标签:line 编译器 机器码 system.in guid 生成 code 区别 精度
前一篇文章中我们讲到了值类型和引用类型的一些区别,那这篇我们将深入的分析一下到底有什么不一样
先总结一下两者的差别:
黄金法则:
1.引用类型总是被分配到托管堆上。
2.值类型总是分配到它声明的地方:
a.作为引用类型的成员变量分配到托管堆上
b.作为方法的局部变量时分配到栈上
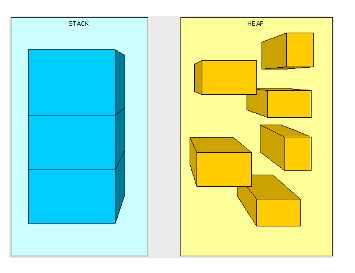
这就是栈和托管堆的区别,栈是线程级别的存储,很规整的存储结构,有先进后出的规则。在每一个线程开启的时候系统默认会给线程分配大约1M左右的栈内存。而托管堆的存储是很随意的,我们对引用类型的操作都是在托管堆上的。
那么线程栈和托管堆是如何工作的呢?我们上代码,先看栈
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
执行示意图如下:
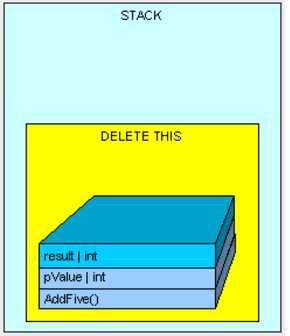
1.方法AddFive()被压入“栈”
2.紧接着方法参数pValue被压入“栈”
3.然后是需要为result变量分配空间,这时被分配到“栈”上。
4.最后返回结果
通过将栈指针指向 AddFive()方法曾使用的可用的内存地址,所有在“栈”上的该方法所使用内存都被清空,且程序将自动回到“栈“上最初的方法调用的位置。
再看托管堆
public class MyInt
{
public int MyValue;
}
public MyInt AddFive(int pValue)
{
var result = new MyInt();
result.MyValue = pValue + 5;
return result;
}
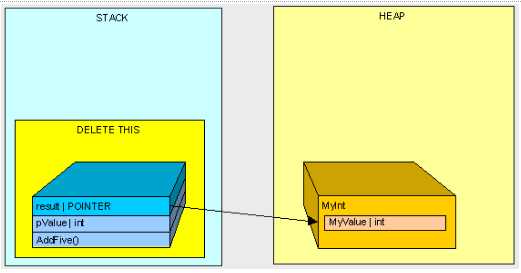
MyInt 为引用类型,它被分配在“堆”上,并且由一个位于“栈”上的指针引用,执行完之后只剩下
一个 MyInt 类被留在“堆”上(“栈”上再也没有指向这个 MyInt 类的指针),这个时候GC就回收处理
一定要记住我们上边将的黄金法则,以后千万不要一拍脑袋告诉别人值类型是在栈上,引用类型在堆上。作为一名资深的.net开发,这样的话有点幼稚了。
前面我们一直说托管堆,什么是托管呢? 我们先看一下.net的CLR执行模型:
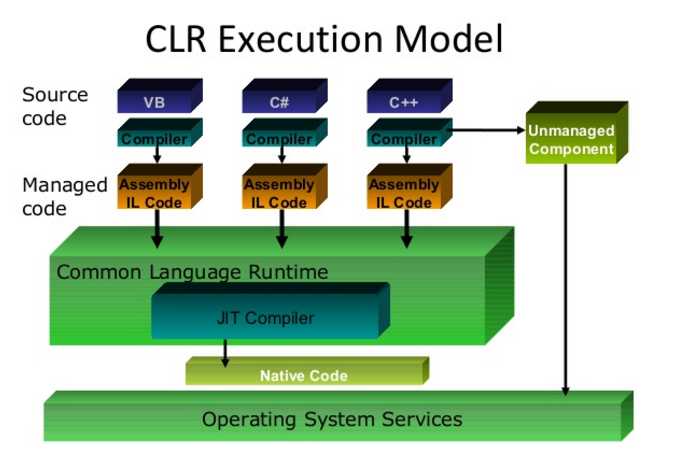
托管代码(Managed Code): 由公共语言运行库时(CLR)执行的代码,而不是由操作系统直接执行。托管代码也可以调用CLR的运行时服务和功能,比如GC、类型检查、安全支持等等。代码编写完毕后进行编译,此时编译器把代码编译成中间语言(IL),而不是能直接在你的电脑上运行的机器码。程序集(Assembly)的文件负责封装中间语言,程序集中包含了描述所创建的方法、类以及属性的所有元数据。
