标签:栈溢出 data 命令 struct dba 而且 名称空间 数据 指令
1、生成器的语句形式
a.生成器相关python函数、装饰器、迭代器、生成器,我们是如何使用生成器的。一个生成器能暂停执行并返回一个中间的结果这就是 yield 语句的功能 : 返回一个中间值给调用者并暂停执行。
我们的调用方式为yeild 1的方式,此方式又称为生成器的语句形式。
而使用生成器的场景:使用生成器最好的场景就是当你需要以迭代的方式去穿越一个巨大的数据集合。比如:一个巨大的文件/一个复杂的数据库查询等。

1 # def read_file(fpath): 2 # BLOCK_SIZE = 1024 3 # with open(fpath, ‘rb‘) as f: 4 # while True: 5 # block = f.read(BLOCK_SIZE) 6 # if block: 7 # yield block 8 # else: 9 # return 10 11 ‘‘‘ 12 结果: 13 以上传入参数就可以按1024字符,以迭代的方式,返回读取内容,内存只占1024字符 14 ‘‘‘
b.加强的生成器特性:
除了可以使用 next() 方法来获取下一个生成的值,用户还可以使用 send() 方法将一个新的或者是被修改的值返回给生成器。除此之外,还可以使用 close() 方法来随时退出生成器。
1 ‘‘‘ 2 b.加强的生成器特性 3 除了可以使用 next() 方法来获取下一个生成的值,用户还可以使用 send() 方法将一个新 4 的或者是被修改的值返回给生成器。除此之外,还可以使用 close() 方法来随时退出生成器。 5 ‘‘‘ 6 # def eater(name): 7 # print(‘%s ready to eat!!!‘ % (name)) 8 # count = 1 9 # while True: 10 # yield count 11 # count += 1 12 # print(‘%s eating‘ % (name)) 13 # 14 # g = eater(‘Tom‘) 15 # print(next(g)) 16 # print(next(g)) 17 ‘‘‘ 18 直接运行g.send()报错,为生成器没有初始化,所以使用.send(),第一个值必须初始化 19 Traceback (most recent call last): 20 File "D:/old_boy/old_boy_17_05/yield_ex1.py", line 66, in <module> 21 print(g.send(‘shuyang‘)) 22 TypeError: can‘t send non-None value to a just-started generator 23 # print(g.send(‘shuyang‘)) 24 ‘‘‘ 25 # print(g.send(None)) # .send(None) == next(g) 26 # print(g.send(None)) 27 # g.close() # 退出生成器 28 # next(g) 29 ‘‘‘ 30 结果: 31 Tom ready to eat!!! 32 1 33 Tom eating 34 2 35 Tom eating 36 3 37 Tom eating 38 4 39 Traceback (most recent call last): 40 File "D:/old_boy/old_boy_17_05/yield_ex1.py", line 62, in <module> 41 next(g) 42 StopIteration 43 ‘‘‘
直接运行g.send()会报错,为生成器没有初始化,所以使用.send(),第一次必须使用.send(None)初始化生成器
2、生成器的表达式形式
a.简单用法,其实x = yield,就是一个表达式,yield不仅仅是一个语句,它还可以用.send()特性,做赋值操作。
1 # # 装饰器,执行生成器第一次初始化 2 # def deco(func): 3 # def wrapper(*args,**kwargs): 4 # res=func(*args,**kwargs) 5 # next(res) 6 # return res 7 # return wrapper 8 # 9 # @deco 10 # def eater(name): 11 # print(‘%s ready to eat!!!‘ % name) 12 # while True: 13 # food = yield 14 # print(‘%s eating %s‘ % (name, food)) 15 # 16 # g = eater(‘alex11‘) 17 # # next(g) # g.send(None) 18 # g.send(‘面条‘) 19 # g.send(‘馒头‘) 20 # g.send(‘包子‘) 21 22 ‘‘‘ 23 结果: 24 alex11 ready to eat!!! 25 alex11 eating 面条 26 alex11 eating 馒头 27 alex11 eating 包子 28 ‘‘‘
b.通过生成式表达式优化列表解析:两者的语法非常相似,但生成器表达式返回的不是一个列表类型对象,而是一个生成器对象,生成器是一个内存使用友好的结构。
列表解析:
[expr for iter_var in iterable if cond_expr]
生成器表达式:
(expr for iter_var in iterable if cond_expr)
1 # 列表写法 2 l = [‘egg%s‘ %i for i in range(10)] 3 print(l) 4 # 生成器写法 5 g = (‘egg%s‘ %i for i in range(10)) 6 # print(g) 7 # print(next(g)) 8 # print(next(g)) 9 # for i in g: 10 # print(i) 11 print(list(g)) 12 ‘‘‘ 13 结果: 14 [‘egg0‘, ‘egg1‘, ‘egg2‘, ‘egg3‘, ‘egg4‘, ‘egg5‘, ‘egg6‘, ‘egg7‘, ‘egg8‘, ‘egg9‘] 15 [‘egg0‘, ‘egg1‘, ‘egg2‘, ‘egg3‘, ‘egg4‘, ‘egg5‘, ‘egg6‘, ‘egg7‘, ‘egg8‘, ‘egg9‘] 16 ‘‘‘
1 # 文件写法 2 # 列表存值写法 3 # f = open(‘FILENAME‘, ‘r‘) 4 # allLinesLen = [line(x.strip()) for x in f] 5 # f.close() 6 # return max(allLinesLen) # 返回列表中最大的数值 7 # 生成器存值写法 8 # f = open(‘FILENAME‘, ‘r‘) 9 # allLinesLen = (line(x.strip()) for x in f) # 这里的 x 相当于 yield x 10 # f.close() 11 # return max(allLinesLen)
3、协程函数
在python中,协程函数就是使用了yield表达式形式的生成器。
它的优点为省内存,没有锁的概念、利用if判断,执行效率高。此概念主要应用在用户态线程中。
