标签:har details level fence modified cat alter effect div
C# 内存模型
This is the first of a two-part series that will tell the long story of the C# memory model. The first part explains the guarantees the C# memory model makes and shows the code patterns that motivate the guarantees; the second part will detail how the guarantees are achieved on different hardware architectures in the Microsoft .NET Framework 4.5. One source of complexity in multithreaded programming is that the compiler and the hardware can subtly transform a program’s memory operations in ways that don’t affect the single-threaded behavior, but might affect the multithreaded behavior. Consider the following method:
void Init() { _data = 42; _initialized = true; }
If _data and _initialized are ordinary (that is, non-volatile) fields, the compiler and the processor are allowed to reorder the operations so that Init executes as if it were written like this:
void Init() { _initialized = true; _data = 42; }
There are various optimizations in both compilers and processors that can result in this kind of reordering, as I’ll discuss in Part 2. In a single-threaded program, the reordering of statements in Init makes no difference in the meaning of the program. As long as both _initialized and _data are updated before the method returns, the order of the assignments doesn’t matter. In a single-threaded program, there’s no second thread that could observe the state in between the updates. In a multithreaded program, however, the order of the assignments may matter because another thread might read the fields while Init is in the middle of execution. Consequently, in the reordered version of Init, another thread may observe _initialized=true and _data=0. The C# memory model is a set of rules that describes what kinds of memory-operation reordering are and are not allowed. All programs should be written against the guarantees defined in the specification.
However, even if the compiler and the processor are allowed to reorder memory operations, it doesn’t mean they always do so in practice. Many programs that contain a “bug” according to the abstract C# memory model will still execute correctly on particular hardware running a particular version of the .NET Framework. Notably, the x86 and x64 processors reorder operations only in certain narrow scenarios, and similarly the CLR just-in-time (JIT) compiler doesn’t perform many of the transformations it’s allowed to. Although the abstract C# memory model is what you should have in mind when writing new code, it can be helpful to understand the actual implementation of the memory model on different architectures, in particular when trying to understand the behavior of existing code. C# Memory Model According to ECMA-334 The authoritative definition of the C# memory model is in the Standard ECMA-334 C# Language Specification (bit.ly/MXMCrN). Let’s discuss the C# memory model as defined in the specification.
Memory Operation Reordering According to ECMA-334, when a thread reads a memory location in C# that was written to by a different thread, the reader might see a stale value. This problem is illustrated in Figure 1.
Figure 1 Code at Risk of Memory Operation Reordering public class DataInit { private int _data = 0; private bool _initialized = false; void Init() { _data = 42; // Write 1 _initialized = true; // Write 2 } void Print() { if (_initialized) // Read 1 Console.WriteLine(_data); // Read 2 else Console.WriteLine("Not initialized"); } }
Suppose Init and Print are called in parallel (that is, on different threads) on a new instance of DataInit. If you examine the code of Init and Print, it may seem that Print can only output “42” or “Not initialized.” However, Print can also output “0.” The C# memory model permits reordering of memory operations in a method, as long as the behavior of single-threaded execution doesn’t change. For example, the compiler and the processor are free to reorder the Init method operations as follows:
void Init() { _initialized = true; // Write 2 _data = 42; // Write 1 }
This reordering wouldn’t change the behavior of the Init method in a single-threaded program. In a multithreaded program, however, another thread might read _initialized and _data fields after Init has modified one field but not the other, and then the reordering could change the behavior of the program. As a result, the Print method could end up outputting a “0.” The reordering of Init isn’t the only possible source of trouble in this code sample. Even if the Init writes don’t end up reordered, the reads in the Print method could be transformed:
void Print() { int d = _data; // Read 2 if (_initialized) // Read 1 Console.WriteLine(d); else Console.WriteLine("Not initialized"); }
Just as with the reordering of writes, this transformation has no effect in a single-threaded program, but might change the behavior of a multithreaded program. And, just like the reordering of writes, the reordering of reads can also result in a 0 printed to the output. In Part 2 of this article, you’ll see how and why these transformations take place in practice when I look at different hardware architectures in detail.
