标签:wcc avd hdr bdtc nlp 说明 结果 single rtt
1 基本介绍
每个数据库都具有事务日志,用于记录所有事物以及每个事物对数据库所作的操作。
日志的记录形式需要根据数据库的恢复模式来确定,数据库恢复模式有三种:
- 完整模式,完全记录事物日志,需要定期进行日志备份。
- 大容量日志模式,适用于批量操作的数据库,可以以更压缩的方式处理日志,需要定期进行日志备份。
- 简单模式,也有日志文件,只是该模式下可以通过checkpoint自动重用virtual log file,所以日志文件会处于一直重复使用的过程,保持一定大小,但是,如果有一个事务启动,很久没有commit,那么从这个事务开始到最后commit的时间段内的事务日志存储空间都无法checpoint自动重用,这时,你很可能看到一个很大的日志文件;注意,简单模式下是无法进行日志备份。
数据库里边,任何对数据库的读写都是在内存页中找到对应的数据也,再做修改,如果内存页中不存在数据页,则从磁盘加载如内存中。当一个修改操作发生时,修改的将是内存页中对应的数据页面,同时也会实时记录到日后文件ldf中。那么,什么时候数据会被同步到mdf文件呢,只有以下三种情况:
- 做checkpoint时,后续会专门整理checkpoint的相应文章;
- Lazy write运行时,即内存出现压力,需要把内存中的数据页写入到磁盘,腾出内存空间;
- eager write时,即发生bulk insert和select into操作时。
DB中的事务日志记录,可以给我们带来很多好处,它可以支持以下操作:
- 恢复个别的事务。
- 在 SQL Server 启动时恢复所有未完成的事务。
- 将还原的数据库、文件、文件组或页前滚至故障点。
- 支持事务复制。
- 支持高可用性和灾难恢复解决方案:AlwaysOn 可用性组、数据库镜像和日志传送。
2 对数据库启动的影响
当数据库重启或者还原到最后的时候,数据库都会进入 recovery状态,正常情况下,这个状态持续时间在几十秒间,但是特殊情况下,它会花费非常长的时间,甚至几个小时,如果这个步骤失败,数据库则进入到挂起 suspect状态,无法正常提供使用。
那么,当数据库进入 recovery 的时候,它在操作些什么呢?
SQL SERVER日志会记录所有修改记录(数据的修改情况,不包含SQL语句),包括Begin Transaction和Commit / Rollback Transaction 操作。由于对事务日志的修改,要比数据文件的修改要快,所有会出现,数据修改更新到了日志文件,但是还没有落盘到数据文件,那么这个时候数据库就处于recovery状态,同时对事务日志最近的一个checkpoint点以后的所有数据修改记录做以下检查:

所有检查结束后,则会对数据库做一个checkpoint的表示,并写入事务日志中,表明日志文件跟数据文件已经同步结束,完成了recovery过程,数据库可正常提供使用。这里需要注意一点,如果你数据库最近一次checkpoint到现在的修改操作足够多,那么将会耗费相对较长时间来检查,同时也能够在 error log中看到百分比标识的recovery完成进展,避免漫无目的的等待。
Error Log的检查,可以通过图形界面(见下图)查看当前日志,也可以运行xp_readerrorlog 查询。
1 /*
2 xp_readerrorlog参数说明
3 1. 存档编号
4 2. 日志类型(1为SQL Server日志,2为SQL Agent日志)
5 3. 查询包含的字符串
6 4. 查询包含的字符串
7 5. LogDate开始时间
8 6. LogDate结束时间
9 7. 结果排序,按LogDate排序(可以为降序"Desc" Or 升序"Asc"),默认升序
10 */
11
12 Exec xp_readerrorlog 0,1,Null,Null,‘2017-02-16 10:53:32.300‘,‘2017-02-16 12:53:32.300‘
![技术分享]()
假设出现这种情况,由于上线的重要程度远远重要过 数据丢失的情况,并且你跟所有部门沟通确认 可以承担 data file跟log file之间的差异数据的丢失,那么你可以按以下步骤操作,严重建议不要这么操作,因为会带来不可预估的数据丢失情况,如果你命悬一线,真打算放弃这部分数据,那么,可以按照以下操作:
1 #设置数据库单用户
2 alter database backupdb set single_user with rollback immediate
3
4 #设置数据库紧急状态