1 ‘‘‘ 2 3、协程函数 3 协程函数就是使用了yield表达式形式的生成器 4 ‘‘‘ 5 def deco(func): 6 def warrper(*args, **kwargs): 7 res = func(*args, **kwargs) 8 res.send(None) # 初始化生成器 9 return res 10 return warrper 11 12 @deco 13 def eater(name): 14 print(‘%s ready to eat!!!‘ % name) 15 food_list = [] 16 while True: 17 food = yield food_list 18 # 因yield,程序在这里停顿,所以,要添加yield返回值操作,必须在yield后 19 food_list.append(food) 20 print(‘%s eating %s‘ % (name, food)) 21 22 g = eater(‘alex‘) 23 #next(g) # g.send(None) 24 print(g.send(‘面条‘)) 25 print(g.send(‘馒头‘)) 26 print(g.send(‘包子‘)) 27 28 ‘‘‘ 29 结果: 30 alex ready to eat!!! 31 alex eating 面条 32 [‘面条‘] 33 alex eating 馒头 34 [‘面条‘, ‘馒头‘] 35 alex eating 包子 36 [‘面条‘, ‘馒头‘, ‘包子‘] 37 ‘‘‘
ps.协程的概念:
为了进一步减小内核态线程上下文切换的开销,于是又有了用户态线程设计,即纤程(Fiber)。如果连时钟阻塞、 线程切换这些功能我们都不需要了,自己在进程里面写一个逻辑流调度的东西。那么我们即可以利用到并发优势,又可以避免反复系统调用,还有进程切换造成的开销,分分钟给你上几千个逻辑流不费力。这就是用户态线程。
4、协程函数示例:仿grep -rl ‘python’ /root
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 ‘‘‘ 5 yield的应用场景 6 grep -rl ‘python‘ /root 7 ‘‘‘ 8 import os 9 10 def init(func): 11 def wrapper(*args, **kwargs): 12 res = func(*args, **kwargs) 13 next(res) 14 return res 15 return wrapper 16 17 # 第一个@init必须写,否则生成器无法完成全部代码的初始化 18 @init 19 def search(target): 20 ‘‘‘ 21 拼接字符串 22 :param target: 生成器内存地址 23 :return: 24 ‘‘‘ 25 while True: 26 search_path = yield 27 # os.walk() 方法用于通过在目录树种游走输出在目录中的文件名,向上或者向下 28 # 结果:(‘a‘, [‘b‘], [‘a.txt‘, ‘__init__.py‘])(目录名,子目录,文件) 29 g = os.walk(search_path) 30 for par_dir, _, files in g: 31 for file in files: 32 # r‘‘为原生字符串,不经过python解释器编译(windows下路径表示尤为有用) 33 file_abs_path = r‘%s\%s‘ %(par_dir, file) 34 # print(file_abs_path) 35 # 下一层生成器 36 target.send(file_abs_path) 37 @init 38 def opener(target): 39 ‘‘‘ 40 打开文件 41 :param target: 生成器内存地址 42 :return: 查看文件内容生成器发送文件地址,文件句柄 43 ‘‘‘ 44 while True: 45 file_abs_path = yield # 接收search传递的路径 46 with open(file_abs_path, encoding=‘utf-8‘) as f: 47 #print(f) 48 target.send((file_abs_path, f)) # send多个用元组的方式,为了把文件的路径传递下去 49 50 # g = search(opener()) 51 # g.send(‘a‘) 52 ‘‘‘ 53 结果: 54 <_io.TextIOWrapper name=‘a/a.txt‘ mode=‘r‘ encoding=‘utf-8‘> 55 <_io.TextIOWrapper name=‘a/__init__.py‘ mode=‘r‘ encoding=‘utf-8‘> 56 <_io.TextIOWrapper name=‘a\\b/b.txt‘ mode=‘r‘ encoding=‘utf-8‘> 57 <_io.TextIOWrapper name=‘a\\b/__init__.py‘ mode=‘r‘ encoding=‘utf-8‘> 58 <_io.TextIOWrapper name=‘a\\b\\c/c.txt‘ mode=‘r‘ encoding=‘utf-8‘> 59 <_io.TextIOWrapper name=‘a\\b\\c/__init__.py‘ mode=‘r‘ encoding=‘utf-8‘> 60 <_io.TextIOWrapper name=‘a\\b\\c\\d/d.txt‘ mode=‘r‘ encoding=‘utf-8‘> 61 <_io.TextIOWrapper name=‘a\\b\\c\\d/__init__.py‘ mode=‘r‘ encoding=‘utf-8‘> 62 ‘‘‘ 63 64 @init 65 def cat(target): 66 ‘‘‘ 67 查看文件内容 68 :param target: 生成器内存地址 69 :return: 查找匹配line生成器,文件地址和一行内容 70 ‘‘‘ 71 while True: 72 file_abs_path, f = yield 73 for line in f: 74 tag = target.send((file_abs_path, line)) 75 # 优化函数,文件找到关键字则返回文件,tag为此标记 76 if tag: 77 break 78 79 @init 80 def grep(target, pattern): 81 ‘‘‘ 82 查找匹配line 83 :param target: 生成器内存地址 84 :param pattern: 查询的关键字 85 :return: 打印行生成器,发送文件地址 86 ‘‘‘ 87 # 优化函数,文件找到关键字则返回文件,tag为此标记 88 tag = False 89 while True: 90 file_abs_path, line = yield tag 91 # tag此标记,初始化写在yield之后 92 tag = False 93 if pattern in line: 94 tag = True 95 target.send(file_abs_path) 96 97 @init 98 def printer(): 99 ‘‘‘ 100 打印行 101 :return: 102 ‘‘‘ 103 while True: 104 file_abs_path = yield 105 print(file_abs_path) 106 107 108 x = r‘D:\old_boy\old_boy_17_05\a‘ 109 g = search(opener(cat(grep(printer(),‘python‘)))) 110 print(g) 111 g.send(x) 112 113 ‘‘‘ 114 结果: 115 <generator object search at 0x0000004FFDCCB780> 116 D:\old_boy\old_boy_17_05\a\a.txt 117 D:\old_boy\old_boy_17_05\a\__init__.py 118 D:\old_boy\old_boy_17_05\a\b\b.txt 119 D:\old_boy\old_boy_17_05\a\b\__init__.py 120 D:\old_boy\old_boy_17_05\a\b\c\__init__.py 121 D:\old_boy\old_boy_17_05\a\b\c\d\d.txt 122 D:\old_boy\old_boy_17_05\a\b\c\d\__init__.py 123 ‘‘‘
ps.
