标签:电影 字符串 core bdc 服务 相减 order by const 搜索系统
查询与更新(Query & Update)
查询(Inquire)
以下公式中的c指代列名。
规则
1.查询语句的列名区分大小写。
2.查询语句的字符串只能使用单引号。
3.为每条语句加上分号表示一条语句结束,防止当一次执行多条语句时会抛错。
关键字:select
三种基本查询格式
直接查询

select * from stu
参数查询
将查询语句作为字符参数传递给exec执行函数
exec(‘select * from stu‘)
declare @name varchar(10) , @en varchar(3)
select @name=‘姓名‘,@en=‘英语‘
exec (‘select ‘+@name+‘,‘+@en+‘ from 成绩单‘)
命令查询
如果查询语句里使用了变量,则只能使用命令查询。
exec sp_executesql N‘select * from stu‘
form子句(来源)
所有查询
select * from Person.Address
部分查询
select AddressID,City from Person.Address //只查询该表的AddressID和City字段
列别名查询:列名 as
添加as该操作符可以为列名取一个别名,可在输出结果中查看,也可以为表定义别名。
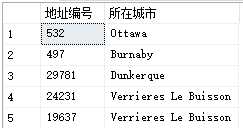
select AddressID as 地址编号,City as 所在城市 from Person.Address
数学计算查询:列名+列名……
将每行中可计算的多个列的数据相加或相减,科使用+和-号将多个列连起来查询,计算结果可as到一个新的输出列中。
create table 成绩单
(
id int identity(1,1) not null constraint pk_id primary key,
name nvarchar(20) not null ,
en int,
math int
)
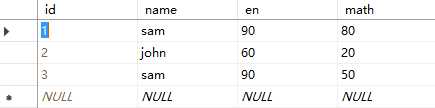
insert into 成绩单 values(‘sam‘,90,80)
insert into 成绩单 values(‘john‘,60,20)
insert into 成绩单 values(‘sam‘,90,50)
select name as 姓名, en+math as 总分 from 成绩单

前n条记录查询:select top n[percent]
select top(1) name as 姓名, en+math as 总分 from 成绩单
//先查询每个人的名字和其英语和数学的分数总和,然后从这些结果里边只取出第一条记录
select top(50) percent * from 成绩单
//查询50%的行且是最靠前的行
列数据不重复查询:select distinct 列名
select distinct en from 成绩单
//每条记录中的en列如果有相等数据只取一条结果
完全限定表名查询
select Student.c from dbName.dbo.Student
Student:表名
c:列名
dbName:数据库名
dbo:数据库拥有者(默认,除非你更改了数据库拥有者的名字,否则直接写dbo即可)
为查询创建新表:into 新表 form 旧表
将查询结果装入一个新表,新表会存在与数据库中。
select id,name,math+en as score into 总成绩单 from 成绩单
join子句(联结)
多张表可能建立联系,比如学员表和成绩表,它们通过学员ID进行联系。join子句可以查询多张建立了联系的表,以on操作符所规定的条件进行过滤。
内联查询:inner join 另一张关联的表 on 条件
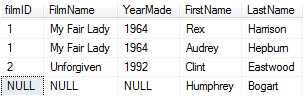
内联查询就是将多张表联起来,以on操作符给出匹配条件,满足条件的记录会被查询。以下示例演示了如何查询多表联结的数据,查询两张表中有相同的FlimID的记录。
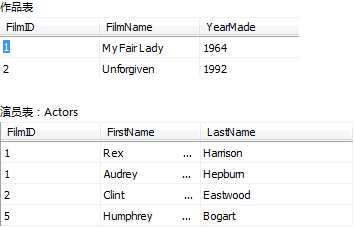
select Films.filmID,FilmName,YearMade,FirstName,LastName from Films inner join Actors
on Actors.filmID=Films.filmID
//如果表字段相同则需要指定该字段所属于的表:表名.列名,不相同的字段可以不限定表名。
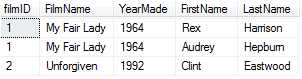
两张表能匹配的FilmID列的数据为1和2 所以输出结果为:(Actors的FilmID为5的记录在Films表中没有匹配,所以不会输出)
全联结查询:full join 另一张关联的表 on 条件
将返回两张表的所有记录,不匹配的记录以null填充。
外联查询
左外联:left outer join 另一张关联的表 on 条件
左侧的表如果与右侧的表中的某条记录不满足on的条件也会返回该条记录,左侧表中的记录会显示,右侧表的记录则以null填充。
select Films.filmID,FilmName,YearMade,FirstName,LastName from Actors left outer join Films
on Actors.filmID=Films.filmID
查询结果将会返回Actors表中的Humphrey所在行的记录,该记录不匹配FilmID,所以Film的FilmID和FilmName将会填充null。
右外联:right outer join 另一张关联的表 on 条件
左侧的表如果与右侧的表中的某条记录不满足on的条件也会返回该条记录,右侧表中的记录会显示,左侧表的记录则以null填充。
where子句(过滤)
在select返回的查询结果里使用where子句来筛选过滤出真正需要的数据。
select * from 成绩单
where en=90
where支持的操作符
= 、<>、!=、<、>、!<、!>、<=、>=、or、and、is null、not null、in(n1,n2……)、not in(n1,n2……)、like、not like、existis(子查询)[至少返回了一条记录则返回true]、x between y 介于某值到某值之间。
select * from 成绩单
where en>=60 and (id=1 or id=2)
//查询整个成绩单,在结果中筛选出英语成绩>=60并且学员编号为1或者2的记录
select * from Schedule
where year(StartDate) = ‘2013‘ and month(StartDate)=‘5‘ and day(StartDate)=‘18‘
//匹配StartDate列的日期必须是2013-05-18
通配符过滤
通配符会拖慢整个搜索系统、效率最慢、最低。
百分号通配符%
表示任意字符,可以是0或者空字符串。
like ‘%文本‘
like ‘文本%‘
like ‘%文本%‘
下划线通配符_
表示任意一个字符。
like ‘_文本‘
like ‘文本_‘
like ‘_文本_‘
方括号通配符 [ ]
匹配出现在方括号内的任意一个字符,不管方括号内有几个字符,能匹配一个就行。
select * from 学员
where 名称 like ‘[张李]%[三四]‘
//查询学员表,在结果中过滤出名称一列中以张或者李开头以三或者四结尾的记录
方括号否定通配符 [^ ]
^是不以的意思。
select * from 学员
where 名称 like ‘[^张李]%[^三四]‘
//查询学员表,在结果中过滤出名称一列中名称不以张或者李开头且不以三或者四结尾的记录
order by子句(排序)
该子句必须放在所有select子句的末尾。
升序查询:order by 列名 asc 此为默认,可不写asc
降序查询:order by 列名 desc
select name,math from 成绩单
order by en desc;
//这里并没有查询英语成绩,但还是可以按en进行排序
多列排序
列名之间逗号隔开,采取就近原则(离order by最近的列),如果当前排序出现数据相同的情况,会按后一个列的数据为准进行排序。
升降混排
select * from 成绩单
order by en desc,math
//按英语成绩降序排序,遇到英语成绩相同的列 就按数学成绩升序排序
字母排序
A<Z,无法按小写排序。
group by子句
普通分组:group by 列名
对表数据进行分组,纵向的一列中相同的数据会被归纳为一组,可以把分为一组的数据想象为一张表 里边存储了一个列 这个列有N行相同纪录的数据
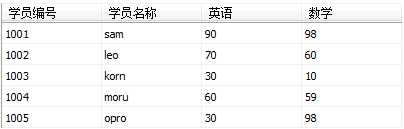
select 英语 from 成绩
group by 英语

