标签:pfile rank tab python3.5 简单的 bin read 日志格式 打印
目录
一. 时间模块
二. random模块
三. os和sys模块
四. shutil模块
五. pickle模块
六. shelve模块
七. xml模块(格式文件操作)
八. hashlib模块
九. subprocess模块
十. configparser模块
十一. 软件开发规范
十二. 类与对象
十三. logging模块
1 import datetime 2 import time 3 import calendar
1.获取到此时的准确时间
1 # 获取此时的时间 2 print time.localtime()
输出格式为:
1 time.struct_time(tm_year=2015, tm_mon=12, tm_mday=29, tm_hour=1, tm_min=10, tm_sec=25, tm_wday=1, tm_yday=363, tm_isdst=0)
2.获取当天的日期
1 # 获取当天的日期 2 print datetime.datetime.now() 3 print datetime.date.today()
3.获取昨天的日期
1 # 获取昨天的日期 2 def getYesterday(): 3 today = datetime.date.today() 4 oneday = datetime.timedelta(days=1) 5 yesterday = today - oneday 6 print type(today) # 查看获取到时间的类型 7 print type(yesterday) 8 return yesterday 9 yesterday = getYesterday() 10 print "昨天的时间:", yesterday
4.获取n天以前的日期
。。。这个应该就不用给出代码了吧,稍微想想就可以得出结果了。
5.字符串转换为时间和日期
1 # 字符串转换为时间
2 def strTodatetime(datestr, format):
3 return datetime.datetime.strptime(datestr, format)
4 print time.strftime("%Y-%m-%d", time.localtime())
5 print strTodatetime("2014-3-1","%Y-%m-%d")
6 print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
7 print strTodatetime("2005-2-16","%Y-%m-%d")-strTodatetime("2004-12-31","%Y-%m-%d")
输出结果:
1 2015-12-29 2 2014-03-01 00:00:00 3 2015-12-29 01:10:25 4 47 days, 0:00:00
6.获取日历相关信息
1 # 获取某个月的日历,返回字符串类型 2 cal = calendar.month(2015, 12) 3 print cal 4 calendar.setfirstweekday(calendar.SUNDAY) # 设置日历的第一天 5 cal = calendar.month(2015, 12) 6 print cal 7 8 # 获取一年的日历 9 cal = calendar.calendar(2015) 10 print cal 11 cal = calendar.HTMLCalendar(calendar.MONDAY) 12 print cal.formatmonth(2015, 12)
Python中的random模块用于随机数生成,对几个random模块中的函数进行简单介绍。如下:
1. random.random()
用于生成一个0到1的随机浮点数。如:
import random random.random()
输出:
0.3701787746508932
2. random.uniform(a,b)
用于生成一个指定范围内的随机浮点数,两个参数一个是上线,一个是下线。如:
random.uniform(10,20)
输出:
16.878776709127855
3. random.randint(a,b)
用于生成指定范围内的整数,生成上线和下线之间的随机数,如:
random.randint(10,20)
输出:
14
4. random.randrange([start], stop[, step])
从指定范围内,按指定基数递增的集合中 获取一个随机数。如:
random.randrange(10, 100, 2)
结果相当于从[10, 12, 14, 16, … 96, 98]序列中获取一个随机数。
5. random.choice(sequence)
参数sequence表示一个有序类型。这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence。如:
random.choice((“Tuple”,”List”, “Dict”))
输出:
List
6. random.shuffle(x[, random])
用于将一个列表中的元素打乱,如:
x=[“Python”,”data”,”random”,”Mining”,”good”] random.shuffle(x) print x
输出:
[‘Python’, ‘Mining’, ‘good’, ‘random’, ‘data’]
7. random.sample(sequence, k)
从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列,如:
lists=[1,2,3,4,5,6,7,8,10] a=random.sample(lists,3) print a
输出:
[4, 7, 5]
import random
def v_code(n=5): # 可以默认5位
res=‘‘
for i in range(n):
num=random.randint(0,9) # 数字
s=chr(random.randint(65,90)) # 字母 用ASCII码65-90表示
add=random.choice([num,s])
res+=str(add)
return res
print(v_code(6))
