标签:lis return 一段 urllib get www 没有 har utf-8
my噶地~~
学习了一段时间爬虫,了解最基本的模块。要开始连接数据库啦,遇到小问题,随笔mark。
爬虫就是在网页上解析数据,一开始只能爬到pycharm的显示栏,高级一点点的有图形化界面,可以爬取小说、文字、图片、小视频and so on,,
爬虫必备模块之urllib、urllib2、re、beautifulsoup、xpath等等
有些模块是python自带的模块,如urllib、sys、re等等,但是有些模块需要在Dos命令里面进行install,格式"pip install+模块名"
网页分为静态网页和动态网页,两者之间最大的区别大概就是后者需要与服务器进行数据交互,即与数据库有关联。
前两个用来解析网络url,譬如urllib2.openurl("这里放入需要爬取的url"),注意如果openurl()没有得到对应的html,那么恭喜你,你爬的网站做了反爬虫。
这个时候加上headers可以很好地解决这个问题。譬如headers={
‘User-Agent‘:‘这个地方注意去你要爬的网址上面找,F12+F5‘
}
过滤不需要的信息需要用到正则表达式,最基本的re.compile(“html”)是为了防止转义,提高编译效率。
过来不需要的信息可以用re.findall(req,html),这样可以过滤你要的信息啦,比如标题,正文,甚至图片。
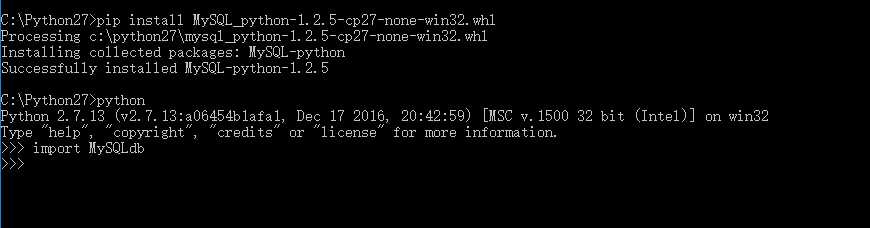
最近爬了一个小说网,需要将数据存储到数据库中,一般都是用mysql。python连接数据库需要安装数据库插件python2.x系列的数据库模块叫mysqldb,为了import MySQLdb不报错,可是让我惦记了两天,pip install mysql_python根本行不通!!!安装了好多不必要的插件依旧有问题!!!最好的解决办法如下:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#mysql-python
http://www.lfd.uci.edu/~gohlke/pythonlibs/#mysql-python
http://www.lfd.uci.edu/~gohlke/pythonlibs/#mysql-python
重要的网站备份三遍!!在里面找到名为"mysql_python-1.2.5-cp27-none-win32.whl"的插件下载,操作如下所示:
!!!专治各种纠结
关于数据库的连接存储,且看下回分解。
最后摆出一个爬取某小说网站的书籍文件,参考学习:
# _*_coding:utf-8 _*_ #爬取小说网站,将数据存入数据库 #author:yangyang #datetime:2017.6.2 import urllib2,re import MySQLdb domain="http://www.quanshu.net" headers={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36‘ } def getTypeList(pn=1): req=urllib2.Request(‘http://www.quanshu.net/map/%s.html‘ %pn) req.headers=headers #替换所有头信息 #req.add_header()#添加单个头信息 res=urllib2.urlopen(req) html=res.read().decode(‘gbk‘)#decode解码 reg=re.compile(r‘<a href="(/book/.*?)" target="_blank">(.*?)</a>‘) htmll=re.findall(reg,html) return htmll def getContent(url): req=urllib2.Request(domain+url) req.headers=headers res=urllib2.urlopen(req) html=res.read().decode(‘gbk‘) reg=r‘<li><a href="(.*?)" title=".*?">(.*?)</a></li>‘ reg=re.compile(reg) return re.findall(reg,html) def getNovelcontent(url): req=urllib2.Request(domain+url) req.headers=headers res=urllib2.urlopen(req) res=res.read().decode(‘gbk‘) reg=r‘style5\(\);</script>(.*?)<script type="text/javascript">style6\(\);‘ return re.findall(reg,res)[0] if __name__== ‘__main__‘: for type in range(1,10): for url,title in getTypeList(type): for chapter,ztitle in getContent(url): print u‘正在爬取----------%s‘ %ztitle contenturl= getNovelcontent(url.replace(‘index.html‘,chapter))
标签:lis return 一段 urllib get www 没有 har utf-8
原文地址:http://www.cnblogs.com/yang-ye/p/6956987.html