a.有yield的函数,必须@init初始化(next(<g>))
b.这种写法,必须层层嵌套调用,不能漏下任何一行。
c. a目录结构:
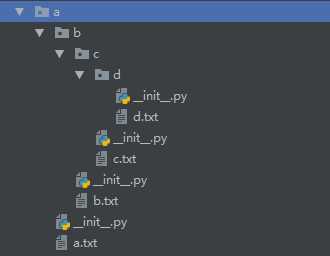
是一种流水线式的编程思路,是机械式。以上grep -rl ‘python‘ /root实例就是一个典型的面向过程编程。
1、优点:
程序的结构清晰,可以把复杂的问题简单
2、缺点:
扩展性差
3、应用场景:
linux内核,git,httpd
ps.本节只是浅浅的讨论一下,后续会有详细分析。
递归算法是一种直接或者间接地调用自身算法的过程。在计算机编写程序中,递归算法对解决一大类问题是十分有效的,它往往使算法的描述简洁而且易于理解。
a.特点:
递归算法解决问题的特点:
ps.所以一般不提倡用递归算法设计程序。
b.要求:
递归算法所体现的“重复”一般有三个要求:
方式一:在函数调用自身
1 # 书写方式1: 2 def f1(): 3 print(‘from f1‘) 4 f1() 5 f1() 6 ‘‘‘ 7 结果: 8 from f1 9 from f1 10 from f1 11 from f1 f1() 12 File "D:/old_boy/old_boy_17_05/递归调用.py", line 32, in f1 13 f1() 14 [Previous line repeated 993 more times] 15 File "D:/old_boy/old_boy_17_05/递归调用.py", line 31, in f1 16 print(‘from f1‘) 17 RecursionError: maximum recursion depth exceeded while calling a Python object 18 递归超过文件最大限制 19 ‘‘‘
方式二:在过程里调用自身
1 # 书写方式2: 2 def f1(): 3 print(‘f1‘) 4 f2() 5 6 def f2(): 7 print(‘f2‘) 8 f1() 9 10 f1() 11 ‘‘‘ 12 结果: 13 f1 14 f2 15 f1 16 f2 17 f1 18 f2 19 f1 20 f2 21 RecursionError: maximum recursion depth exceeded while calling a Python object 22 递归超过文件最大限制 23 ‘‘‘
1、简单的递归示例
import sys # 查看当前递归最大值,默认为1000 print(sys.getrecursionlimit()) # 修改当前递归最大值 print(sys.setrecursionlimit(1000000)) print(sys.getrecursionlimit()) ‘‘‘ 结果: 1000 None 1000000 ‘‘‘
2、递归应用之二分法
#递归应用之二分法:
1 #递归应用之二分法: 2 # l = range(0,400000) 3 l = [1, 2, 10,33,53,71,73,75,77,85,101,201,202,999,11111] 4 5 def search(find_num,seq): 6 if len(seq) == 0: 7 print(‘not exists‘) 8 return 9 mid_index=len(seq)//2 10 mid_num=seq[mid_index] 11 print(seq,mid_num) 12 if find_num > mid_num: 13 #in the right 14 seq=seq[mid_index+1:] 15 search(find_num,seq) 16 elif find_num < mid_num: 17 #in the left 18 seq=seq[:mid_index] 19 search(find_num,seq) 20 else: 21 print(‘find it‘) 22 23 search(77,l) 24 ‘‘‘ 25 结果: 26 [1, 2, 10, 33, 53, 71, 73, 75, 77, 85, 101, 201, 202, 999, 11111] 75 27 [77, 85, 101, 201, 202, 999, 11111] 201 28 [77, 85, 101] 85 29 [77] 77 30 find it 31 ‘‘‘ 32 # search(72,l) 33 ‘‘‘ 34 结果: 35 [1, 2, 10, 33, 53, 71, 73, 75, 77, 85, 101, 201, 202, 999, 11111] 75 36 [1, 2, 10, 33, 53, 71, 73] 33 37 [53, 71, 73] 71 38 [73] 73 39 not exists 40 ‘‘‘
3、尾递归优化
待补全
匿名函数就是不需要显式的指定函数,python中使用lambda 函数是一种快速定义单行的最小函数,可以用在任何需要函数的地方。
配合一些内置函数的使用,可以更加强大,但依旧为简单的函数:
支持lambda的内置函数如下:
max、min、zip、sorted
map、reduce、filter
匿名函数优点:
a. 程序一次行使用,所以不需要定义函数名,节省内存中变量定义空间
b. 如果想让程序更加简洁时。
1、常规使用
1 # 正常函数 2 def func(x,y): 3 return x+y 4 print(func(1,2)) 5 ‘‘‘ 6 结果: 7 3 8 ‘‘‘ 9 10 11 # 匿名函数 12 f=lambda x,y:x+y 13 print(f) 14 print(f(1,2)) 15 ‘‘‘ 16 结果: 17 <function <lambda> at 0x0000001C641BC8C8> 18 3 19 ‘‘‘
、max、min、zip、sort结合应用
max max(sequence,key=<lambda 值:表达式>==func) 最大值
min min(sequence,key=<lambda 值:表达式>==func) 最小值
zip zip(sequence,sequence) 两个sequence的len()值必须相等,拉链函数,字典
sorted sorted(可迭代对象,key=<lambda 值:表达式>==func,reverse=True ) 排序函数,默认从小到大,reverse反转
1 #max,min,zip,sorted的用法 2 # 字典的运算:最小值,最大值,排序方法一: 3 # salaries={ 4 # ‘egon‘:3000, 5 # ‘alex‘:100000000, 6 # ‘wupeiqi‘:10000, 7 # ‘yuanhao‘:2000 8 # } 9 # 迭代字典,key值,默认的key值是不对的 10 salaries={ 11 ‘egon‘:3000, 12 ‘alex‘:100000000, 13 ‘wupeiqi‘:10000, 14 ‘yuanhao‘:2000 15 } 16 # print(max(salaries)) 17 ‘‘‘ 18 结果: 19 yuanhao 20 ‘‘‘ 21 # print(min(salaries)) 22 ‘‘‘ 23 结果: 24 alex 25 ‘‘‘ 26 27 # 迭代字典,取得指定key,因而比较的是key的最大和最小值 28 salaries={ 29 ‘egon‘:3000, 30 ‘alex‘:100000000, 31 ‘wupeiqi‘:10000, 32 ‘yuanhao‘:2000 33 } 34 # print(max(salaries,key=lambda k:salaries[k])) 35 ‘‘‘ 36 结果: 37 alex 38 ‘‘‘ 39 # print(min(salaries,key=lambda k:salaries[k])) 40 ‘‘‘ 41 结果: 42 yuanhao 43 ‘‘‘ 44 45 # 也可以通过zip的方式实现 46 # salaries={ 47 # ‘egon‘:3000, 48 # ‘alex‘:100000000, 49 # ‘wupeiqi‘:10000, 50 # ‘yuanhao‘:2000 51 # } 52 # res=zip(salaries.values(),salaries.keys()) 53 # # print(list(res)) 54 # print(max(res)) 55 ‘‘‘ 56 结果: 57 (100000000, ‘alex‘) 58 ‘‘‘ 59 60 # 相当于 61 # salaries={ 62 # ‘egon‘:3000, 63 # ‘alex‘:100000000, 64 # ‘wupeiqi‘:10000, 65 # ‘yuanhao‘:2000 66 # } 67 # def func(k): 68 # return salaries[k] 69 70 # print(max(salaries,key=func)) 71 72 # sorted排序 73 # salaries={ 74 # ‘egon‘:3000, 75 # ‘alex‘:100000000, 76 # ‘wupeiqi‘:10000, 77 # ‘yuanhao‘:2000 78 # } 79 # print(sorted(salaries)) #默认的排序结果是从小到大 80 # print(sorted(salaries,key=lambda x:salaries[x])) #默认的金钱排序结果是从小到大 81 # print(sorted(salaries,key=lambda x:salaries[x],reverse=True)) #默认的金钱排序结果是从大到小 82 ‘‘‘ 83 结果: 84 [‘alex‘, ‘egon‘, ‘wupeiqi‘, ‘yuanhao‘] 85 [‘yuanhao‘, ‘egon‘, ‘wupeiqi‘, ‘alex‘] 86 [‘alex‘, ‘wupeiqi‘, ‘egon‘, ‘yuanhao‘] 87 ‘‘‘
