts_parser (‘",66,480,1,"‘,1033,0,1)
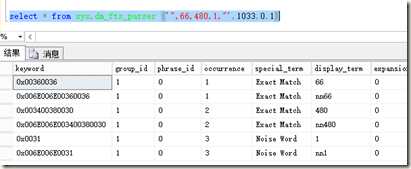
同时我们知道freetext这个函数也是以建立全文索引的方式进行检索词拆分后与全文索引进行比较,所以在进行where freetext(path,‘"66,480"‘)检索的时候,也是把字符串进行了处理,但同样是将字符串以千分位分隔数字进行了处理,所以可以检索出一条path=’66,480’记录,但是在进行where freetext(path,‘"480"‘)的时候,由于全表的全文索引中,并没有拆分出480这个字符串关键词,所以没有满足条件的记录
如果我们将检索串改写为where freetext(path,‘"66 480"‘),那么对于这个逻辑来说,就是要检索全文索引中满足66或者480关键字的结果集,在本例中,结果集为17条,即与where freetext(path,‘"66"‘)相同(因为空格符做为了断字符将字符拆为了“66”与“480”,表中满足66的结果集为17条,480为0条,所以结果总数为17条)
四、解决方案
既然知道了是”,”引起的字符串误判断,我们就把这个替换掉
update pathtest set path=replace(path,‘,‘,‘;‘)
等全文索引重新填充完成后,执行
select * from pathtest where freetext(path,‘"66"‘)
(49 行受影响)
好!与直接like的结果一致
之后我们再运行 select * from pathtest where freetext(path,‘"66,480"‘)
(0 行受影响)
!!!什么情况 !?
之前我们说了,“66,480”会被误判断拆分,所以这里的检索词也不能这么写了,可以写空格,也可以写分号,反正就是不能用逗号,将查询改为
select * from pathtest where freetext(path,‘"66 480"‘)
(49 行受影响)
select * from pathtest where freetext(path,‘"480"‘)
(1 行受影响)
好了,这下与期待结果一致了
五、后记
这个问题解决前还出过一段插曲,把“,”替换成了“/”,但是在进行拆分的时候/66/480/拆分成了”66”与”480/”,后来将/加入了stoplist,这个问题就解决掉了,本次测试我没有再现这个情况,应该是当时设置的断字语言导致的,有兴趣的同学可以自己玩一下。
切记如果你要建的全文索引中有类似的字段,清注意逗号问题,同时在freetext检索的时候,也同样要注意“,”的问题。
此外我们看到SqlServer的全文索引,实际上就是命中查询条件中搜索的关键字来筛选数据的,SqlServer将查询语句中搜索的关键字和全文目录中收集的关键字进行匹配,返回数据表中关键字匹配成功的数据行。但是从本文可以看到这种匹配全文目录关键字的查找,并不是像like关键字一样100%返回满足条件的数据,如果全文目录中收集的关键字不够多或不正确,全文索引的匹配就会失败,导致查询结果不正确,所以在SqlServer中使用全文索引一定要小心谨慎!
标签:结果 查询条件 设置 date span .com 兴趣 精简 不能
原文地址:http://www.cnblogs.com/OpenCoder/p/6934986.html