非托管代码(Unmanaged Code):直接编译成目标计算机的机器码,这些代码只能运行在编译出这些代码的计算机上,或者是其他相同处理器或者几乎一样处理器的计算机上。非托管代码不能享受公共语言运行库所提供的一些服务,例如内存管理、安全管理等。 如果非托管代码需要进行内存管理等服务,就必须显式地调用操作系统的接口,通常非托管代码调用Windows SDK所提供的API来实现内存管理。 非托管程序也可以通过调用COM接口来获取操作系统服务。
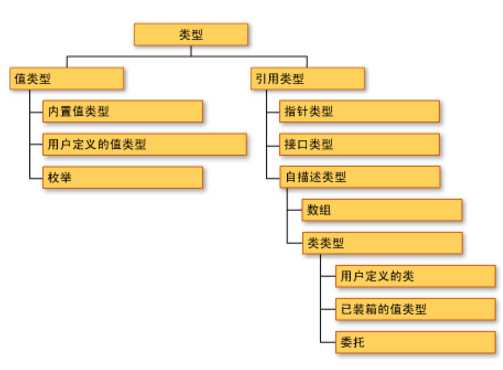
各个值类型及其基类:
结构体:struct(直接派生于System.ValueType)
数值类型:
整型:
short(System.Int16),ushort(System.UInt16)
int(System.Int32),uint(System.UInt32)
long(System.Int64),ulong(System.UInt64)
sbyte(System.SByte的别名),byte(System.Byte)
字符型:char(System.Char);
浮点型:float(System.Single),double(System.Double)
用于财务计算的高精度decimal型:decimal(System.Decimal)
bool型:bool(System.Boolean的别名)
枚举:enum(派生于System.Enum)
可空类型(派生于System.Nullable泛型结构体,语法 T? 是 System.Nullable<T> 的简
写,此处的 T 为值类型。)
值类型不能为赋值为null,而可空类型是值类型为什么可以给null值?
按照惯例,这个时候应该说一句:小二,上代码!
System.Nullable<int> number1 = null; System.Nullable<int> number2 = new System.Nullable<int>(); System.Nullable<int> number3 = 23; System.Nullable<int> number4 = new System.Nullable<int>(88);
这是我们对Nullable类型的赋值操作,我们来看一下生成的IL代码是什么样的:
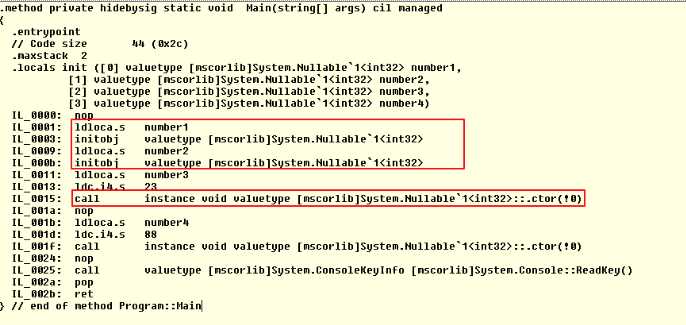
这下子就清楚了,实质上是编译器提供了这样的支持,从生成的中间代码可以看出:可空类型的赋值直接等效于构造实例。赋null时其实就是调用空构造函数,有值时就就把值传入带参数的构造函数。所以可空类型的null值和引用类型的null是不一样的。(可空类型的并不是引用类型的null,而是用结构的另一种表示方式来表示null)
各个引用类型及其基类:
数组:(派生于System.Array)数组的元素,不管是引用类型还是值类型,都存储在托管堆上
类:class(派生于System.Object)
接口:interface(接口不是一个“实际的类型”,所以不存在派生于何处的问题。)
委托:delegate(派生于System.Delegate)
object:(System.Object的别名)
字符串:string(System.String的别名)
问题1:Int[]是引用类型还是值类型 ? (根据前面讲的内容,你觉得呢?)