、map、reduce、filter结合应用
a.map map(function, sequence[, sequence, ...]) -> list
对sequence中的item依次执行function(item),执行结果输出为list。
>>> map(str, range(5)) #对range(5)各项进行str操作 [‘0‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘] #返回列表 >>> def add(n):return n+n ... >>> map(add, range(5)) #对range(5)各项进行add操作 [0, 2, 4, 6, 8] >>> map(lambda x:x+x,range(5)) #lambda 函数,各项+本身 [0, 2, 4, 6, 8] >>> map(lambda x:x+1,range(10)) #lambda 函数,各项+1 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> map(add,‘zhoujy‘) [‘zz‘, ‘hh‘, ‘oo‘, ‘uu‘, ‘jj‘, ‘yy‘] #想要输入多个序列,需要支持多个参数的函数,注意的是各序列的长度必须一样,否则报错: >>> def add(x,y):return x+y ... >>> map(add,‘zhoujy‘,‘Python‘) [‘zP‘, ‘hy‘, ‘ot‘, ‘uh‘, ‘jo‘, ‘yn‘] >>> def add(x,y,z):return x+y+z ... >>> map(add,‘zhoujy‘,‘Python‘,‘test‘) #‘test‘的长度比其他2个小 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: add() takes exactly 2 arguments (3 given) >>> map(add,‘zhoujy‘,‘Python‘,‘testop‘) [‘zPt‘, ‘hye‘, ‘ots‘, ‘uht‘, ‘joo‘, ‘ynp‘]
b.reduce reduce(function, sequence[, initial]) -> value
对sequence中的item顺序迭代调用function,函数必须要有2个参数。要是有第3个参数,则表示初始值,可以继续调用初始值,返回一个值。
python3中,需要python3中需要from functools import reduce才能调用
1 >>> def add(x,y):return x+y 2 ... 3 >>> reduce(add,range(10)) #1+2+3+...+9 4 45 5 >>> reduce(add,range(11)) #1+2+3+...+10 6 55 7 >>> reduce(lambda x,y:x*y,range(1,3),5) #lambda 函数,5是初始值, 1*2*5 8 10 9 >>> reduce(lambda x,y:x*y,range(1,6)) #阶乘,1*2*3*4*5 10 120 11 >>> reduce(lambda x,y:x*y,range(1,6),3) #初始值3,结果再*3 12 360 13 >>> reduce(lambda x,y:x+y,[1,2,3,4,5,6]) #1+2+3+4+5+6 14 21
c.filter filter(function or None, sequence) -> list, tuple, or string
对sequence中的item依次执行function(item),将执行结果为True(!=0)的item组成一个List/String/Tuple(取决于sequence的类型)返回,False则退出(0),进行过滤。
1 >>> def div(n):return n%2 2 ... 3 >>> filter(div,range(5)) #返回div输出的不等于0的真值 4 [1, 3] 5 >>> filter(div,range(10)) 6 [1, 3, 5, 7, 9] 7 >>> filter(lambda x : x%2,range(10)) #lambda 函数返回奇数,返回列表 8 [1, 3, 5, 7, 9] 9 >>> filter(lambda x : not x%2,range(10)) 10 [0, 2, 4, 6, 8] 11 >>> def fin(n):return n!=‘z‘ #过滤‘z‘ 函数,出现z则返回False 12 ... 13 >>> filter(fin,‘zhoujy‘) #‘z‘被过滤 14 ‘houjy‘ 15 >>> filter(lambda x : x !=‘z‘,‘zhoujy‘) #labmda返回True值 16 ‘houjy‘ 17 >>> filter(lambda x : not x==‘z‘,‘zhoujy‘) #返回:字符串 18 ‘houjy‘
d.map、reduce、filter应用示例:
实现5!+4!+3!+2!+1!
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 def add_factorial(n): 4 empty_list=[] #声明一个空列表,存各个阶乘的结果,方便这些结果相加 5 for i in map(lambda x:x+1,range(n)): #用传进来的变量(n)来生成一个列表,用map让列表都+1,eg:range(5) => [1,2,3,4,5] 6 a=reduce(lambda x,y:x*y,map(lambda x:x+1,range(i))) #生成阶乘,用map去掉列表中的0 7 empty_list.append(a) #把阶乘结果append到空的列表中 8 return empty_list 9 if __name__ == ‘__main__‘: 10 import sys 11 #2选1 12 #(一) 13 try: 14 n = input("Enter a Number(int) : ") 15 result=add_factorial(n) #传入变量 16 print reduce(lambda x,y:x+y,result) #阶乘结果相加 17 except (NameError,TypeError): 18 print "That‘s not a Number!" 19 #(二) 20 # result = add_factorial(int(sys.argv[1])) #传入变量 21 # print reduce(lambda x,y:x+y,result) #阶乘结果相加
将100~200以内的质数挑选出来
1 ‘‘‘ 2 思路: 3 4 质数是指:只有1和它本身两个因数,如2、3、5、7都是质数,即能被1和本身整除,1不是质数。 5 比如一个数字N,看它是否质数的话,就要看:有没有能整除【2,N】之间的数X(不包含本身),即N%X是否为0,要是没有就为质数。 6 所以我们要实现的算法是:拿一个数字N,去除以【2,N】之间的数X,来得到质数,即:N/2,N/3,……,N/N-2,N/N-1 ===> N/range(2,N) 7 ‘‘‘ 8 #!/usr/bin/env python 9 #-*- coding:utf-8 -*- 10 def is_prime(start,stop): 11 stop = stop+1 #包含列表右边的值 12 prime = filter(lambda x : not [x%i for i in range(2,x) if x%i == 0],range(start,stop)) #取出质数,x从range(start,stop) 取的数 13 print prime 14 15 if __name__ == ‘__main__‘: 16 try : 17 start = input("Enter a start Number :") 18 except : 19 start = 2 #开始值默认2 20 try : 21 stop = input("Enter a stop Number :") 22 except : 23 stop = 0 #停止数,默认0,即不返回任何值 24 is_prime(start,stop) 25 ‘‘‘ 26 结果: 27 Enter a start Number :10 28 Enter a stop Number :20 29 [11, 13, 17, 19] 30 ‘‘‘
一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
a.为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用。
b.模块的搜索顺序:
c.模块分为三种:
ps.需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名
1、导入模块:
示例文件spam.py(执行文件同级目录)
1 print(‘from the spam.py‘) 2 money = 1000 3 4 def read1(): 5 print(‘spam->read1->money‘, money) 6 7 def read2(): 8 print(‘spam->read2->calling read1‘) 9 read1() 10 11 def change(): 12 global money 13 money = 0
a.模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行.(python的内存优化手段)
b.每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突.