sys.arg 获取位置参数 print(sys.argv) 执行该脚本,加参数的打印结果 python3 m_sys.py 1 2 3 4 5 [‘m_sys.py‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘] 可以发现 sys.arg返回的是整个位置参数,类似于shell的$0 $1... sys.exit(n) 程序退出,n是退出是返回的对象 sys.version 获取python版本 >>> sys.version ‘3.5.1 (v3.5.1:37a07cee5969, Dec 5 2015, 21:12:44) \n[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)]‘ sys.path 返回模块的搜索路径列表,可通过添加自定义路径,来添加自定义模块 >>> sys.path [‘‘, ‘/Library/Frameworks/Python.framework/Versions/3.5/lib/python35.zip‘, ‘/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5‘, ‘/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin‘, ‘/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload‘, ‘/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages‘] sys.platform 返回当前系统平台 linux平台返回linux,windows平台返回win32,MAC返回darwin >>> sys.platform ‘darwin sys.stdout.write() 输出内容 >>> sys.stdout.write(‘asd‘) asd3 >>> sys.stdout.write(‘asd‘) asd3 >>> sys.stdout.write(‘as‘) as2
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
sys 和python解析器相关
"""
import sys
import time
def view_bar(num,total):
rate = num / total
rate_num = int(rate * 100)
#r = ‘\r %d%%‘ %(rate_num) # \r 表示跳到行手
r = ‘\r%s>%d%%‘ % (‘=‘ * rate_num, rate_num,)
sys.stdout.write(r)
sys.stdout.flush # flush 是刷新打印结果
if __name__ == ‘__main__‘:
for i in range(0, 101):
time.sleep(0.1)
view_bar(i, 100)
效果:
====================================================================================================>100%
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
1 import shutil 2 3 shutil.copyfileobj(open(‘old.xml‘,‘r‘), open(‘new.xml‘, ‘w‘))
shutil.copyfile(src, dst)
拷贝文件
1 shutil.copyfile(‘f1.log‘, ‘f2.log‘) #目标文件无需存在
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
1 shutil.copymode(‘f1.log‘, ‘f2.log‘) #目标文件必须存在
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
1 shutil.copystat(‘f1.log‘, ‘f2.log‘) #目标文件必须存在
shutil.copy(src, dst)
拷贝文件和权限
1 import shutil 2 3 shutil.copy(‘f1.log‘, ‘f2.log‘)
shutil.copy2(src, dst)
拷贝文件和状态信息
1 import shutil 2 3 shutil.copy2(‘f1.log‘, ‘f2.log‘)
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
1 import shutil 2 3 shutil.copytree(‘folder1‘, ‘folder2‘, ignore=shutil.ignore_patterns(‘*.pyc‘, ‘tmp*‘)) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
1 import shutil 2 3 shutil.rmtree(‘folder1‘)
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
1 import shutil 2 3 shutil.move(‘folder1‘, ‘folder3‘)
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
#将 /data 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("data_bak", ‘gztar‘, root_dir=‘/data‘)
#将 /data下的文件打包放置 /tmp/目录
import shutil
ret = shutil.make_archive("/tmp/data_bak", ‘gztar‘, root_dir=‘/data‘)
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
import zipfile # 压缩 z = zipfile.ZipFile(‘laxi.zip‘, ‘w‘) z.write(‘a.log‘) z.write(‘data.data‘) z.close() # 解压 z = zipfile.ZipFile(‘laxi.zip‘, ‘r‘) z.extractall(path=‘.‘) z.close() zipfile压缩解压缩