问题2:所有的值类型都存储在栈上吗?(根据前面讲的内容,你觉得呢?)
总结一下:
特殊类型 dynamic
dynamic是C#4.0 引入的新类型,声明为dynamic的类型与”静态类型”(编译时确定的类型,例如int,double类型)相比最大的特定它是”动态类型”,它会在运行时尝试调用方法,这些方法的存在与否不是编译时期检查的,而是在运行时查找,如果方法存在并且参数正确,会正确调用,否则会抛出异常.
dynamic类型只在编译时存在,运行时不存在,会转换为object
dynamic和var的区别
用var声明的局部变量只是一种简化语法,它要求编译器根据表达式推断数据的实际类型
var只能用于方法内部的局部变量,而dynamic可以用于方法内部的局部变量、字段和参数
表达式不能转型为var,但是可以转型为dynamic
必须显示初始化var声明的变量,但dynamic声明的变量无需初始化
关于dynamic还可以讲很多东西的,后面我们会专门讲解这个特殊类型
问题来了:只要继承自System.ValueType的都是值类型吗?
值类型都是System.ValueType的后代,但System.ValueType的后代不全是值类型,System.Enum就是唯一的特例,在System.ValueType的所有后代中,除了System.Enum之外其它都是值类型。
Enum的源码定义如下:
public abstract class Enum : ValueType, IComparable, IFormattable, IConvertible
我们可以看到它是抽象类,根据前面讲的class属于引用类型,所以他是引用类型。所以枚举值到底是值类型还是引用类型呢,各位看官请看:
枚举的特殊性:
1. 所有枚举类型(enum type)都是值类型。
2. System.Enum和System.ValueType本身是引用类型。
3. 枚举类型(enum type)都是隐式的直接继承自System.Enum,并且这种继承关系只能由 编译器自动展开。但System.Enum本身不是枚举类型(enum type)。
4. System.Enum是一个特例,它直接继承自System.ValueType(参见Code #03),但本身却是一个引用类型。
下面两位仁兄讲的很清楚,各位可以参考一下:
http://www.cnblogs.com/cdts_change/archive/2009/09/20/1570414.html
http://www.cnblogs.com/yank/archive/2009/02/27/1399423.html
讲了这么多引用类型和值类型的东西,我们来系统的总结一下:
值类型和引用类型的区别
a.所有继承System.Value的类型都是值类型(Enum特殊),其他类型都是引用类型
b.引用类型可以派生出新的类型,而值类型不能
c.引用类型存储在堆中,而值类型既可以存储在堆中也可以存储在栈中
d.引用类型可以包含null值,值类型不能(可空类型功能允许将 null 赋给值类型)
e.引用类型变量的赋值只复制对对象的引用,而不复制对象本身。而将一个值类型变量赋给另一个值类型变量时,将复制包含的值
f.当比较两个值类型时,进行的是内容比较;而比较两个引用类型时,进行的是引用比较
g.值类型在内存管理方面具有更好的效率,并且不支持多态,适合用作存储数据的载体;引用类型支持多态,适合用于定义应用程序的行为
最后再来一句:小二,上代码!
public void ValueTypeDemo()
{
RefObj ref1 = new RefObj(); // 在堆上分配
ValObj val1 = new ValObj(); //在栈上分配
ref1.Count = 5; //赋值并返回指针
val1.Count = 5; //在栈上直接修改值
Console.WriteLine(ref1.Count); //都显示5
Console.WriteLine(val1.Count);
RefObj ref2 = ref1; // 只复制引用
ValObj val2 = val1; //在栈上分配并复制成员
ref1.Count = 8; // ref1 和 ref2 都会改
val1.Count = 9; // ref1.Count 会改,但是ref2.Count 不会
Console.WriteLine(ref1.Count); // 显示 8
Console.WriteLine(ref2.Count); // 显示 8
Console.WriteLine(val1.Count); // 显示 9
Console.WriteLine(val2.Count); // 显示 5
}
public class RefObj
{
public int Count { get; set; }
}
public struct ValObj
{
public int Count { get; set; }
}
转载的童鞋请说明出处,谢谢。
标签:line 编译器 机器码 system.in guid 生成 code 区别 精度
原文地址:http://www.cnblogs.com/Wolfmanlq/p/6937169.html