标签:效率比较 poj details session tor 解释 ima table 就会
http://blog.csdn.net/yerenyuan_pku/article/details/65462930
什么是持久化类呢?在Hibernate中持久化类的英文名称是Persistent Object(简称PO),PO=POJO+hbm映射配置文件。
对于Hibernate中的PO,有如下编写规则:
对于第1、2点,勿须多言,下面我着重解释一下后面3点。
OID指的是与数据库中表的主键对应的属性。Hibernate框架是通过OID来区分不同的PO对象,如果在内存中有两个相同的OID对象,那么Hibernate认为它们是同一个对象。大家理解起来不是很好理解,它涉及到关于Hibernate缓存的概念,因为Hibernate是对数据库直接操作,那么我们为了优化它呢,肯定提供一些缓存的策略。那么在缓存里面我们怎么知道这个对象重不重复呢?我们是通过OID来区分的。
使用基本数据类型是没有办法去描述不存在的概念的,如果使用包装类型,它就是一个对象,对于对象它的默认值是null,我们知道如果它为null,就代表不存在,那么它就可以帮助我们去描述不存在的概念。
要回答这个问题,必须要知道Hibernate中的get/load方法的区别。这也是Hibernate中常考的面试题。我先给出答案:
虽然get/load方法它们都是根据id去查询对象,但他俩的区别还是蛮大的:
1. get方法直接得到一个持久化类型对象,它就是立即查询操作,也即我要什么就查到什么。load方法它得到的是持久化类的代理类型对象(子类对象)。它采用了一种延迟策略来查询数据。这时如果PO类使用final修饰符,就会报错,因为final修饰的类不可以被继承。
2. get方法在查询时,如果不存在返回null;load方法在查询时,如果不存在,会产生异常——org.hibernate.ObjectNotFoundException。
现在就来编程释疑以上这段话,首先我们要搭好Hibernate的开发环境,读过我前面文章的童鞋,应该可以快速搭建好的,在此不做过多赘述。
在cn.itheima.test包下新建一个单元测试类——HibernateTest.java,我们首先测试Hibernate中的get()方法。
public class HibernateTest {
// 测试get/load方法的区别
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 操作
Customer customer = session.get(Customer.class, 3);
System.out.println(customer.getClass()); // cn.itheima.domain.Customer
session.getTransaction().commit();
session.close();
}
}测试test1()方法,可以发现Eclipse控制台打印:
class cn.itheima.domain.Customer
这已说明get()方法直接得到是一个持久化类型对象。
再将get方法改置为load方法,可以发现Eclipse控制台打印:
class cn.itheima.domain.Customer_$$_jvstd48_0
这似乎说明了load方法得到的是持久化类的代理类型对象(即子类对象)。
现在在这一行上加上一个断点:
Customer customer = session.get(Customer.class, 3);
然后以断点模式运行test1()方法,可发现get方法是立即查询,也即我要什么就查到什么。
再将get方法改置为load方法,以断点模式运行test1()方法,可发现只有当我们访问对象的get方法时才向数据库发送select语句。这已然说明它采用了一种延迟策略来查询数据。
数据库中的t_customer表中显然是没有id=100的客户的,而我们就是要查询这个客户,可分别试试get/load()方法。这里也是先测试Hibernate中的get()方法。
public class HibernateTest {
// 测试get/load方法的区别
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 操作
Customer customer = session.get(Customer.class, 100);
System.out.println(customer);
session.getTransaction().commit();
session.close();
}
}测试test1()方法,可以发现Eclipse控制台打印null,这就说明了get方法在查询时,如果不存在则返回null。
再将get方法改置为load方法,可发现报如下异常: 
这已然说明了load方法在查询时,如果不存在,会产生异常org.hibernate.ObjectNotFoundException。
定义hbm.xml映射文件和pojo类时都需要定义主键,Hibernate中定义的主键类型包括自然主键和代理主键:
建议:企业开发中使用代理主键!