Volatile Fields The C# programming language provides volatile fields that constrain how memory operations can be reordered. The ECMA specification states that volatile fields provide acquire--release semantics (bit.ly/NArSlt). A read of a volatile field has acquire semantics, which means it can’t be reordered with subsequent operations. The volatile read forms a one-way fence: preceding operations can pass it, but subsequent operations can’t. Consider this example:
class AcquireSemanticsExample { int _a; volatile int _b; int _c; void Foo() { int a = _a; // Read 1 int b = _b; // Read 2 (volatile) int c = _c; // Read 3 ... } }
Read 1 and Read 3 are non-volatile, while Read 2 is volatile. Read 2 can’t be reordered with Read 3, but it can be reordered with Read 1. Figure 2 shows the valid reorderings of the Foo body. Figure 2 Valid Reordering of Reads in AcquireSemanticsExample
|
int a = _a; // Read 1 int b = _b; // Read 2 (volatile) int c = _c; // Read 3 |
int b = _b; // Read 2 (volatile) int a = _a; // Read 1 int c = _c; // Read 3 |
int b = _b; // Read 2 (volatile) int c = _c; // Read 3 int a = _a; // Read 1 |
A write of a volatile field, on the other hand, has release semantics, and so it can’t be reordered with prior operations. A volatile write forms a one-way fence, as this example demonstrates:
class ReleaseSemanticsExample { int _a; volatile int _b; int _c; void Foo() { _a = 1; // Write 1 _b = 1; // Write 2 (volatile) _c = 1; // Write 3 ... } }
Write 1 and Write 3 are non-volatile, while Write 2 is volatile. Write 2 can’t be reordered with Write 1, but it can be reordered with Write 3. Figure 3 shows the valid reorderings of the Foo body.
Figure 3 Valid Reordering of Writes in ReleaseSemanticsExample
|
_a = 1; // Write 1 _b = 1; // Write 2 (volatile) _c = 1; // Write 3 |
_a = 1; // Write 1 _c = 1; // Write 3 _b = 1; // Write 2 (volatile) |
_c = 1; // Write 3 _a = 1; // Write 1 _b = 1; // Write 2 (volatile) |
I’ll come back to the acquire-release semantics in the “Publication via Volatile Field” section later in this article.Atomicity Another issue to be aware of is that in C#, values aren’t necessarily written atomically into memory. Consider this example:
class AtomicityExample { Guid _value; void SetValue(Guid value) { _value = value; } Guid GetValue() { return _value; } }
If one thread repeatedly calls SetValue and another thread calls GetValue, the getter thread might observe a value that was never written by the setter thread. For example, if the setter thread alternately calls SetValue with Guid values (0,0,0,0) and (5,5,5,5), GetValue could observe (0,0,0,5) or (0,0,5,5) or (5,5,0,0), even though none of those values was ever assigned using SetValue. The reason behind the “tearing” is that the assignment “_value = value” doesn’t execute atomically at the hardware level. Similarly, the read of _value also doesn’t execute atomically. The C# ECMA specification guarantees that the following types will be written atomically: reference types, bool, char, byte, sbyte, short, ushort, uint, int and float. Values of other types—including user-defined value types—could be written into memory in multiple atomic writes. As a result, a reading thread could observe a torn value consisting of pieces of different values. One caveat is that even the types that are normally read and written atomically (such as int) could be read or written non-atomically if the value is not correctly aligned in memory. Normally, C# will ensure that values are correctly aligned, but the user is able to override the alignment using the StructLayoutAttribute class (bit.ly/Tqa0MZ). Non-Reordering Optimizations Some compiler optimizations may introduce or eliminate certain memory operations. For example, the compiler might replace repeated reads of a field with a single read. Similarly, if code reads a field and stores the value in a local variable and then repeatedly reads the variable, the compiler could choose to repeatedly read the field instead.
Because the ECMA C# spec doesn’t rule out the non-reordering optimizations, they’re presumably allowed. In fact, as I’ll discuss in Part 2, the JIT compiler does perform these types of optimizations. Thread Communication Patterns The purpose of a memory model is to enable thread communication. When one thread writes values to memory and another thread reads from memory, the memory model dictates what values the reading thread might see. Locking Locking is typically the easiest way to share data among threads. If you use locks correctly, you basically don’t have to worry about any of the memory model messiness. Whenever a thread acquires a lock, the CLR ensures that the thread will see all updates made by the thread that held the lock earlier. Let’s add locking to the example from the beginning of this article, as shown in Figure 4.
