标签:oba forms with nts on() alt data 转换 pac
1.collections模块
collections模块自Python 2.4版本开始被引入,包含了dict、set、list、tuple以外的一些特殊的容器类型,分别是:
OrderedDict类:排序字典,是字典的子类。引入自2.7。
namedtuple()函数:命名元组,是一个工厂函数。引入自2.6。
Counter类:为hashable对象计数,是字典的子类。引入自2.7。
deque:双向队列。引入自2.4。
defaultdict:使用工厂函数创建字典,使不用考虑缺失的字典键。引入自2.5。
文档参见:http://docs.python.org/2/library/collections.html。
2.Counter类
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
2.1 创建
下面的代码说明了Counter类创建的四种方法:
Counter类的创建Python
|
1
2
3
4
5
6
7
8
9
|
>>> c = Counter() # 创建一个空的Counter类>>> c = Counter(‘gallahad‘) # 从一个可iterable对象(list、tuple、dict、字符串等)创建>>> c = Counter({‘a‘: 4, ‘b‘: 2}) # 从一个字典对象创建>>> c = Counter(a=4, b=2) # 从一组键值对创建>>> c = Counter() # 创建一个空的Counter类>>> c = Counter(‘gallahad‘) # 从一个可iterable对象(list、tuple、dict、字符串等)创建>>> c = Counter({‘a‘: 4, ‘b‘: 2}) # 从一个字典对象创建>>> c = Counter(a=4, b=2) # 从一组键值对创建 |
当所访问的键不存在时,返回0,而不是KeyError;否则返回它的计数。
计数值的访问Python
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
>>> c = Counter("abcdefgab")>>> c["a"]2>>> c["c"]1>>> c["h"]0>>> c = Counter("abcdefgab")>>> c["a"]2>>> c["c"]1>>> c["h"]0 |
可以使用一个iterable对象或者另一个Counter对象来更新键值。
计数器的更新包括增加和减少两种。其中,增加使用update()方法:
计数器的更新(update)Python
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
>>> c = Counter(‘which‘)>>> c.update(‘witch‘) # 使用另一个iterable对象更新>>> c[‘h‘]3>>> d = Counter(‘watch‘)>>> c.update(d) # 使用另一个Counter对象更新>>> c[‘h‘]4>>> c = Counter(‘which‘)>>> c.update(‘witch‘) # 使用另一个iterable对象更新>>> c[‘h‘]3>>> d = Counter(‘watch‘)>>> c.update(d) # 使用另一个Counter对象更新>>> c[‘h‘]4 |
减少则使用subtract()方法:
计数器的更新(subtract)Python
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
>>> c = Counter(‘which‘)>>> c.subtract(‘witch‘) # 使用另一个iterable对象更新>>> c[‘h‘]1>>> d = Counter(‘watch‘)>>> c.subtract(d) # 使用另一个Counter对象更新>>> c[‘a‘]-1>>> c = Counter(‘which‘)>>> c.subtract(‘witch‘) # 使用另一个iterable对象更新>>> c[‘h‘]1>>> d = Counter(‘watch‘)>>> c.subtract(d) # 使用另一个Counter对象更新>>> c[‘a‘]-1 |
2.4 键的删除
当计数值为0时,并不意味着元素被删除,删除元素应当使用del。
键的删除Python
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
>>> c = Counter("abcdcba")>>> cCounter({‘a‘: 2, ‘c‘: 2, ‘b‘: 2, ‘d‘: 1})>>> c["b"] = 0>>> cCounter({‘a‘: 2, ‘c‘: 2, ‘d‘: 1, ‘b‘: 0})>>> del c["a"]>>> cCounter({‘c‘: 2, ‘b‘: 2, ‘d‘: 1})>>> c = Counter("abcdcba")>>> cCounter({‘a‘: 2, ‘c‘: 2, ‘b‘: 2, ‘d‘: 1})>>> c["b"] = 0>>> cCounter({‘a‘: 2, ‘c‘: 2, ‘d‘: 1, ‘b‘: 0})>>> del c["a"]>>> cCounter({‘c‘: 2, ‘b‘: 2, ‘d‘: 1}) |