import tarfile # 压缩 >>> t=tarfile.open(‘/tmp/egon.tar‘,‘w‘) >>> t.add(‘/test1/a.py‘,arcname=‘a.bak‘) >>> t.add(‘/test1/b.py‘,arcname=‘b.bak‘) >>> t.close() # 解压 >>> t=tarfile.open(‘/tmp/egon.tar‘,‘r‘) >>> t.extractall(‘/egon‘) >>> t.close() tarfile压缩解压缩
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
1 import json 2 x="[null,true,false,1]" 3 print(eval(x)) #报错,无法解析null类型,而json就可以 4 print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,‘状态‘会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何序列化之json和pickle:
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
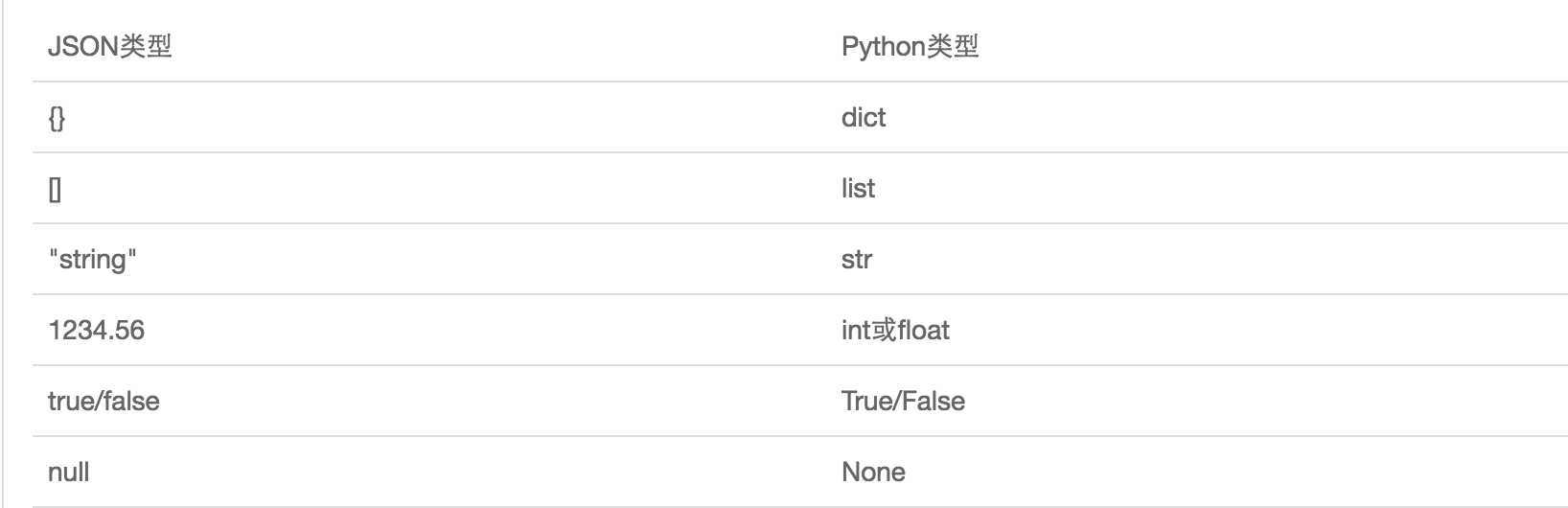
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:

import json
dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘}
print(type(dic))#<class ‘dict‘>
j=json.dumps(dic)
print(type(j))#<class ‘str‘>
f=open(‘序列化对象‘,‘w‘)
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open(‘序列化对象‘)
data=json.loads(f.read())# 等价于data=json.load(f)
pickle

import pickle
dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘}
print(type(dic))#<class ‘dict‘>
j=pickle.dumps(dic)
print(type(j))#<class ‘bytes‘>
f=open(‘序列化对象_pickle‘,‘wb‘)#注意是w是写入str,wb是写入bytes,j是‘bytes‘
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open(‘序列化对象_pickle‘,‘rb‘)
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data[‘age‘])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f=shelve.open(r‘sheve.txt‘)
# f[‘stu1_info‘]={‘name‘:‘egon‘,‘age‘:18,‘hobby‘:[‘piao‘,‘smoking‘,‘drinking‘]}
# f[‘stu2_info‘]={‘name‘:‘gangdan‘,‘age‘:53}
# f[‘school_info‘]={‘website‘:‘http://www.pypy.org‘,‘city‘:‘beijing‘}
print(f[‘stu1_info‘][‘hobby‘])
f.close()
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
# print(root.iter(‘year‘)) #全文搜索 # print(root.find(‘country‘)) #在root的子节点找,只找一个 # print(root.findall(‘country‘)) #在root的子节点找,找所有
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(‘========>‘,child.tag,child.attrib,child.attrib[‘name‘])
for i in child:
print(i.tag,i.attrib,i.text)
#只遍历year 节点
for node in root.iter(‘year‘):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter(‘year‘):
new_year=int(node.text)+1
node.text=str(new_year)
node.set(‘updated‘,‘yes‘)
node.set(‘version‘,‘1.0‘)
tree.write(‘test.xml‘)
#删除node
for country in root.findall(‘country‘):
rank = int(country.find(‘rank‘).text)
if rank > 50:
root.remove(country)
tree.write(‘output.xml‘)
#在country内添加(append)节点year2
import xml.etree.ElementTree as ET
tree = ET.parse("a.xml")
root=tree.getroot()
for country in root.findall(‘country‘):
for year in country.findall(‘year‘):
if int(year.text) > 2000:
year2=ET.Element(‘year2‘)
year2.text=‘新年‘
year2.attrib={‘update‘:‘yes‘}
country.append(year2) #往country节点下添加子节点
tree.write(‘a.xml.swap‘)
自己创建xml文档:
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = ‘33‘
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = ‘19‘