Figure 4 Thread Communication with Locking public class Test { private int _a = 0; private int _b = 0; private object _lock = new object(); void Set() { lock (_lock) { _a = 1; _b = 1; } } void Print() { lock (_lock) { int b = _b; int a = _a; Console.WriteLine("{0} {1}", a, b); } } }
Adding a lock that Print and Set acquire provides a simple solution. Now, Set and Print execute atomically with respect to each other. The lock statement guarantees that the bodies of Print and Set will appear to execute in some sequential order, even if they’re called from multiple threads.The diagram in Figure 5 shows one possible sequential order that could happen if Thread 1 calls Print three times, Thread 2 calls Set once and Thread 3 calls Print once.
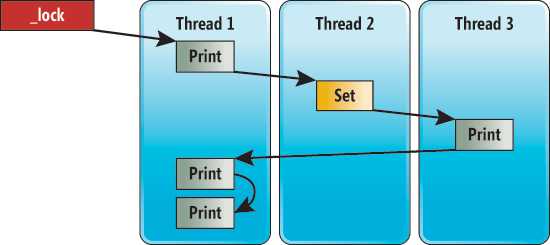
Figure 5 Sequential Execution with Locking
When a locked block of code executes, it’s guaranteed to see all writes from blocks that precede the block in the sequential order of the lock. Also, it’s guaranteed not to see any of the writes from blocks that follow it in the sequential order of the lock. In short, locks hide all of the unpredictability and complexity weirdness of the memory model: You don’t have to worry about the reordering of memory operations if you use locks correctly. However, note that the use of locking has to be correct. If only Print or Set uses the lock—or Print and Set acquire two different locks—memory operations can become reordered and the complexity of the memory model comes back. Publication via Threading API Locking is a very general and powerful mechanism for sharing state among threads. Publication via threading API is another frequently used pattern of concurrent programming. The easiest way to illustrate publication via threading API is by way of an example:
class Test2 { static int s_value; static void Run() { s_value = 42; Task t = Task.Factory.StartNew(() => { Console.WriteLine(s_value); }); t.Wait(); } }
When you examine the preceding code sample, you’d probably expect “42” to be printed to the screen. And, in fact, your intuition would be correct. This code sample is guaranteed to print “42.”
It might be surprising that this case even needs to be mentioned, but in fact there are possible implementations of StartNew that would allow “0” to be printed instead of “42,” at least in theory. After all, there are two threads communicating via a non-volatile field, so memory operations can be reordered. The pattern is displayed in the diagram in Figure 6.
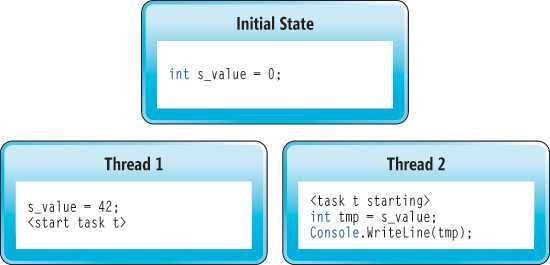
Figure 6 Two Threads Communicating via a Non-Volatile Field
The StartNew implementation must ensure that the write to s_value on Thread 1 will not move after <start task t>, and the read from s_value on Thread 2 will not move before <task t starting>. And, in fact, the StartNew API really does guarantee this. All other threading APIs in the .NET Framework, such as Thread.Start and ThreadPool.QueueUserWorkItem, also make a similar guarantee. In fact, nearly every threading API must have some barrier semantics in order to function correctly. These are almost never documented, but can usually be deduced simply by thinking about what the guarantees would have to be in order for the API to be useful. Publication via Type Initialization Another way to safely publish a value to multiple threads is to write the value to a static field in a static initializer or a static constructor. Consider this example:
class Test3 { static int s_value = 42; static object s_obj = new object(); static void PrintValue() { Console.WriteLine(s_value); Console.WriteLine(s_obj == null); } }
If Test3.PrintValue is called from multiple threads concurrently, is it guaranteed that each PrintValue call will print “42” and “false”? Or, could one of the calls also print “0” or “true”? Just as in the previous case, you do get the behavior you’d expect: Each thread is guaranteed to print “42” and “false.” The patterns discussed so far all behave as you’d expect. Now I’ll get to cases whose behavior may be surprising.