1 # 只在第一次导入时才执行spam.py内代码,此处的显式效果是只打印一次‘from the spam.py‘,当然其他的顶级代码也都被执行了,只不过没有显示效果. 2 # import spam_mod 3 # import spam_mod 4 # import spam_mod 5 # import spam_mod 6 ‘‘‘ 7 结果: 8 from the spam_moy.py 9 ‘‘‘ 10 11 #测试一:money与spam.money不冲突 12 # import spam_mod 13 # money=10 14 # print(spam_mod.money) 15 ‘‘‘ 16 结果: 17 from the spam_mod.py 18 1000 19 ‘‘‘ 20 21 # 测试二:read1与spam.read1不冲突 22 # import spam_mod 23 # def read1(): 24 # print(‘========‘) 25 # spam_mod.read1() 26 ‘‘‘ 27 结果: 28 from the spam_mod.py 29 spam_mod->read1->money 1000 30 ‘‘‘ 31 32 # 测试三:执行spam.change()操作的全局变量money仍然是spam中的 33 # import spam_mod 34 # money=1 35 # spam_mod.change() 36 # print(money) 37 38 ‘‘‘ 39 执行结果: 40 from the spam_mod.py 41 1 42 ‘‘‘
ps.import导入时所做的事情:
1.产生新的名称空间
2.以新建的名称空间为全局名称空间,执行文件的代码
3.拿到一个模块名spam,指向spam.py产生的名称空间
对比import spam,会将源文件的名称空间‘spam‘带到当前名称空间中,使用时必须是spam.名字的方式而from 语句相当于import,也会创建新的名称空间,但是将spam中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了.
对比import:
优点:方便,不用加前缀
缺点:容易跟当前文件的名称空间冲突
1 # from spam import read1,read2 2 3 # 测试一:导入的函数read1,执行时仍然回到spam.py中寻找全局变量money 4 # from spam_mod import read1 5 # money=1000 6 # read1() 7 ‘‘‘ 8 执行结果: 9 from the spam.py 10 spam_mod->read1->money 1000 11 ‘‘‘ 12 13 #测试二:导入的函数read2,执行时需要调用read1(),仍然回到spam.py中找read1() 14 # from spam_mod import read2 15 # def read1(): 16 # print(‘==========‘) 17 # read2() 18 19 ‘‘‘ 20 执行结果: 21 from the spam.py 22 spam_mod->read2->calling read1 23 spam_mod->read1->money 1000 24 ‘‘‘ 25 26 # 测试三:导入的函数read1,被当前位置定义的read1覆盖掉了 27 # from spam_mod import read1 28 # def read1(): 29 # print(‘==========‘) 30 # read1() 31 ‘‘‘ 32 执行结果: 33 from the spam.py 34 ========== 35 ‘‘‘
-加as,别名写法:
from spam_mod import read1 as read
-多行写法:
from spam import (read1,
read2,
money)
-*写法:from spam import *, 把spam中所有的不是以下划线(_)开头的名字都导入到当前位置
1 # from spam import * 2 from spam_mod import * #将模块spam中所有的名字都导入到当前名称空间 3 print(money) 4 print(read1) 5 print(read2) 6 print(change) 7 8 ‘‘‘ 9 执行结果: 10 from the spam_mod.py 11 1000 12 <function read1 at 0x1012e8158> 13 <function read2 at 0x1012e81e0> 14 <function change at 0x1012e8268> 15 ‘‘‘
ps.form ... import ...导入时所做的事情:
1.产生新的名称空间
2.以新建的名称空间为全局名称空间,执行文件的代码
3.直接拿到就是spam.py产生的名称空间中名字
2、__all__变量与__name__变量
1 from spam_mod import * 2 print(money) # 加入的可以执行 3 read1() # 没有加入__all__的执行报错 4 5 ‘‘‘ 6 结果: 7 from the spam_mod.py 8 1000 9 Traceback (most recent call last): 10 File "D:/old_boy/old_boy_17_05/模块/mod_py.py", line 167, in <module> 11 read1() 12 NameError: name ‘read1‘ is not defined 13 ‘‘‘
ps.使用 importlib.reload(), e.g. import importlib; 可以重载被倒入的模块,这只能用于测试环境。
ps.作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
1 def fib(n): # write Fibonacci series up to n 2 a, b = 0, 1 3 while b < n: 4 print(b, end=‘ ‘) 5 a, b = b, a+b 6 print() 7 8 def fib2(n): # return Fibonacci series up to n 9 result = [] 10 a, b = 0, 1 11 while b < n: 12 result.append(b) 13 a, b = b, a+b 14 return result 15 16 if __name__ == "__main__": 17 import sys 18 fib(int(5))
3、编译模块
python -O/-OO <文件>.py
a.模块名区分大小写,foo.py与FOO.py代表的是两个模块
b.你可以使用-O或者-OO转换python命令来减少编译模块的大小
-O转换会帮你去掉assert语句
-OO转换会帮你去掉assert语句和__doc__文档字符串
由于一些程序可能依赖于assert语句或文档字符串,你应该在在确认需要的情况下使用这些选项。
c.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快的
d.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件
模块可以作为一个脚本(使用python -m compileall)编译Python源
python -m compileall /module_directory 递归着编译
如果使用python -O -m compileall /module_directory -l则只一层
命令行里使用compile()函数时,自动使用python -O -m compileall
4、dir函数
内建函数dir是用来查找模块中定义的名字,返回一个有序字符串列表
import spam
dir(spam)
如果没有参数,dir()列举出当前定义的名字。dir()不会列举出内建函数或者变量的名字,它们都被定义到了标准模块builtin中,可以列举出它们,
import builtins
dir(builtins)
Packages are a way of structuring Python’s module namespace by using “dotted module names”
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。即所谓Package, 就是一堆module的集合,也就一堆.py文件。 你可以用如下方式来创建一个package
a.无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
b.包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
c.import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
ps.注意事项
a.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
b.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
