标签:blog http 使用 strong ar 数据 2014 log sp
在非聚集索引里,会为每条记录存储一份非聚集索引索引键的值和一份聚集索引索引键
【在没有聚集索引的表格里,是RID值指向数据页面,有聚集索引的话指向聚集索引的键(在不使用include时)】
所以在这里,每条记录都会有一份[UnitPrice]和[SalesOrderDetailID]记录,按照[UnitPrice]的顺序存放
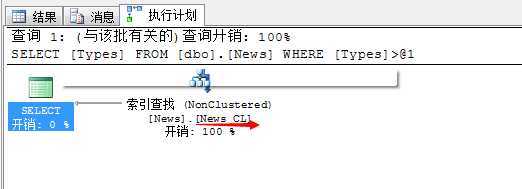
SELECT Types FROM dbo.News WHERE Types>10
计划:索引查找通过News_CL非聚集索引
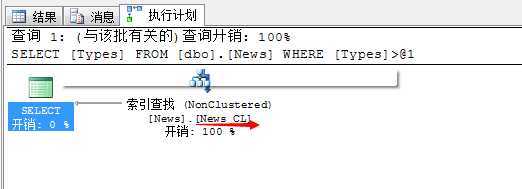
返回的字段包含没有建立索引的字段,SQLSERVER就要先在非聚集索引上找到所有[Types]大于10的记录,然后再根据[NewsID]的值找到存储在聚集索引上的详细数据。这个过程可以称为“bookmark loolup” 书签查找(书签查找很难避免)
SELECT Types,Contents FROM dbo.News WHERE Types>10
计划:聚集索引扫描通过PK_News主键

-------------------------------------再再总结------------------------------------------------------
(1)where 后面(筛选的字段):决定你建索引的时候要建的字段的范围,如果某个字段经常作为筛选字段那么可以在他上面建立索引
1 CREATE CLUSTERED INDEX SalesOrderDetail_test_CL ON [dbo].[SalesOrderDetail_test]([SalesOrderDetailID])
(2)where前面(返回的字段):决定你的表数据的查找速度,根据聚集索引来返回其他字段的值,没有聚集索引的话到数据页面里去找字段值
(3)聚集索引扫描:where后面的字段是没有建立索引【包括非聚集索引(表格上要有非聚集索引)和聚集索引】的字段
但是表格上有聚集索引 ,不管表格上有没有非聚集索引
(3)非聚集索引扫描:where后面的字段是没有建立索引(非聚集索引)的字段 ,但是表格上有非聚集索引但没有聚集索引
(4)表扫描:where后面的字段是没有建立索引的字段 并且表格上没有聚集索引和非聚集索引
(5)书签查找:where后面的字段建立了索引(不管是聚集索引还是非聚集索引),但是where前面返回的字段中有些没有建立索引
(不管是聚集索引还是非聚集索引)
为了以尽可能快的速度完成语句,光有索引是不够的。对于同一句话,SQLSERVER有很多种方法来完成他。
有些方法适合于数据量比较小的时候,有些方法适合于数据量比较大的时候。同一种方法,在数据量不同的时候,
复杂度会有非常大的差别。索引只能帮助SQLSERVER找到符合条件的记录。SQLSERVER还需要知道每一种操作
所要处理的数据量有多少,从而估算出复杂度,选取一个代价最小的执行计划。说得通俗一点,SQLSERVER要能够
知道数据是“长得什么样”的才能用最快方法完成指令
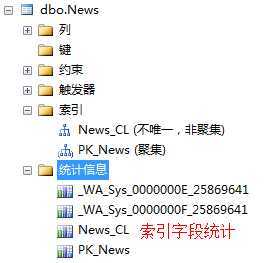
统计信息创建:
主要有3种情况
(1)在索引创建时,SQLSERVER会自动在索引所在的列上创建统计信息,所以从某种角度讲,索引的作用是双重的,
他自己能够帮助SQLSERVER快速找到数据,而他上面的统计信息,也能够告诉SQLSERVER数据的分布情况
补充一下:索引重建的时候也会更新表的统计信息,所以有时候查询变慢的时候重建一下索引查询变快了统计信息的更新也是原因之一
(2)DBA也可以通过之类的语句手动创建他认为需要的统计信息 CREATE STATISTICS
如果打开了auto create statistics自动创建统计信息,一般来讲很少需要手动创建
(3)当SQSERVERL想要使用某些列上的统计信息,发现没有的时候,“auto create statistics 自动创建统计信息”
会让SQLSERVER自动创建统计信息
例如,当语句要在某个(或者几个)字段上做过滤,或者要拿他们和另外一张表做联接(join) SQLSERVER要估算最后从这张表会返回多少记录。
这时候就需要一个统计信息的支持。如果没有,SQLSERVER会自动创建一个
在打开“auto create statistics 自动创建统计信息”的数据库上,一般不需要担心SQLSERVER没有足够的统计信息来选择执行计划。
这一点完全交给SQLSERVER管理就可以了
标签:blog http 使用 strong ar 数据 2014 log sp
原文地址:http://www.cnblogs.com/raohuagang/p/3942127.html