2.5 elements()
返回一个迭代器。元素被重复了多少次,在该迭代器中就包含多少个该元素。所有元素按照字母序排序,个数小于1的元素不被包含。
|
1
2
3
4
5
6
7
8
9
|
elements()方法Python>>> c = Counter(a=4, b=2, c=0, d=-2)>>> list(c.elements())[‘a‘, ‘a‘, ‘a‘, ‘a‘, ‘b‘, ‘b‘]>>> c = Counter(a=4, b=2, c=0, d=-2)>>> list(c.elements())[‘a‘, ‘a‘, ‘a‘, ‘a‘, ‘b‘, ‘b‘] |
2.6 most_common([n])
返回一个TopN列表。如果n没有被指定,则返回所有元素。当多个元素计数值相同时,按照字母序排列。
most_common()方法Python
|
1
2
3
4
5
6
7
8
9
10
11
|
>>> c = Counter(‘abracadabra‘)>>> c.most_common()[(‘a‘, 5), (‘r‘, 2), (‘b‘, 2), (‘c‘, 1), (‘d‘, 1)]>>> c.most_common(3)[(‘a‘, 5), (‘r‘, 2), (‘b‘, 2)]>>> c = Counter(‘abracadabra‘)>>> c.most_common()[(‘a‘, 5), (‘r‘, 2), (‘b‘, 2), (‘c‘, 1), (‘d‘, 1)]>>> c.most_common(3)[(‘a‘, 5), (‘r‘, 2), (‘b‘, 2)] |
2.7 fromkeys
未实现的类方法。
2.8 浅拷贝copy
浅拷贝copyPython
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
>>> c = Counter("abcdcba")>>> cCounter({‘a‘: 2, ‘c‘: 2, ‘b‘: 2, ‘d‘: 1})>>> d = c.copy()>>> dCounter({‘a‘: 2, ‘c‘: 2, ‘b‘: 2, ‘d‘: 1})>>> c = Counter("abcdcba")>>> cCounter({‘a‘: 2, ‘c‘: 2, ‘b‘: 2, ‘d‘: 1})>>> d = c.copy()>>> dCounter({‘a‘: 2, ‘c‘: 2, ‘b‘: 2, ‘d‘: 1}) |
2.9 算术和集合操作
+、-、&、|操作也可以用于Counter。其中&和|操作分别返回两个Counter对象各元素的最小值和最大值。需要注意的是,得到的Counter对象将删除小于1的元素。
Counter对象的算术和集合操作Python
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
>>> c = Counter(a=3, b=1)>>> d = Counter(a=1, b=2)>>> c + d # c[x] + d[x]Counter({‘a‘: 4, ‘b‘: 3})>>> c - d # subtract(只保留正数计数的元素)Counter({‘a‘: 2})>>> c & d # 交集: min(c[x], d[x])Counter({‘a‘: 1, ‘b‘: 1})>>> c | d # 并集: max(c[x], d[x])Counter({‘a‘: 3, ‘b‘: 2})>>> c = Counter(a=3, b=1)>>> d = Counter(a=1, b=2)>>> c + d # c[x] + d[x]Counter({‘a‘: 4, ‘b‘: 3})>>> c - d # subtract(只保留正数计数的元素)Counter({‘a‘: 2})>>> c & d # 交集: min(c[x], d[x])Counter({‘a‘: 1, ‘b‘: 1})>>> c | d # 并集: max(c[x], d[x])Counter({‘a‘: 3, ‘b‘: 2}) |
3.常用操作
下面是一些Counter类的常用操作,来源于Python官方文档
Counter类常用操作Python
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
sum(c.values()) # 所有计数的总数c.clear() # 重置Counter对象,注意不是删除list(c) # 将c中的键转为列表set(c) # 将c中的键转为setdict(c) # 将c中的键值对转为字典c.items() # 转为(elem, cnt)格式的列表Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象c.most_common()[:-n:-1] # 取出计数最少的n个元素c += Counter() # 移除0和负值sum(c.values()) # 所有计数的总数c.clear() # 重置Counter对象,注意不是删除list(c) # 将c中的键转为列表set(c) # 将c中的键转为setdict(c) # 将c中的键值对转为字典c.items() # 转为(elem, cnt)格式的列表Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象c.most_common()[:-n:-1] # 取出计数最少的n个元素c += Counter() # 移除0和负值 |