5 alter database backupdb set emergency with rollback immediate
6
7 #获取事务日志的物理名和逻辑名后,重建日志文件
8 select name,physical_name from sys.master_fiels where database_id=db_id(‘backupdb‘)
9 alter database backupdb rebuild log on (name=‘事务日志的逻辑名‘,filename=‘事务日志的物理名词‘)
10
11 #设置数据库online
12 alter database backupdb set online with rollback immediate
13
14 #设置数据库为多用户
15 alter database backupdb set multi_user with rollback immediate
日志记录在 后缀名为 ldf的文件,允许有多个日志文件,但是不会并发分开记录日志,而是使用填充满一个日志文件后,再转向一个日志文件,线性操作日志文件。
可以通过下方来添加 ldf文件,需要注意几个地方:
- 初始大小,建议直接设置为 截断日志的期间内最大值,比如,某DB 恢复模式是完整模式,每隔半个小时做一次事务日志备份且截断日志,那么设置 日志文件大小的时候,取业务高峰期 每半小时的日志增长 最大值是5G,则可设置初始大小为 5G-7G之间;
- 增长大小,无论是 按比例增长还是按照MB增长,都不要设置过小,建议每次增长在100Mb左右,减少使用到自动增长,在最初设置的初始大小就满足其增长需求 ,如果开始设置的 初始大小 偏小,不满足,可以挑一个业务低峰期,修改变大初始大小。每一次文件自动增长期间,都会对写入的日志造成堵塞,虽然时间很短,但是如果增长频繁,则会影响数据库操作;
- 自动增长,建议设置为自动增长,但是前提定期监控日志的增长情况,避免磁盘空间不足,同时,如果恢复模式是 完整模式或者大容量模式,还需定期做日志备份截断日志,避免 事务日志已满的9002错误;
- 路径选择,建议与 mdf 文件放在不同的磁盘上,分散IO,若是磁盘读写瓶颈不大,则可放在一个磁盘上;
添加方式有2种,如下:
1 USE [master]
2 GO
3 ALTER DATABASE [backupdb]
4 ADD LOG FILE (
5 NAME = N‘backupdb_log_1‘,
6 FILENAME = N‘D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\backupdb_log_1.ldf‘ ,
7 SIZE = 524288KB ,
8 MAXSIZE = 1048576KB ,
9 FILEGROWTH = 10240KB
10 )
11 GO

4 物理结构
数据库的事务日志映射在一个或者多个的物理文件上,从概念上讲,日志文件是一系列的日志记录;从物理上讲,日志记录序列被有效的存储在实现事务日志的物理文件中。
SQL Server 数据库引擎在内部将每一物理日志文件分成多个虚拟日志文件,即VLF(Virtual Log File),虚拟日志文件没有固定大小,且物理日志文件所包含的虚拟日志文件数不固定。数据库引擎在创建或扩展日志文件时动态选择虚拟日志文件的大小。数据库引擎尝试维护少量的虚拟文件。在扩展日志文件后,虚拟文件的大小是现有日志大小和新文件增量大小之和。
只有当日志文件使用较小的 size 和 growth_increment 值定义时,虚拟日志文件才会影响系统性能。如果这些日志文件由于许多微小增量而增长到很大,则它们将具有很多虚拟日志文件。这会降低数据库启动以及日志备份和还原操作的速度。建议您为日志文件分配一个接近于最终所需大小的size值,并且还要分配一个相对较大的 growth_increment 值。
管理员不能配置或设置虚拟日志文件的大小或数量,但是在VLF影响系统性能的情况下,可以尝试缩小,通过收缩日志文件的方式。
dbcc loginfo(dbname) 返回的行数,即为 VLF 文件个数,当status为0时,即该文件没有被使用,还能写入LOG,2表示已被使用,并且无法重用,这个时候,可以通过 backup Log 的形式,备份并截断LOG文件,则可以回收 从最后一个0到最近一个2行的空间。
收缩日志文件或者减少VLF文件的方式如下,需要先备份日志文件,才可以有效进行收缩,在没有备份日志文件的情况下,进行收缩,效果不大。详见以下代码:
1 #其行数及为VLF个数,status为0表示文件未用,为2表示已被使用,无法重用