c.对比import item 和from item import name的应用场景:如果我们想直接使用name那必须使用后者。
测试文件路径及文件内容
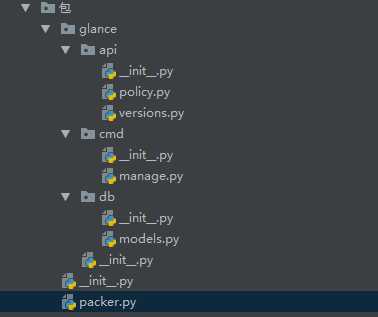
文件内容:
1 # #policy.py 2 # def get(): 3 # print(‘from policy.py‘) 4 # 5 # #versions.py 6 # def create_resource(conf): 7 # print(‘from version.py: ‘,conf) 8 # 9 # #manage.py 10 # def main(): 11 # print(‘from manage.py‘) 12 # 13 # #models.py 14 # def register_models(engine): 15 # print(‘from models.py: ‘,engine)
1、包的调用方式
1 # import glance.db.models 2 # glance.db.models.register_models(‘mysql‘) 3 ‘‘‘ 4 结果: 5 from models.py: mysql 6 ‘‘‘
1 ‘‘‘ 2 from... import... 3 ‘‘‘ 4 from glance.db import models 5 models.register_models(‘mysql‘) 6 7 from glance.db.models import register_models 8 register_models(‘mysql‘) 9 ‘‘‘ 10 结果: 11 from models.py: mysql 12 from models.py: mysql 13 ‘‘‘
在api目录中的__init__中写入:
1 #在__init__.py中定义 2 x=10 3 4 def func(): 5 print(‘from api.__init.py‘) 6 7 __all__=[‘x‘,‘func‘,‘policy‘]
在packer.py文件中写入:
1 # from glance.api import * 2 # print(x) # 在__init__中写了,可调用 3 # print(func) # 在__init__中写了,可执行 4 # print(policy.get()) # __all__ 中写了,所以ok 5 # print(versions.create_resource) # 找不到 6 ‘‘‘ 7 10 8 <function func at 0x000000717E09C9D8> 9 from policy.py 10 None 11 Traceback (most recent call last): 12 File "D:/old_boy/old_boy_17_05/包/packer.py", line 86, in <module> 13 print(versions.create_resource) 14 NameError: name ‘versions‘ is not defined 15 ‘‘‘
ps.不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
2、绝对导入和相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
1 # 绝对导入 2 from glance.cmd import manage 3 manage.main() 4 5 #相对导入 6 from ..db import models 7 models.register_models(‘mysql‘)
1 from glance.api import versions 2 ‘‘‘ 3 结果: 4 from manage.py 5 from models.py: mysql 6 ‘‘‘
ps.测试结果:注意一定要在于glance同级的文件中测试。
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
1、常用匹配模式(元字符)
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a‘,‘m‘或‘k‘ |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字 |
| \W | 匹配非字母数字 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b‘ 可以匹配"never" 中的 ‘er‘,但不能匹配 "verb" 中的 ‘er‘。 |
| \B | 匹配非单词边界。‘er\B‘ 能匹配 "verb" 中的 ‘er‘,但不能匹配 "never" 中的 ‘er‘。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的子表达式。 |
| \10 |
匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
1 # =================================匹配模式================================= 2 #一对一的匹配 3 # ‘hello‘.replace(old,new) 4 # ‘hello‘.find(‘pattern‘) 5 6 #正则匹配 7 import re 8 #\w与\W 9 print(re.findall(‘\w‘,‘hello egon 123‘)) #[‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘e‘, ‘g‘, ‘o‘, ‘n‘, ‘1‘, ‘2‘, ‘3‘] 10 print(re.findall(‘\W‘,‘hello egon 123‘)) #[‘ ‘, ‘ ‘] 11 12 #\s与\S 13 print(re.findall(‘\s‘,‘hello egon 123‘)) #[‘ ‘, ‘ ‘, ‘ ‘, ‘ ‘] 14 print(re.findall(‘\S‘,‘hello egon 123‘)) #[‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘e‘, ‘g‘, ‘o‘, ‘n‘, ‘1‘, ‘2‘, ‘3‘] 15 16 #\d与\D 17 print(re.findall(‘\d‘,‘hello egon 123‘)) #[‘1‘, ‘2‘, ‘3‘] 18 print(re.findall(‘\D‘,‘hello egon 123‘)) #[‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘ ‘, ‘e‘, ‘g‘, ‘o‘, ‘n‘, ‘ ‘] 19 20 #\A与\D 21 print(re.findall(‘\Ahe‘,‘hello egon 123‘)) #[‘he‘],\A==>^ 22 print(re.findall(‘123\Z‘,‘hello egon 123‘)) #[‘he‘],\Z==>$ 23 24 #\n与\t 25 print(re.findall(r‘\n‘,‘hello egon \n123‘)) #[‘\n‘] 26 print(re.findall(r‘\t‘,‘hello egon\t123‘)) #[‘\n‘] 27 28 #^与$ 29 print(re.findall(‘^h‘,‘hello egon 123‘)) #[‘h‘] 30 print(re.findall(‘3$‘,‘hello egon 123‘)) #[‘3‘] 31 32 # 重复匹配:| . | * | ? | .* | .*? | + | {n,m} | 33 #. 34 print(re.findall(‘a.b‘,‘a1b‘)) #[‘a1b‘] 35 print(re.findall(‘a.b‘,‘a\nb‘)) #[] 36 print(re.findall(‘a.b‘,‘a\nb‘,re.S)) #[‘a\nb‘] 37 print(re.findall(‘a.b‘,‘a\nb‘,re.DOTALL)) #[‘a\nb‘]同上一条意思一样 38 39 #* 40 print(re.findall(‘ab*‘,‘bbbbbbb‘)) #[] 41 print(re.findall(‘ab*‘,‘a‘)) #[‘a‘] 42 print(re.findall(‘ab*‘,‘abbbb‘)) #[‘abbbb‘] 43 44 #? 45 print(re.findall(‘ab?‘,‘a‘)) #[‘a‘] 46 print(re.findall(‘ab?‘,‘abbb‘)) #[‘ab‘] 47 #匹配所有包含小数在内的数字 48 print(re.findall(‘\d+\.?\d*‘,"asdfasdf123as1.13dfa12adsf1asdf3")) #[‘123‘, ‘1.13‘, ‘12‘, ‘1‘, ‘3‘] 49 50 #.*默认为贪婪匹配 51 print(re.findall(‘a.*b‘,‘a1b22222222b‘)) #[‘a1b22222222b‘] 52 53 #.*?