标签:ges pytho 技术 分享 utf-8 path 学习 bsp nbsp
上一篇说到用BeautifulSoup解析源代码,下面我们就来实战一下:
1 from bs4 import BeautifulSoup 2 html = urllib.request.urlopen(‘http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93536‘) 3 html = html.read().decode(‘utf-8‘) 4 soup = BeautifulSoup(html) 5 """ 6 or you can do: 7 soup = BeautifulSoup(open(‘F:\\forpython\\Master of Counselling Studies (MCounsStuds) - 2017 - Massey University.html‘,encoding = ‘utf-8‘)) 8 """ 9 soup.find_all(‘h1‘) 10 soup.h1.get_text()
其实用open的方式可以避免decode报错,可以的话还是用open比较好。运行结果:
1 soup.find_all(‘h1‘) 2 Out[76]: [<h1>Master of Advanced Leadership Practice (<span>MALP</span>)</h1>]
噌~是不是快了许多,还有更快的:
1 soup.h1.get_text() 2 Out[75]: ‘Master of Advanced Leadership Practice (MALP)‘
h1其实是一个标签,用BeautifulSoup解析过后可以直接引用,下面我们直接引用title标签(学过html的同学会知道title标签)
1 soup.title 2 Out[79]: <title>Master of Advanced Leadership Practice (MALP) - 2017 - Massey University</title>
接下来我们用BeautifulSoup帮助我们爬一张图片: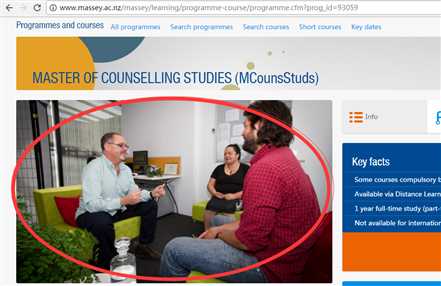
右键单击,选择‘检查’(我用的Google浏览器)
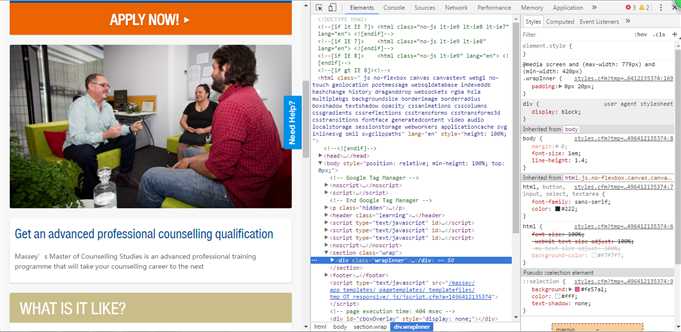
通过右边的elements一步一步的查找图片所在的源代码(你把鼠标放在源代码上会显现相应的位置)
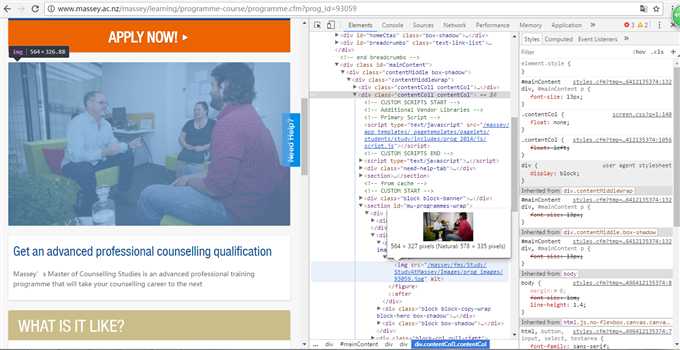
看到了吧,在<div,class="block block-feature-image">下,我们使用BeautifulSoup开始撸:
1 a = soup.find(‘div‘,{‘class‘:"block block-feature-image"}).figure.img.attrs[‘src‘] 2 # soup.figure.img.attrs[‘src‘] 这样也可以 3 a 4 Out[129]: ‘/massey/fms/Study/StudyAtMassey/Images/prog_images/93059.jpg‘
attrs是属性的意思,img.attrs[‘src‘]就是调出img对象src的属性值(这个语法我也不是很懂,好像是xpath的语法)。再把网址的头添加上去,写入本地文件:
1 a1 = ‘http://www.massey.ac.nz‘+a 2 pic = urllib.request.urlopen(a1).read() 3 pic_data=open(‘F:/1.jpg‘,‘wb‘) 4 pic_data.write(pic) 5 pic_data.close()
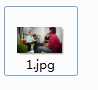
搞定
标签:ges pytho 技术 分享 utf-8 path 学习 bsp nbsp
原文地址:http://www.cnblogs.com/hahaxzy9500/p/6938676.html