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
hash:一种算法 ,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
三个特点:
1.内容相同则hash运算结果相同,内容稍微改变则hash值则变
2.不可逆推
3.相同算法:无论校验多长的数据,得到的哈希值长度固定。
import hashlib m=hashlib.md5()# m=hashlib.sha256() m.update(‘hello‘.encode(‘utf8‘)) print(m.hexdigest()) #5d41402abc4b2a76b9719d911017c592 m.update(‘alvin‘.encode(‘utf8‘)) print(m.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af m2=hashlib.md5() m2.update(‘helloalvin‘.encode(‘utf8‘)) print(m2.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af ‘‘‘ 注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样 但是update多次为校验大文件提供了可能。 ‘‘‘
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib # ######## 256 ######## hash = hashlib.sha256(‘898oaFs09f‘.encode(‘utf8‘)) hash.update(‘alvin‘.encode(‘utf8‘)) print (hash.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7

1 import hashlib 2 passwds=[ 3 ‘alex3714‘, 4 ‘alex1313‘, 5 ‘alex94139413‘, 6 ‘alex123456‘, 7 ‘123456alex‘, 8 ‘a123lex‘, 9 ] 10 def make_passwd_dic(passwds): 11 dic={} 12 for passwd in passwds: 13 m=hashlib.md5() 14 m.update(passwd.encode(‘utf-8‘)) 15 dic[passwd]=m.hexdigest() 16 return dic 17 18 def break_code(cryptograph,passwd_dic): 19 for k,v in passwd_dic.items(): 20 if v == cryptograph: 21 print(‘密码是===>\033[46m%s\033[0m‘ %k) 22 23 cryptograph=‘aee949757a2e698417463d47acac93df‘ 24 break_code(cryptograph,make_passwd_dic(passwds)) 25 26 模拟撞库破解密码
# import subprocess
#
# res=subprocess.Popen(‘dir‘,shell=True,stdout=subprocess.PIPE)
# print(res)
# print(res.stdout.read().decode(‘gbk‘))
import subprocess
# res=subprocess.Popen(‘diasdfasdfr‘,shell=True,
# stderr=subprocess.PIPE,
# stdout=subprocess.PIPE)
# print(‘=====>‘,res.stdout.read())
# print(‘=====>‘,res.stderr.read().decode(‘gbk‘))
#ls |grep txt$
res1=subprocess.Popen(r‘dir E:\wupeiqi\s17\day06‘,shell=True,stdout=subprocess.PIPE)
# print(res1.stdout.read())
res=subprocess.Popen(r‘findstr txt*‘,shell=True,
stdin=res1.stdout,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE)
print(‘===>‘,res.stdout.read().decode(‘gbk‘))#管道取一次就空了
print(‘===>‘,res.stdout.read().decode(‘gbk‘))
print(‘===>‘,res.stdout.read().decode(‘gbk‘))
print(‘===>‘,res.stdout.read().decode(‘gbk‘))
print(‘===>‘,res.stdout.read().decode(‘gbk‘))
print(‘===>‘,res.stdout.read().decode(‘gbk‘))
print(‘===>‘,res.stdout.read().decode(‘gbk‘))
配置文件:顾名思义就是存放配置信息的文件
配置文件如下:
# 注释1 ; 注释2 [section1] k1 = v1 k2:v2 user=egon age=18 is_admin=true salary=31 [section2] k1 = v1
读取