为非贪婪匹配:推荐使用 54 print(re.findall(‘a.*?b‘,‘a1b22222222b‘)) #[‘a1b‘] 55 56 #+ 57 print(re.findall(‘ab+‘,‘a‘)) #[] 58 print(re.findall(‘ab+‘,‘abbb‘)) #[‘abbb‘] 59 60 #{n,m} 61 print(re.findall(‘ab{2}‘,‘abbb‘)) #[‘abb‘] 62 print(re.findall(‘ab{2,4}‘,‘abbb‘)) #[‘abb‘] 63 print(re.findall(‘ab{1,}‘,‘abbb‘)) #‘ab{1,}‘ ===> ‘ab+‘ 64 print(re.findall(‘ab{0,}‘,‘abbb‘)) #‘ab{0,}‘ ===> ‘ab*‘ 65 66 #[] 67 print(re.findall(‘a[1*-]b‘,‘a1b a*b a-b‘)) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾 68 print(re.findall(‘a[^1*-]b‘,‘a1b a*b a-b a=b‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘] 69 print(re.findall(‘a[0-9]b‘,‘a1b a*b a-b a=b‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘] 70 print(re.findall(‘a[a-z]b‘,‘a1b a*b a-b a=b aeb‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘] 71 print(re.findall(‘a[a-zA-Z]b‘,‘a1b a*b a-b a=b aeb aEb‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘] 72 73 #\# print(re.findall(‘a\\c‘,‘a\c‘)) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常 74 print(re.findall(r‘a\\c‘,‘a\c‘)) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义 75 print(re.findall(‘a\\\\c‘,‘a\c‘)) #同上面的意思一样,和上面的结果一样都是[‘a\\c‘] 76 77 #():分组 78 print(re.findall(‘ab+‘,‘ababab123‘)) #[‘ab‘, ‘ab‘, ‘ab‘] 79 print(re.findall(‘(ab)+123‘,‘ababab123‘)) #[‘ab‘],匹配到末尾的ab123中的ab 80 print(re.findall(‘(?:ab)+123‘,‘ababab123‘)) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容 81 82 #| 83 print(re.findall(‘compan(?:y|ies)‘,‘Too many companies have gone bankrupt, and the next one is my company‘)) 84 #[‘companies‘, ‘company‘]
2、re模块提供的方法介绍
1 # ===========================re模块提供的方法介绍=========================== 2 import re 3 #1 findall 4 print(re.findall(‘e‘,‘alex make love‘) ) #[‘e‘, ‘e‘, ‘e‘],返回所有满足匹配条件的结果,放在列表里 5 #2 search 6 print(re.search(‘e‘,‘alex make love‘).group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 7 8 #3 match 9 print(re.match(‘e‘,‘alex make love‘)) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match 10 11 #4 split 12 print(re.split(‘[ab]‘,‘abcd‘)) #[‘‘, ‘‘, ‘cd‘],先按‘a‘分割得到‘‘和‘bcd‘,再对‘‘和‘bcd‘分别按‘b‘分割 13 14 #5 sub 15 print(‘===>‘,re.sub(‘a‘,‘A‘,‘alex make love‘)) #===> Alex mAke love,不指定n,默认替换所有 16 print(‘===>‘,re.sub(‘a‘,‘A‘,‘alex make love‘,1)) #===> Alex make love 17 print(‘===>‘,re.sub(‘a‘,‘A‘,‘alex make love‘,2)) #===> Alex mAke love 18 print(‘===>‘,re.sub(‘^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$‘,r‘\5\2\3\4\1‘,‘alex make love‘)) #===> love make alex 19 20 print(‘===>‘,re.subn(‘a‘,‘A‘,‘alex make love‘)) #===> (‘Alex mAke love‘, 2),结果带有总共替换的个数 21 22 23 #6 compile 24 obj=re.compile(‘\d{2}‘) 25 26 print(obj.search(‘abc123eeee‘).group()) #12 27 print(obj.findall(‘abc123eeee‘)) #[‘12‘],重用了obj 28 29 # 7 应用 30 print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) #[‘h1‘] 31 print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group()) #<h1>hello</h1> 32 print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").groupdict()) #<h1>hello</h1> 33 34 print(re.search(r"<(\w+)>\w+</(\w+)>","<h1>hello</h1>").group()) 35 print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>").group()) 36 37 print(re.findall(r‘-?\d+\.?\d*‘,"1-12*(60+(-40.35/5)-(-4*3))")) #找出所有数字[‘1‘, ‘-12‘, ‘60‘, ‘-40.35‘, ‘5‘, ‘-4‘, ‘3‘] 38 39 #使用|,先匹配的先生效,|左边是匹配小数,而findall最终结果是查看分组,所有即使匹配成功小数也不会存入结果 40 #而不是小数时,就去匹配(-?\d+),匹配到的自然就是,非小数的数,在此处即整数 41 print(re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")) #找出所有整数[‘1‘, ‘-2‘, ‘60‘, ‘‘, ‘5‘, ‘-4‘, ‘3‘]
3、应用练习
#########################应用练习############################################### #_*_coding:utf-8_*_ #在线调试工具:tool.oschina.net/regex/# import re s=‘‘‘ http://www.baidu.com egon@oldboyedu.com 你好 010-3141 ‘‘‘ #最常规匹配 # content=‘Hello 123 456 World_This is a Regex Demo‘ # res=re.match(‘Hello\s\d\d\d\s\d{3}\s\w{10}.*Demo‘,content) # print(res) # print(res.group()) # # 返回一个tuple表示(m.start(), m.end()) # print(res.span()) ‘‘‘ 结果: <_sre.SRE_Match object; span=(0, 40), match=‘Hello 123 456 World_This is a Regex Demo‘> Hello 123 456 World_This is a Regex Demo (0, 40) ‘‘‘ #泛匹配 # content=‘Hello 123 456 World_This is a Regex Demo‘ # res=re.match(‘^Hello.