Publication via Volatile Field Many concurrent programs can be built using the three simple patterns discussed so far, used together with concurrency primitives in the .NET System.Threading and System.Collections.Concurrent namespaces. The pattern I’m about to discuss is so important that the semantics of the volatile keyword were designed around it. In fact, the best way to remember the volatile keyword semantics is to remember this pattern, instead of trying to memorize the abstract rules explained earlier in this article. Let’s start with the example code in Figure 7. The DataInit class in Figure 7 has two methods, Init and Print; both may be called from multiple threads. If no memory operations are reordered, Print can only print “Not initialized” or “42,” but there are two possible cases when Print could print a “0”:
Write 1 and Write 2 were reordered.
Read 1 and Read 2 were reordered.
Figure 7 Using the Volatile Keyword public class DataInit { private int _data = 0; private volatile bool _initialized = false; void Init() { _data = 42; // Write 1 _initialized = true; // Write 2 } void Print() { if (_initialized) { // Read 1 Console.WriteLine(_data); // Read 2 } else { Console.WriteLine("Not initialized"); } } }
If _initialized were not marked as volatile, both reorderings would be permitted. However, when _initialized is marked as volatile, neither reordering is allowed! In the case of writes, you have an ordinary write followed by a volatile write, and a volatile write can’t be reordered with a prior memory operation. In the case of the reads, you have a volatile read followed by an ordinary read, and a volatile read can’t be reordered with a subsequent memory operation. So, Print will never print “0,” even if called concurrently with Init on a new instance of DataInit. Note that if the _data field is volatile but _initialized is not, both reorderings would be permitted. As a result, remembering this example is a good way to remember the volatile semantics. Lazy Initialization One common variant of publication via volatile field is lazy initialization. The example in Figure 8 illustrates lazy initialization.
Figure 8 Lazy Initialization class BoxedInt { public int Value { get; set; } } class LazyInit { volatile BoxedInt _box; public int LazyGet() { var b = _box; // Read 1 if (b == null) { lock(this) { b = new BoxedInt(); b.Value = 42; // Write 1 _box = b; // Write 2 } } return b.Value; // Read 2 } }
In this example, LazyGet is always guaranteed to return “42.” However, if the _box field were not volatile, LazyGet would be allowed to return “0” for two reasons: the reads could get reordered, or the writes could get reordered. To further emphasize the point, consider this class:
class BoxedInt2 { public readonly int _value = 42; void PrintValue() { Console.WriteLine(_value); } }
Now, it’s possible—at least in theory—that PrintValue will print “0” due to a memory-model issue. Here’s a usage example of BoxedInt that allows it:
class Tester { BoxedInt2 _box = null; public void Set() { _box = new BoxedInt2(); } public void Print() { var b = _box; if (b != null) b.PrintValue(); } }
Because the BoxedInt instance was incorrectly published (through a non-volatile field, _box), the thread that calls Print may observe a partially constructed object! Again, making the _box field volatile would fix the issue. Interlocked Operations and Memory Barriers Interlocked operations are atomic operations that can be used at times to reduce locking in a multithreaded program. Consider this simple thread-safe counter class:
class Counter { private int _value = 0; private object _lock = new object(); public int Increment() { lock (_lock) { _value++; return _value; } } }
Using Interlocked.Increment, you can rewrite the program like this:
class Counter { private int _value = 0; public int Increment() { return Interlocked.Increment(ref _value); } }
As rewritten with Interlocked.Increment, the method should execute faster, at least on some architectures. In addition to the increment operations, the Interlocked class (bit.ly/RksCMF) exposes methods for various atomic operations: adding a value, conditionally replacing a value, replacing a value and returning the original value, and so forth. All Interlocked methods have one very interesting property: They can’t be reordered with other memory operations. So no memory operation, whether before or after an Interlocked operation, can pass an Interlocked operation. An operation that’s closely related to Interlocked methods is Thread.MemoryBarrier, which can be thought of as a dummy Interlocked operation. Just like an Interlocked method, Thread.Memory-Barrier can’t be reordered with any prior or subsequent memory operations. Unlike an Interlocked method, though, Thread.MemoryBarrier has no side effect; it simply constrains memory reorderings. Polling Loop Polling loop is a pattern that’s generally not recommended but—somewhat unfortunately—frequently used in practice. Figure 9 shows a broken polling loop.