| 主键生成器 | 描述 |
|---|---|
| increment | 代理主键。由Hibernate维护一个变量,每次生成主键时自动以递增。问题:如果有多个应用访问一个数据库,由于每个应用维护自己的主键,所以此时主键可能冲突。建议不采用。优点:可以方便跨数据库平台。缺点:不适合高并发访问。 |
| identity | 代理主键。由底层数据库生成标识符。条件是数据库支持自动增长数据类型。比如:mysql的自增主键,oracle不支持主键自动生成。如果数据库支持自增建议采用。优点:由底层数据库维护,和Hibernate无关。缺点:只能对支持自动增长的数据库有效,例如mysql。 |
| sequence | 代理主键。Hibernate根据底层数据库序列生成标识符。条件是数据库支持序列,比如oracle的序列。如果数据库支持序列建议采用。优点:由底层数据库维护,和Hibernate无关。缺点:数据库必须支持sequence方案,例如oracle。 |
| native | 代理主键。根据底层数据库自动选择identity、sequence、hilo,由于生成主键策略的控制权由Hibernate控制,所以不建议采用。优点:在项目中如果存在多个数据库时使用。缺点:效率比较低。 |
| uuid | 代理主键。Hibernate采用128位的UUID算法来生成标识符。该算法能够在网络环境中生成唯一的字符串标识符。此策略可以保证生成主键的唯一性,并且提供了最好的数据库插入性能和数据库平台的无关性。建议采用。优点:与数据库无关,方便数据库移植,效率高,不访问数据库就可以直接生成主键值,并且它能保证唯一性。缺点:uuid长度大(32位十六进制数),占用空间比较大,对应数据库中char/varchar类型。 |
| assigned | 自然主键。由java程序负责生成标识符。不建议采用。尽量在操作中避免手动对主键操作。 |
了解上面的知识之后,我来告诉大家怎么来配置。
increment
<id name="id" column="id" type="int"> <!-- java数据类型 -->
<!-- 主键生成策略 -->
<generator class="increment"></generator>
</id>identity
<id name="id" column="id" type="int"> <!-- java数据类型 -->
<!-- 主键生成策略 -->
<generator class="identity"></generator>
</id>sequence
<id name="id" column="id" type="int"> <!-- java数据类型 -->
<!-- 主键生成策略 -->
<generator class="sequence"></generator>
</id>如果这样配置,则默认使用的序列是hibernate_id。但你也可以给其指定一个序列,比如说在Oracle数据库里面手动创建了一个序列,在Oracle数据库中创建一个序列的语法:create sequence 序列名称; ,则这时就该这么配置:
<id name="id" column="id" type="int"> <!-- java数据类型 -->
<!-- 主键生成策略 -->
<generator class="sequence">
<param name="sequence">序列名称</param>
</generator>
</id>native
<id name="id" column="id" type="int"> <!-- java数据类型 -->
<!-- 主键生成策略 -->
<generator class="native"></generator>
</id>uuid
<id name="id" column="id" type="string"> <!-- java数据类型 -->
<!-- 主键生成策略 -->
<generator class="uuid"></generator>
</id>注意:主键的type应是string。
assigned
<id name="id" column="id" type="int"> <!-- java数据类型 -->
<!-- 主键生成策略 -->
<generator class="assigned"></generator>
</id>注意:尽量在操作中避免手动对主键操作。
Hibernate中持久化对象有三种状态:
接着来测试一下持久化对象的三种状态,代码如下:
public class HibernateTest {
// 测试持久化对象的三种状态
@Test
public void test2() {
// 1.得到session
Session session = HibernateUtils.openSession();
session.beginTransaction();
Customer c = new Customer(); // 瞬时态(无OID,与session无关联)
c.setName("张三");
c.setSex("男");
session.save(c); // 建立c与session的关联关系,它就是持久态的了(有OID)
// 2.事务提交,并关闭session
session.getTransaction().commit();
session.close();
System.out.println(c.getId()); // 断开了与session的关联,它就是脱管态的了(有OID)
}
}判断持久化类对象三种状态的依据:
持久化类对象三种状态之间的切换可参考下图: 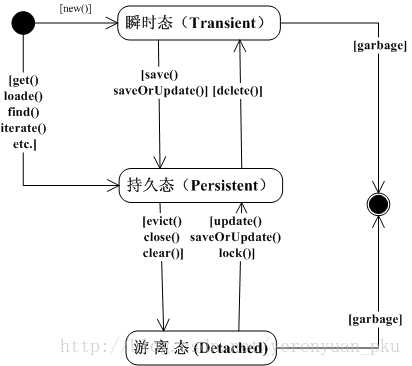
我稍微做一下解释:
瞬时态(new出来的)
瞬时→持久:save()、saveOrUpdate()方法
瞬时→脱管(游离):可手动设置oid,但不建议这么做。如下:
public class HibernateTest {
// 测试持久化对象的三种状态
@Test
public void test2() {
// 1.得到session
Session session = HibernateUtils.openSession();
session.beginTransaction();
Customer c = new Customer(); // 瞬时态(无OID,与session无关联)
c.setName("张三");
c.setSex("男");
c.setId(7); // 瞬时→脱管(游离)
System.out.println(c.getId());
}
}持久态,它是由Session管理。
持久→瞬时:delete()——这么操作以后相当于数据库里面就没有这个记录了,被删除后的持久化对象不在建议使用了。
持久→脱管:注意Session本身是有缓存的,它的缓存就是所说的一级缓存。
脱管态(我们要知道它是无法直接获取的)
脱管→瞬时:直接将oid删除(不建议这么做,因为我们不建议操作脱管态的对象)。如:
public class HibernateTest {
// 测试持久化对象的三种状态
@Test
public void test2() {
// 1.得到session
Session session = HibernateUtils.openSession();
session.beginTransaction();
Customer c = new Customer(); // 瞬时态(无OID,与session无关联)
c.setName("张三");
c.setSex("男");
c.setId(7); // 瞬时→脱管(游离)
c.setId(null); // 脱管(游离)→瞬时
System.out.println(c.getId());
}
}脱管→持久:update、saveOrUpdate、lock(过时),也是不建议这么做。
标签:效率比较 poj details session tor 解释 ima table 就会
原文地址:http://www.cnblogs.com/love540376/p/6963712.html