2 dbcc loginfo
3
4 #备份日志
5 BACKUP LOG [backupdb]
6 TO DISK = N‘D:\data\20170215_backupdb_log.trn‘ WITH NOFORMAT, NOINIT, NAME = N‘backupdb-事务日志 备份‘, SKIP, NOREWIND, NOUNLOAD, STATS = 10
7 GO
8
9 #收缩日志文件,根据日志文件名来收缩500Mb,建议收缩大小是合理大小,参考上文的 初始大小 判断
10 USE [backupdb]
11 GO
12 SELECT name FROM sys.database_files WHERE type_desc=‘log‘
13 DBCC SHRINKFILE (N‘jiankong_db_log‘ , 500)
14 GO
15
16 #其行数及为VLF个数,VLF文件减少
17 dbcc loginfo
事务日志是一种回绕的文件。假设,数据库backupdb只有一个ldf文件,且刚好分成了5个虚拟日志,当我们开始使用数据库的时候,逻辑日志从物理日志的最开始端向末端记录,如下图。

当出现checkpoint的时候,则会标注 最小恢复日志序列号 MinLSN,“MinLSN”是成功进行数据库范围内回滚所需的最早日志记录的日志序列号。如下图。

在MinLSN之前的所有虚拟日志文件VLF都可以被截断,数据库会在以下两个事件后自行截断日志:
-
简单恢复模式下,在检查点之后发生。
- 在完整恢复模式或大容量日志恢复模式下,如果自上一次备份后生成检查点,则在日志备份后进行截断(除非是仅复制日志备份)。
当截断日志的时候,这些VLF就可以被释放回收,逻辑日志的开头也会移动到最后一个被阶段VLF文件末端。
假设这个时候,在MinLSN位置后,发生了一个事务,一直没有commit,导致VLF3,VLF4,VLF5都被使用,那么就会重用之前回收的VLF文件。
正常情况下,如果经常截断旧的日志记录,保持逻辑日志的末端不到达逻辑日志的开头,满足下一个检查点之前船舰的所有新日志记录都有足够的空间存储,那么日志文件将永远不会被填满,保持一定的大小,可通过定期备份事务日志来达到。
但是如果,逻辑日志的结尾跟开头碰面了,那么当磁盘空间足够的情况下,则按照 自动增大大小 指定的数量 增大日志文件,并在 物理日志文件中添加多个VLF文件;如果磁盘空间不足,比指定的 增量大小 要少,那么就会报错,出现9002错误,导致数据库无法进行所有写操作。
5 延迟日志截断原因
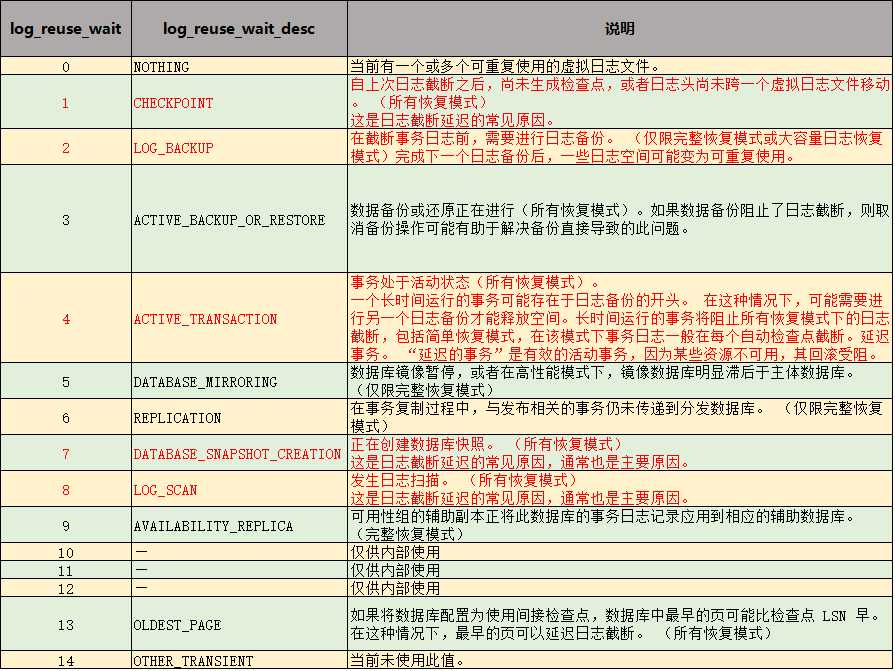
日志截断会由于多种因素发生延迟。可查询sys.databases目录视图的 log_reuse_wait 和 log_reuse_wait_desc 列来发现是什么(如果有)阻止了日志的截断。 下表对这些列的值进行了说明。
6 管理事务日志
定期监控日志文件的大小跟实际使用大小,以防日志增长异常,占满磁盘空间,可通过以下两种方式查看 日志文件使用情况.
1 #查看日志使用情况,文件大小及实际使用大小
2 dbcc sqlperf(logspace)
3
4 #查看文件相关信息
5 select name,physical_name,size*8.0/1024 size_Mb,* from sys.database_files
定期日志备份,两个备份的间隔是运行丢失数据的时间跨度,不要过于频繁备份,会对数据库IO造成一定影响。
1 BACKUP LOG [backupdb]
2 TO DISK = N‘D:\data\20170215_backupdb_log.trn‘ WITH NOFORMAT, NOINIT, NAME = N‘backupdb-事务日志 备份‘, SKIP, NOREWIND, NOUNLOAD, STATS = 10
3 GO
事务尽可能短,避免长时间开启事务,或者忘记commit/roll back;
解决事务日志已满问题(9002错误)
- 若是限制了文件最大值,在磁盘空间有剩余的情况下,增加日志文件的大小。
- 释放磁盘空间以便日志可以自动增长。
- 在其他磁盘上添加日志文件。
- 备份日志后,收缩日志。
- 将日志文件移到具有足够空间的磁盘驱动器。
参考文档:
SQL SERVER大话存储结构(5)
标签:wcc avd hdr bdtc nlp 说明 结果 single rtt
原文地址:http://www.cnblogs.com/zhaolizhe/p/6953853.html