标签:img tin gre like mode nal 限制 定制 ret
这篇文章构建了一个基本“Block”,并在此“Block”基础上引入了一个新的维度“cardinality”(字母“C”在图、表中表示这一维度)。深度网络的另外两个维度分别为depth(层数)、width(width指一个层的channel的数目)。
首先我们先了解一个这个“Block”是如何构建的,如下图所示(ResNeXt是这篇论文提出模型的简化表示)
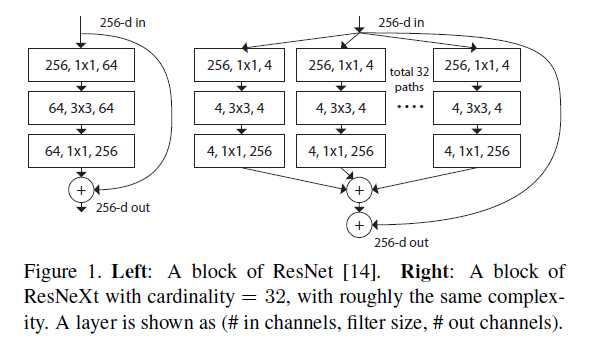
左边是标准残差网络“Block”,右图是作者引入的“Block”。这新的Block有什么优势呢?作者应该是受到了Inception models的启发,论文中指出“Unlike VGG-nets, the family of Inception models have demonstrated that carefully designed topologies are able to achieve compelling accuracy with low theoretical complexity”。再进一步就是,“The split-transform-merge behavior of Inception modules is expected to approach the representational power of large and dense layers, but at a considerably lower computational complexity”。说得简单点就是“在达到大型、紧凑深度网络的准确率的同时,降低模型的计算复杂度”(这就是这篇paper追求的一个效果)。Figure 1右边就是就是采用split-transform-merge策略构建的。
Inception models在实际应用时有一个很不方便的地方:每一个分支的卷积核大小、尺寸是“定制的”,不同的“Block”之间也是“定制的”。如果我们想要应用这一模型或者在这一框架下设计一个新的网络,那么上述“定制化”的特点会引入很多“超参数”。如果你自己设计过网络或者更改过现有网络,你就会理解“超参数”过多对于我们的设计简直就是一个“灾难”。此时,如果没有一个合适的设计策略的话,说直白点就是“靠天吃饭”了。
受VGG/ResNets成功的启发,作者总结了以下两个设计“Block”原则:
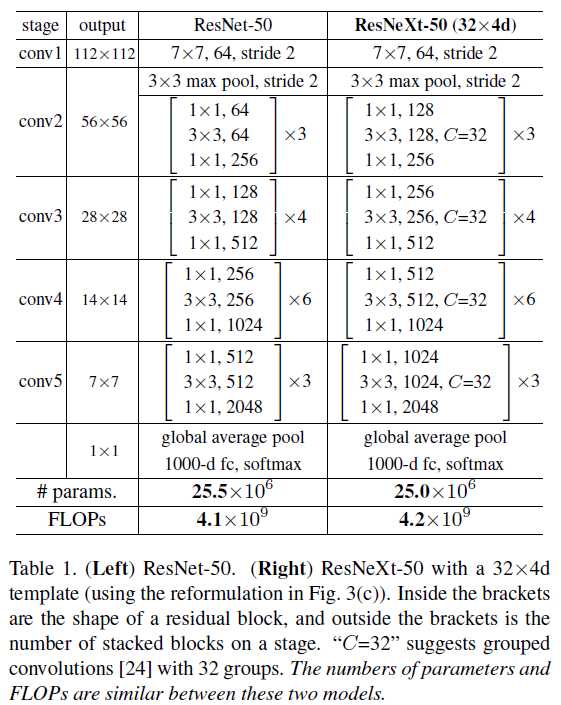
除此之外,所有的“Block”具有相同的拓扑结构。作者给出了一些设计的模板,再结合上述两条原则,我们基本可以构建所需要的任意网络了(是不是觉得网络结构的设计一下子变得简单了很多),模板如下表所示
这还没有结束,作者有给出了Figure 1左边结构的两种等价表述形式,如下图所示
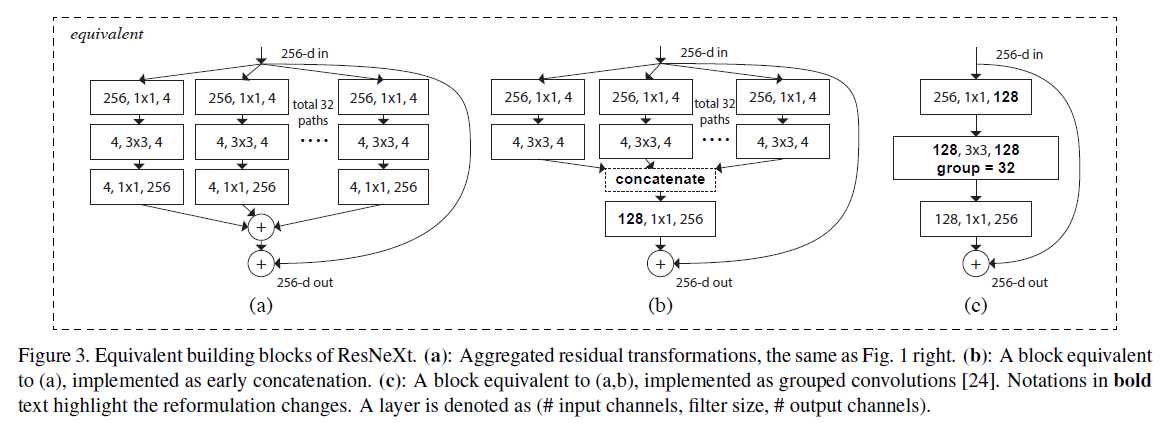
这就极大的方便了我们的实现。此时Alexnet引入的group convolution概念就有了用武之地(当时引入这一概念是受GPU条件的限制)。采用Figure 3(c)的形式,可以在Caffe中直接实现而无需更改任何源代码。
下面我们通过实验效果看看这一模型的威力
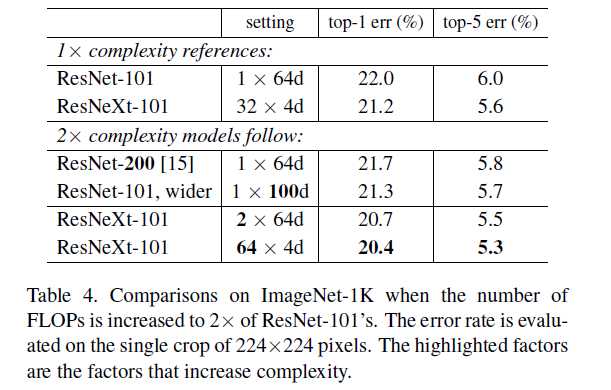
由Table 4可以得出,即使复杂度减少一半,该模型依然可以取得比ResNet-200还好的实验效果,达到了作者追求的“在达到复杂、紧凑深度模型准确率的同时,减少计算复杂度的目的”。
总结:
论文笔记 Aggregated Residual Transformations for Deep Neural Networks
标签:img tin gre like mode nal 限制 定制 ret
原文地址:http://www.cnblogs.com/everyday-haoguo/p/Note-ResNeXt.html