import configparser config=configparser.ConfigParser() config.read(‘a.cfg‘) #查看所有的标题 res=config.sections() #[‘section1‘, ‘section2‘] print(res) #查看标题section1下所有key=value的key options=config.options(‘section1‘) print(options) #[‘k1‘, ‘k2‘, ‘user‘, ‘age‘, ‘is_admin‘, ‘salary‘] #查看标题section1下所有key=value的(key,value)格式 item_list=config.items(‘section1‘) print(item_list) #[(‘k1‘, ‘v1‘), (‘k2‘, ‘v2‘), (‘user‘, ‘egon‘), (‘age‘, ‘18‘), (‘is_admin‘, ‘true‘), (‘salary‘, ‘31‘)] #查看标题section1下user的值=>字符串格式 val=config.get(‘section1‘,‘user‘) print(val) #egon #查看标题section1下age的值=>整数格式 val1=config.getint(‘section1‘,‘age‘) print(val1) #18 #查看标题section1下is_admin的值=>布尔值格式 val2=config.getboolean(‘section1‘,‘is_admin‘) print(val2) #True #查看标题section1下salary的值=>浮点型格式 val3=config.getfloat(‘section1‘,‘salary‘) print(val3) #31.0
改写
import configparser config=configparser.ConfigParser() config.read(‘a.cfg‘) #删除整个标题section2 config.remove_section(‘section2‘) #删除标题section1下的某个k1和k2 config.remove_option(‘section1‘,‘k1‘) config.remove_option(‘section1‘,‘k2‘) #判断是否存在某个标题 print(config.has_section(‘section1‘)) #判断标题section1下是否有user print(config.has_option(‘section1‘,‘‘)) #添加一个标题 config.add_section(‘egon‘) #在标题egon下添加name=egon,age=18的配置 config.set(‘egon‘,‘name‘,‘egon‘) config.set(‘egon‘,‘age‘,18) #报错,必须是字符串 #最后将修改的内容写入文件,完成最终的修改 config.write(open(‘a.cfg‘,‘w‘))
1.可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
2.可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
关于如何组织一个较好的Python工程目录结构,已经有一些得到了共识的目录结构。
假设你的项目名为ATM
ATM/
|-- bin/
| |-- __init__
| |-- start.py
|
|-- core/
| |-- tests/
| | |-- __init__.py
| | |-- test.main.py
| |
| |-- __init__.py
| |-- test_main.py|
|
|-- conf/
| |-- __init__.py
| |-- setting.py
|
|---db/
| |--db.json
|
|-- docs/
|
|-- lib/
| |-- __init__.py
| |-- common.py
|
|-- log/
| |-- access.log
|
|-- __init__.py
|-- README
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行,但bin/更直观、易懂。
注意:启动文件要想调用core下的主文件,调用模块之前,必须先把根目录ATM放到环境变量里去--即sys.path(因为用户安装软件时可以自定义目录)
#!/usr/bin/python
# -*- coding:utf-8 -*-
import os,sys
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
from core import main
if __name__ == ‘__main__‘:
main.run()
core/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录, 不要置于顶层目录; (2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。
conf/:配置文件。
db/:数据库文件。
lib/:库文件,放自定义模块和包。
docs/: 存放一些文档。
log/: 日志文件。
README: 项目说明文件。
注:运行程序时,在bin目录下执行start.py代码,不可以直接执行core下的模块。
用于便捷记录日志且线程安全的模块
import logging
‘‘‘
一:如果不指定filename,则默认打印到终端
二:指定日志级别:
指定方式:
1:level=10
2:level=logging.ERROR
日志级别种类:
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
三:指定日志级别为ERROR,则只有ERROR及其以上级别的日志会被打印
‘‘‘
logging.basicConfig(filename=‘access.log‘,
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘,
datefmt=‘%Y-%m-%d %H:%M:%S %p‘,
level=10)
logging.debug(‘debug‘)
logging.info(‘info‘)
logging.warning(‘warning‘)
logging.error(‘error‘)
logging.critical(‘critical‘)
logging.log(10,‘log‘) #如果level=40,则只有logging.critical和loggin.error的日志会被打印
可在logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。点击查看更详细
日志格式
|
%(name)s |
Logger的名字,并非用户名,详细查看 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
标签:pfile rank tab python3.5 简单的 bin read 日志格式 打印
原文地址:http://www.cnblogs.com/lipingzong/p/6947451.html