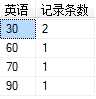
聚合函数分组
group by 可以组合聚合函数来实现分组计算,聚合函数的计算行为是基于分组后的列而非分组前。
select 英语,count(*) as 记录条数 from 成绩
group by 英语
过滤分组
having子句来为分组后数据过滤,类似where子句过滤。区别在于where过滤的是整张表的查询结果,而having只过滤已被分组的数据 。该子句使用的操作符与where一样。
//查询顾客的订单有2个以上的记录 :
select 顾客id,count(*) as 记录条数 from orders as 顾客订单
group by 顾客id
having count(*) >=2
//查询顾客订单表的所有记录,然后在结果里以顾客id进行分组,并临时生成一个新列统计记录条数,使用having过滤出顾客的订单有2个以上的记录
分组规则
1.靠select最近的依次为:where>group by > order by
2.select中如果出现表达式那么group by也必须出现该表达式。
3.select中查询的列必须是group by的列,group by的列有几个,select的列就得有几个,多一个都不行。
插入(Insert)
关键字:insert
insert into 表名(列名1,列名2,……)
values(值1,值2)
//或
insert into 表名 values(值,值……)
//后一种写法,null或有默认值的列必须填写为null、default,使列和值能对应
use mydb1
insert into 成绩(学员名称,英语,数学)
values(‘sam‘,90,100)
插入规则
1.是主键并且自动增长的列不能被insert,每inset一次,该主键列默认会自动增长。
2.如果确实需要手动插入数据到主键列,可使用set identity_insert=on,如此后续数据插入时的主键列将以你手动设置的主键列值为基础进行增加。
3.尽量使用指定列名的形式来插入数据,不指定列名的插入方式不够明确,万一表结构发生变化就会出现插入错误。
6.一次只能插入一条数据到表,不支持多个values子句
将查询结果插入另一张表
可能会遇到将来自其它数据源的数据插入到表 这些数据源可能是:另一张表、同一台服务器上完全不同的数据库的表,需保证表结构是一样的。
insert into 新表(列名)
select 列名 from 旧表
//以上将旧表的数据插入了相同结构的新表,如果数据路中没有这个新表,会自动在数据库中创建
declare @员工副本 table
(
员工ID int,
员工名称 varchar(50)
)
insert into @员工副本
select 员工ID,员工名称 from 员工
select * from @员工副本
//以上声明了一个表变量,将员工表的数据插入了表变量,这相当于一个临时的存储表,命令执行完成@员工副本即被销毁,因为它只是一个变量。
更新(Update)
关键字:update
update 表名
set 列名=值
where 条件
update 成绩
set 英语=100
where 学员编号=1001
//更新数据必须+where条件,否则整张表的所有行的数据都会被更新
//更新多个列时,用逗号将列隔开
删除(Delete)
关键字:delete
delete from 表名
where 条件
delete from 成绩
where 学员编号=1001
//删除数据必须+where条件,否则整张表的所有行的数据都会被删除
关联删除
多张表有联系时,可使用join子句联起来删除需要删除的记录。
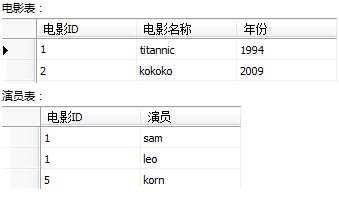
delete from 表名 from join子句 //删除在电影表中没有记录的演员 delete from 演员 from 演员 left join 电影 on 演员.电影ID=电影.电影ID where 电影.电影ID is null //删除演员表的记录,从左联表中找出没有参加过电影的演员,将其删除
Microsoft SQL - SQL SERVER学习总目录
标签:电影 字符串 core bdc 服务 相减 order by const 搜索系统
原文地址:http://www.cnblogs.com/myrocknroll/p/6963222.html