4.实例
4.1判断两个字符串是否由相同的字母集合调换顺序而成的(anagram)
|
1
2
3
4
5
6
7
8
9
10
|
def is_anagram(word1, word2): """Checks whether the words are anagrams. word1: string word2: string returns: boolean """ return Counter(word1) == Counter(word2) |
Counter如果传入的参数是字符串,就会统计字符串中每个字符出现的次数,如果两个字符串由相同的字母集合颠倒顺序而成,则它们Counter的结果应该是一样的。
4.2多元集合(MultiSets)
multiset是相同元素可以出现多次的集合,Counter可以非常自然地用来表示multiset。并且可以将Counter扩展,使之拥有set的一些操作如is_subset。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class Multiset(Counter): """A multiset is a set where elements can appear more than once.""" def is_subset(self, other): """Checks whether self is a subset of other. other: Multiset returns: boolean """ for char, count in self.items(): if other[char] < count: return False return True # map the <= operator to is_subset __le__ = is_subset |
4.3概率质量函数
概率质量函数(probability mass function,简写为pmf)是离散随机变量在各特定取值上的概率。可以利用Counter表示概率质量函数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
class Pmf(Counter): """A Counter with probabilities.""" def normalize(self): """Normalizes the PMF so the probabilities add to 1.""" total = float(sum(self.values())) for key in self: self[key] /= total def __add__(self, other): """Adds two distributions. The result is the distribution of sums of values from the two distributions. other: Pmf returns: new Pmf """ pmf = Pmf() for key1, prob1 in self.items(): for key2, prob2 in other.items(): pmf[key1 + key2] += prob1 * prob2 return pmf def __hash__(self): """Returns an integer hash value.""" return id(self) def __eq__(self, other): return self is other def render(self): """Returns values and their probabilities, suitable for plotting.""" return zip(*sorted(self.items())) |
normalize: 归一化随机变量出现的概率,使它们之和为1
add: 返回的是两个随机变量分布两两组合之和的新的概率质量函数
render: 返回按值排序的(value, probability)的组合对,方便画图的时候使用
下面以骰子(ps: 这个竟然念tou子。。。)作为例子。
|
1
2
3
4
5
|
d6 = Pmf([1,2,3,4,5,6])d6.normalize()d6.name = ‘one die‘print(d6)Pmf({1: 0.16666666666666666, 2: 0.16666666666666666, 3: 0.16666666666666666, 4: 0.16666666666666666, 5: 0.16666666666666666, 6: 0.16666666666666666}) |
使用add,我们可以计算出两个骰子和的分布:
|
1
2
3
4
5
|
d6_twice = d6 + d6d6_twice.name = ‘two dices‘for key, prob in d6_twice.items(): print(key, prob) |
借助numpy.sum,我们可以直接计算三个骰子和的分布:
|
1
2
3
|