*Demo‘,content) # print(res.group()) ‘‘‘ 结果: Hello 123 456 World_This is a Regex Demo ‘‘‘ #匹配目标,获得指定数据 # content=‘Hello 123 456 World_This is a Regex Demo‘ # res=re.match(‘^Hello\s(\d+)\s(\d+)\s.*Demo‘,content) # print(res.group()) #取所有匹配的内容 # print(res.group(1)) #取匹配的第一个括号内的内容 # print(res.group(2)) #去陪陪的第二个括号内的内容 ‘‘‘ 结果: Hello 123 456 World_This is a Regex Demo 123 456 ‘‘‘ #贪婪匹配:.*代表匹配尽可能多的字符 # import re # content=‘Hello 123 456 World_This is a Regex Demo‘ # # res=re.match(‘^He.*(\d+).*Demo$‘,content) # print(res.group(1)) #只打印6,因为.*会尽可能多的匹配,然后后面跟至少一个数字 ‘‘‘ 结果: 6 ‘‘‘ #非贪婪匹配:?匹配尽可能少的字符 # import re # content=‘Hello 123 456 World_This is a Regex Demo‘ # # res=re.match(‘^He.*?(\d+).*Demo$‘,content) # print(res.group(1)) #只打印6,因为.*会尽可能多的匹配,然后后面跟至少一个数字 ‘‘‘ 结果: 123 ‘‘‘ #匹配模式:.不能匹配换行符 content=‘‘‘Hello 123456 World_This is a Regex Demo ‘‘‘ # res=re.match(‘He.*?(\d+).*?Demo$‘,content) # print(res) #输出None # # res=re.match(‘He.*?(\d+).*?Demo$‘,content,re.S) #re.S让.可以匹配换行符 # print(res) # print(res.group(1)) ‘‘‘ 结果: None <_sre.SRE_Match object; span=(0, 39), match=‘Hello 123456 World_This\nis a Regex Demo‘> 123456 ‘‘‘ #转义: # content=‘price is $5.00‘ # res=re.match(‘price is $5.00‘,content) # print(res) # # res=re.match(‘price is \$5\.00‘,content) # print(res) ‘‘‘ 结果: None <_sre.SRE_Match object; span=(0, 14), match=‘price is $5.00‘> ‘‘‘ #总结:尽量精简,详细的如下 # 尽量使用泛匹配模式.* # 尽量使用非贪婪模式:.*? # 使用括号得到匹配目标:用group(n)去取得结果 # 有换行符就用re.S:修改模式 #re.search:会扫描整个字符串,不会从头开始,找到第一个匹配的结果就会返回 # import re # content=‘Extra strings Hello 123 456 World_This is a Regex Demo Extra strings‘ # # res=re.match(‘Hello.*?(\d+).*?Demo‘,content) # print(res) #输出结果为None # # import re # content=‘Extra strings Hello 123 456 World_This is a Regex Demo Extra strings‘ # # res=re.search(‘Hello.*?(\d+).*?Demo‘,content) # # print(res.group(1)) #输出结果为123 #re.search:只要一个结果,匹配演练, # import re # content=‘‘‘ # <tbody> # <tr id="4766303201494371851675" class="even "><td><div class="hd"><span class="num">1</span><div class="rk "><span class="u-icn u-icn-75"></span></div></div></td><td class="rank"><div class="f-cb"><div class="tt"><a href="/song?id=476630320"><img class="rpic" src="http://p1.music.126.net/Wl7T1LBRhZFg0O26nnR2iQ==/19217264230385030.jpg?param=50y50&quality=100"></a><span data-res-id="476630320" ‘‘‘ # res=re.search(‘<a\shref=.*?<b\stitle="(.*?)".*?b>‘,content) # print(res.group(1)) ‘‘‘ 结果: Traceback (most recent call last): File "D:/old_boy/old_boy_17_05/re_mod.py", line 281, in <module> print(res.group(1)) AttributeError: ‘NoneType‘ object has no attribute ‘group‘ ‘‘‘ # re.findall:找到符合条件的所有结果 # res=re.findall(‘<a\shref=.*?<b\stitle="(.*?)".*?b>‘,content) # for i in res: # print(i) ‘‘‘ 结果: 空 ‘‘‘ #re.sub:字符串替换 # import re # content=‘Extra strings Hello 123 456 World_This is a Regex Demo Extra strings‘ # # content=re.sub(‘\d+‘,‘‘,content) # print(content) ‘‘‘ 结果: Extra strings Hello World_This is a Regex Demo Extra strings ‘‘‘ #用\1取得第一个括号的内容 #用法:将123与456换位置 # import re # content=‘Extra strings Hello 123 456 World_This is a Regex Demo Extra strings‘ # # # content=re.sub(‘(Extra.*?)(\d+)(\s)(\d+)(.*?strings)‘,r‘\1\4\3\2\5‘,content) # content=re.sub(‘(\d+)(\s)(\d+)‘,r‘\3\2\1‘,content) # print(content) ‘‘‘ 结果: Extra strings Hello 456 123 World_This is a Regex Demo Extra strings ‘‘‘ # import re # content=‘Extra strings Hello 123 456 World_This is a Regex Demo Extra strings‘ # # res=re.search(‘Extra.*?(\d+).*strings‘,content) # print(res.group(1)) ‘‘‘ 结果: 123 ‘‘‘ # import requests,re # respone=requests.get(‘https://book.douban.com/‘).text # # print(respone) # print(‘======‘*1000) # print(‘======‘*1000) # print(‘======‘*1000) # print(‘======‘*1000) # res=re.findall(‘<li.*?cover.*?href="(.*?)".*?title="(.*?)">.*?more-meta.*?author">(.*?)</span.*?year">(.*?)</span.*?publisher">(.*?)</span.*?</li>‘,respone,re.S) # # res=re.findall(‘<li.*?cover.*?href="(.*?)".*?more-meta.*?author">(.*?)</span.*?year">(.*?)</span.*?publisher">(.*?)</span>.*?</li>‘,respone,re.S) # # # for i in res: # print(‘%s %s %s %s‘ %(i[0].strip(),i[1].strip(),i[2].strip(),i[3].strip()))
标签:栈溢出 data 命令 struct dba 而且 名称空间 数据 指令
原文地址:http://www.cnblogs.com/you0329/p/6935512.html