Figure 9 Broken Polling Loop class PollingLoopExample { private bool _loop = true; public static void Main() { PollingLoopExample test1 = new PollingLoopExample(); // Set _loop to false on another thread new Thread(() => { test1._loop = false;}).Start(); // Poll the _loop field until it is set to false while (test1._loop) ; // The previous loop may never terminate } }
In this example, the main thread loops, polling a particular non-volatile field. A helper thread sets the field in the meantime, but the main thread may never see the updated value. Now, what if the _loop field was marked volatile? Would that fix the program? The general expert consensus seems to be that the compiler isn’t allowed to hoist a volatile field read out of a loop, but it’s debatable whether the ECMA C# specification makes this guarantee. On one hand, the specification states only that volatile fields obey the acquire-release semantics, which doesn’t seem sufficient to prevent hoisting of a volatile field. On the other hand, the example code in the specification does in fact poll a volatile field, implying that the volatile field read can’t be hoisted out of the loop. On x86 and x64 architectures, PollingLoopExample.Main will typically hang. The JIT compiler will read test1._loop field just once, save the value in a register, and then loop until the register value changes, which will obviously never happen. If the loop body contains some statements, however, the JIT compiler will probably need the register for some other purpose, so each iteration may end up rereading test1._loop. As a result, you may end up seeing loops in existing programs that poll a non--volatile field and yet happen to work. Concurrency Primitives Much concurrent code can benefit from high-level concurrency primitives that became available in the .NET Framework 4. Figure 10 lists some of the .NET concurrency primitives.
Figure 10 Concurrency Primitives in the .NET Framework 4
| Type | Description |
| Lazy<> | Lazily initialized values |
| LazyInitializer | |
| BlockingCollection<> | Thread-safe collections |
| ConcurrentBag<> | |
| ConcurrentDictionary<,> | |
| ConcurrentQueue<> | |
| ConcurrentStack<> | |
| AutoResetEvent | Primitives to coordinate execution of different threads |
| Barrier | |
| CountdownEvent | |
| ManualResetEventSlim | |
| Monitor | |
| SemaphoreSlim | |
| ThreadLocal<> | Container that holds a separate value for every thread |
By using these primitives, you can often avoid low-level code that depends on the memory model in intricate ways (via volatile and the like).
Coming Up So far, I’ve described the C# memory model as defined in the ECMA C# specification, and discussed the most important patterns of thread communication that define the memory model.
The second part of this article will explain how the memory model is actually implemented on different architectures, which is helpful for understanding the behavior of programs in the real world.
Best Practices
All code you write should rely only on the guarantees made by the ECMA C# specification, and not on any of the implementation details explained in this article.
Avoid unnecessary use of volatile fields. Most of the time, locks or concurrent collections (System.Collections.Concurrent.*) are more appropriate for exchanging data between threads. In some cases, volatile fields can be used to optimize concurrent code, but you should use performance measurements to validate that the benefit outweighs the extra complexity.
Instead of implementing the lazy initialization pattern yourself using a volatile field, use the System.Lazy<T> and System.Threading.LazyInitializer types.
Avoid polling loops. Often, you can use a BlockingCollection<T>, Monitor.Wait/Pulse, events or asynchronous programming instead of a polling loop.
Whenever possible, use the standard .NET concurrency primitives instead of implementing equivalent functionality yourself.
转自:C# - The C# Memory Model in Theory and Practice
https://msdn.microsoft.com/en-us/magazine/jj863136.aspx
https://msdn.microsoft.com/en-us/magazine/jj883956.aspx
标签:har details level fence modified cat alter effect div
原文地址:http://www.cnblogs.com/pugang/p/6941942.html