import numpy as npd6_thrice = np.sum([d6]*3)d6_thrice.name = ‘three dices‘ |
最后可以使用render返回结果,利用matplotlib把结果画图表示出来:
|
1
2
3
4
5
6
7
8
|
for die in [d6, d6_twice, d6_thrice]: xs, ys = die.render() pyplot.plot(xs, ys, label=die.name, linewidth=3, alpha=0.5)pyplot.xlabel(‘Total‘)pyplot.ylabel(‘Probability‘)pyplot.legend()pyplot.show() |
结果如下:
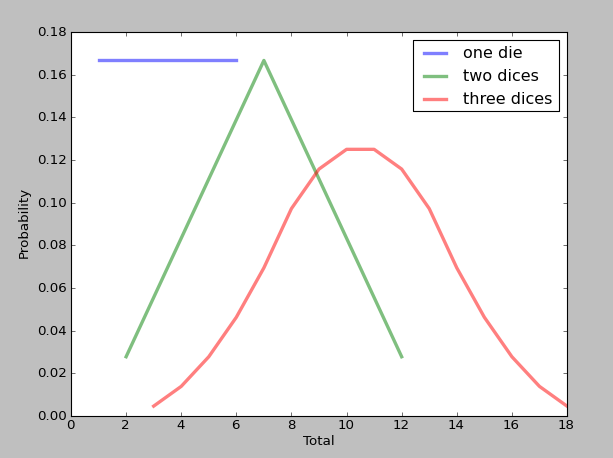
4.4贝叶斯统计
我们继续用掷骰子的例子来说明用Counter如何实现贝叶斯统计。现在假设,一个盒子中有5种不同的骰子,分别是:4面、6面、8面、12面和20面的。假设我们随机从盒子中取出一个骰子,投出的骰子的点数为6。那么,取得那5个不同骰子的概率分别是多少?
(1)首先,我们需要生成每个骰子的概率质量函数:
|
1
2
3
4
5
6
7
8
9
|
def make_die(num_sides): die = Pmf(range(1, num_sides+1)) die.name = ‘d%d‘ % num_sides die.normalize() return diedice = [make_die(x) for x in [4, 6, 8, 12, 20]]print(dice) |
(2)接下来,定义一个抽象类Suite。Suite是一个概率质量函数表示了一组假设(hypotheses)及其概率分布。Suite类包含一个bayesian_update函数,用来基于新的数据来更新假设(hypotheses)的概率。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class Suite(Pmf): """Map from hypothesis to probability.""" def bayesian_update(self, data): """Performs a Bayesian update. Note: called bayesian_update to avoid overriding dict.update data: result of a die roll """ for hypo in self: like = self.likelihood(data, hypo) self[hypo] *= like self.normalize() |
其中的likelihood函数由各个类继承后,自己实现不同的计算方法。
(3)定义DiceSuite类,它继承了类Suite。
|
1
2
3
4
5
6
7
8
9
|
class DiceSuite(Suite): def likelihood(self, data, hypo): """Computes the likelihood of the data under the hypothesis. data: result of a die roll hypo: Die object """ return hypo[data] |
并且实现了likelihood函数,其中传入的两个参数为: data: 观察到的骰子掷出的点数,如本例中的6 hypo: 可能掷出的那个骰子
(4)将第一步创建的dice传给DiceSuite,然后根据给定的值,就可以得出相应的结果。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
dice_suite = DiceSuite(dice)dice_suite.bayesian_update(6)for die, prob in sorted(dice_suite.items()): print die.name, probd4 0.0d6 0.392156862745d8 0.294117647059d12 0.196078431373d20 0.117647058824 |
正如,我们所期望的4个面的骰子的概率为0(因为4个面的点数只可能为0~4),而6个面的和8个面的概率最大。 现在,假设我们又掷了一次骰子,这次出现的点数是8,重新计算概率:
|
1
2
3
4
5
6
7
8
9
10
11
|
dice_suite.bayesian_update(8)for die, prob in sorted(dice_suite.items()): print die.name, probd4 0.0d6 0.0d8 0.623268698061d12 0.277008310249d20 0.0997229916898 |
现在可以看到6个面的骰子也被排除了。8个面的骰子是最有可能的。
以上的几个例子,展示了Counter的用处。实际中,Counter的使用还比较少,如果能够恰当的使用起来将会带来非常多的方便。
Python中Collections模块的Counter容器类使用教程
标签:oba forms with nts on() alt data 转换 pac
原文地址:http://www.cnblogs.com/monsteryang/p/6938627.html