标签:ase 大小 line append 指标 cond str create images
决策树---ID3算法
决策树:
以天气数据库的训练数据为例。
|
Outlook |
Temperature |
Humidity |
Windy |
PlayGolf? |
|
sunny |
85 |
85 |
FALSE |
no |
|
sunny |
80 |
90 |
TRUE |
no |
|
overcast |
83 |
86 |
FALSE |
yes |
|
rainy |
70 |
96 |
FALSE |
yes |
|
rainy |
68 |
80 |
FALSE |
yes |
|
rainy |
65 |
70 |
TRUE |
no |
|
overcast |
64 |
65 |
TRUE |
yes |
|
sunny |
72 |
95 |
FALSE |
no |
|
sunny |
69 |
70 |
FALSE |
yes |
|
rainy |
75 |
80 |
FALSE |
yes |
|
sunny |
75 |
70 |
TRUE |
yes |
|
overcast |
72 |
90 |
TRUE |
yes |
|
overcast |
81 |
75 |
FALSE |
yes |
|
rainy |
71 |
91 |
TRUE |
no |
这个例子是根据报告天气条件的记录来决定是否外出打高尔夫球。
作为分类器,决策树是一棵有向无环树。
由根节点、叶节点、内部节点、分割属性、分割判断规则构成
生成阶段:决策树的构建和决策树的修剪。
根据分割方法的不同:有基于信息论(Information Theory)的方法和基于最小GINI指数(lowest GINI index)的方法。对应前者的常见方法有ID3、C4.5,后者的有CART。
ID3 算法
ID3的基本概念是:
1) 决策树中的每一个非叶子节点对应着一个特征属性,树枝代表这个属性的值。一个叶节点代表从树根到叶节点之间的路径所对应的记录所属的类别属性值。这就是决策树的定义。
2) 在决策树中,每一个非叶子节点都将与属性中具有最大信息量的特征属性相关联。
3) 熵通常是用于测量一个非叶子节点的信息量大小的名词。
熵
热力学中表征物质状态的参量之一,用符号S表示,其物理意义是体系混乱程度的度量。热力学第二定律(second law of thermodynamics),热力学基本定律之一,又称“熵增定律”,表明在自然过程中,一个孤立系统的总混乱度(即“熵”)不会减小。
在信息论中,变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。信息熵是信息论中用于度量信息量的一个概念。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。所以,信息熵也可以说是系统有序化程度的一个度量。
信息增益的计算
定义1:若存在个相同概率的消息,则每个消息的概率是,一个消息传递的信息量为。若有16个事件,则,需要4个比特来代表一个消息。
定义2:若给定概率分布,则由该分布传递的信息量称为的熵,即
例:若是,则是1;若是,则是0.92;若
是,则是0(注意概率分布越均匀,其信息量越大)
定义3:若一个记录的集合根据类别属性的值被分为相互独立的类,则识别的一个元素所属哪个类别所需要的信息量是,其中是的概率分布,即
仍以天气数据库的数据为例。我们统计了14天的气象数据(指标包括outlook,temperature,humidity,windy),并已知这些天气是否打球(play)。如果给出新一天的气象指标数据,判断一下会不会去打球。在没有给定任何天气信息时,根据历史数据,我们知道一天中打球的概率是9/14,不打的概率是5/14。此时的熵为:
定义4:若我们根据某一特征属性将分成集合,则确定中的一个元素类的信息量可通过确定的加权平均值来得到,即的加权平均值为:
|
Outlook |
temperature |
humidity |
windy |
play |
|||||
|
|
yes |
no |
|
|
|
yes |
no |
yes |
no |
|
sunny |
2 |
3 |
False |
6 |
2 |
9 |
5 |
||
|
overcast |
4 |
0 |
True |
3 |
3 |
|
|
||
|
rainy |
3 |
2 |
|
|
|
|
|
||
针对属性Outlook,我们来计算
定义5:将信息增益定义为:
即增益的定义是两个信息量之间的差值,其中一个信息量是需确定的一个元素的信息量,另一个信息量是在已得到的属性的值后确定的一个元素的信息量,即信息增益与属性相关。
针对属性Outlook的增益值:
若用属性windy替换outlook,可以得到,。即outlook比windy取得的信息量大。
ID3算法的Python实现
import math
import operator
def calcShannonEnt(dataset):
numEntries = len(dataset)
labelCounts = {}
for featVec in dataset:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] +=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob*math.log(prob, 2)
return shannonEnt
def CreateDataSet():
dataset = [[1, 1, ‘yes‘ ],
[1, 1, ‘yes‘ ],
[1, 0, ‘no‘],
[0, 1, ‘no‘],
[0, 1, ‘no‘]]
labels = [‘no surfacing‘, ‘flippers‘]
return dataset, labels
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numberFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0;
bestFeature = -1;
for i in range(numberFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy =0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
classCount ={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]=1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
myDat,labels = CreateDataSet()
createTree(myDat,labels)
运行结果如下:
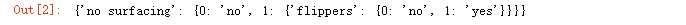
标签:ase 大小 line append 指标 cond str create images
原文地址:http://www.cnblogs.com/yjd_hycf_space/p/6940068.html