标签:import sid print use 类型 字符 port pop 通过
所有方法都修改不了字符串的值,字符串还是原值;但可以重新赋值;使用字符串方法有返回值
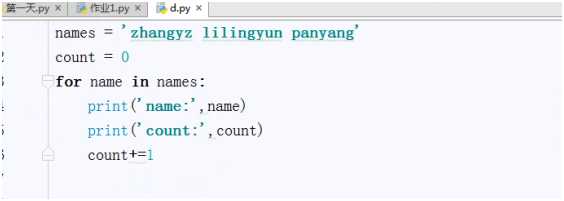
Name=“hello world”
print(name.capitalize())#首字母大写
print(name.center(50,‘-‘))#50个-,把name放中间
print(name.endswith(‘u‘))#是否以x结尾,是的话返回true
print(name.expandtabs(30))#补\t的次数
print(name.find(‘n‘))#查找字符串的索引,和index用法用法一样,找到返回索引,找不到返回-1
print(name.format(name=‘niuniu‘,age=18))#这个是格式字符串,再第一节的博客里面已经写了
print(name.format_map({‘name‘:‘niuniu‘,‘age‘:19}))#这个也是格式化字符串,后面跟的是一个字典,字典在后面也会写
print(‘abA123‘.isalnum())#是否包含数字和字母
print(‘abA‘.isalpha())#是否是英文字母
print(‘122‘.isdigit())#是否是整数
print(‘aa‘.isidentifier())#是否是一个合法的变量名
print(‘aa‘.islower())#是否是小写字母
print(‘AA‘.isupper())#是否是大写字母
print(‘Loadrunner Book‘.istitle())#是不是一个标题,判断首字母是否大写
print(‘+‘.join([‘hehe‘,‘haha‘,‘ee‘]))#拼接字符串,把可迭代对象(字符串 列表 字典等可循环对象)的元素用一个字符拼接起来
print(name.lower())#变成小写
print(name.upper())#变成大写
print(‘\nmysql \n‘.lstrip())#默认去掉左边的空格和换行
print(‘\nmysql \n‘.rstrip())#默认去掉右边的空格和换行
print(‘\nmysql \n‘.strip())#默认去掉两边边的空格和换行
“mysql”.strip(m),去掉mysql里的m
p = str.maketrans(‘abcdefg‘,‘1234567‘)#前面的字符串和后面的字符串做映射
print(‘cc ae gg‘.translate(p))#输出按照上面maketrans做映射后的字符串
new_p = str.maketrans(‘1234567‘,‘abcdefg‘)
print(‘cc ae gg‘.translate(new_p))
print(‘mysql is db.‘.replace(‘mysql‘,‘oracle‘,1))#替换字符串,1代表替换第一个,不指定第几个默认替换所有字符串
print(‘mysql is isdb‘.rfind(‘is‘))#返回最右边字符的下标
print(‘1+2+3+4‘.split(‘+‘))#切割字符串,返回一个list。1:按照指定的字符串分割字符串;2:如果split括号里什么都没有的话,按照空格分割
print(‘1+2+3\n1+2+3+4‘.splitlines())#按照换行符分割
print(‘Abcdef‘.swapcase())#大小写反转
import string
print(string.ascii_letters) #输出所有的大小写字母
print(string.ascii_lowercase) #输出所有的小写字母
print(string.ascii_uppercase) #输出所有的大写字母
print(string.digits) #输出0到9的数字
列表是可变变量
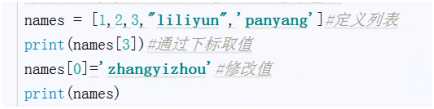

 从指定位置添加元素,0代表从第一个元素添加。
从指定位置添加元素,0代表从第一个元素添加。

del names删除变量
Names.remove(“yuansu”),remove删除的是列表里的元素,pop删除传的下标
只有pop有返回值
sort:
nums.sort() :给nums列表排序,默认升序
nums.sort(reverse=True):降序。
reverse:
nums.reverse():把列表的值反过来
count:

 取列表里最后一个值:下标是-1,代表最后一个元素,-2代表倒数第二个,以此类推
取列表里最后一个值:下标是-1,代表最后一个元素,-2代表倒数第二个,以此类推
index:


列表合并:append extend区别:
两个列表a1,a2:a1.extend(a2):把a2的元素添加到a1里,a1还是一维数组
a1.append(a2)把a2数组当成一个元素添加到a1里,a1变成二位数组
取值:下图取得是sex

从列表或字符串里取几个元素出来
eg1:列表:names=[‘as‘,‘sd‘,‘df‘]
print(names[0:3]) #取第一和第二个元素,只取0和1下标,顾头不顾尾
print(names[:]) #取所有的元素
print(names[:n])#从第一个元素开始取到第n-1个元素
print(names[n:])#从n元素取到最后一个元素
print(names[a:b:c]) #从a取到b-1元素,每隔c个取一次;不写c默认隔一个取一个;c为负数时,倒着取值,和reverse方法的功能一样,比如names[::-1],表示从倒数第一个开始取值,取到第一个值,比如names[8:1:-2]
eg2 :字符串:name2=‘dfhid,dwd‘
方法同上,同列表
元组的值不能改变,一旦创建,就不能再改变了 类型是tuple;元组的定义方式是用(),小括号;元组只有两个方法,那就是count和index,用法同list
tp=(1,2,3f,3,33re)
print(tp.count(3))
print(tp.index(3))
定义元组的时候,如果只有一个元素,要加逗号,否则会被认为是str类型。eg:a=(‘abc‘,)
字典是一种key-value的数据类型,字典的定义使用{},大括号,每个值用“,”隔开,key和value使用“:”分隔,key不能重复,通过key来取值
print(dic[‘id’])和print(dic.get(‘id’))
区别:1,中括号取值,找不到key值会报错,get取值找不到不会报错,会返回None。 2,get取值方法还可以多传一个参数,如果get不到key值,就返回参数,比如print(dic.get(‘id’,‘canshu’)),不写默认返回None
dic[‘id’]=3
dic.setdafault(‘addr’,’beijing’)
dic[‘id’]=5 #同增加方式一样
del dic[‘id’]
dic.popitem() #随机删除一个元素
dic.pop(‘id’) #字典是无序的,pop删除必须得传一个key值
dic.clear() #清空字典
Print(all.keys()) #返回所有的key
Print(all.values()) #返回所有的value
Print(all.items()) #返回所有的key和value,,返回的是dict items类型,循环的时候用,比如:for k,v in all.items()
print(k,v) #循环出所有的key和value,但因为是dict_items的类型,所以效率较低,效率高的循环是:for k in info:
print(k,info[k]) #这样也是取所有的key和value,效率较高
info.update(info2) #把两个字典合并,如果有一样的key,则取info2的value
int() #转换成整型
float() #转换成浮点型
str() #转换成字符串
list() #转换成列表
tuple() #转换成元组
eval(‘{"username":1}‘) #用它来把字符串转成字典,字符串必须符合字典的格式
标签:import sid print use 类型 字符 port pop 通过
原文地址:http://www.cnblogs.com/hesperid/p/6973907.html