标签:同步机制 class rmi ui编程 标记 .so 运行 扩展模块 操作
1 import time 2 3 def consumer(name): 4 print("--->starting eating baozi...") 5 while True: 6 new_baozi = yield 7 print("[%s] is eating baozi %s" % (name, new_baozi)) 8 time.sleep(1) 9 10 def producer(): 11 r = con.__next__() 12 r = con2.__next__() 13 n = 0 14 while n < 5: 15 n += 1 16 con.send(n) 17 con2.send(n) 18 print("\033[32;1m[producer]\033[0m is making baozi %s" % n) 19 20 if __name__ == ‘__main__‘: 21 con = consumer("c1") 22 con2 = consumer("c2") 23 producer()
1 from greenlet import greenlet 2 3 def test1(): 4 print(12) 5 gr2.switch() 6 print(34) 7 gr2.switch() 8 9 def test2(): 10 print(56) 11 gr1.switch() 12 print(78) 13 14 gr1 = greenlet(test1) 15 gr2 = greenlet(test2) 16 gr1.switch()
1 import gevent 2 3 def func1(): 4 print(‘\033[31;1ma在跟b搞...\033[0m‘) 5 gevent.sleep(2) 6 print(‘\033[31;1ma又回去跟继续跟b搞...\033[0m‘) 7 8 def func2(): 9 print(‘\033[32;1ma切换到了跟c搞...\033[0m‘) 10 gevent.sleep(1) 11 print(‘\033[32;1ma搞完了d两次,回来继续跟c搞...\033[0m‘) 12 13 def func3(): 14 print(‘\033[32;1ma切换到了跟d搞...\033[0m‘) 15 gevent.sleep(0) 16 print(‘\033[32;1ma搞完了d,觉得不爽,又搞了d一次...\033[0m‘) 17 18 gevent.joinall([ 19 gevent.spawn(func1), 20 gevent.spawn(func2), 21 gevent.spawn(func3), 22 ])
输出结果:

同步与异步的性能区别
1 import gevent 2 3 def task(pid): 4 """ 5 Some non-deterministic task 6 """ 7 gevent.sleep(0.5) 8 print(‘Task %s done‘ % pid) 9 10 def synchronous(): 11 for i in range(1, 10): 12 task(i) 13 14 def asynchronous(): 15 threads = [gevent.spawn(task, i) for i in range(10)] 16 gevent.joinall(threads) 17 18 print(‘Synchronous:‘) 19 synchronous() 20 21 print(‘Asynchronous:‘) 22 asynchronous()
上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
遇到IO阻塞时会自动切换任务
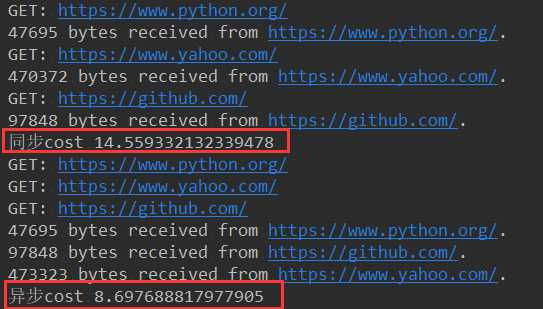
1 from urllib import request 2 import gevent 3 import time 4 from gevent import monkey 5 monkey.patch_all() # 把当前程序的所有的io操作给我单独的做上标记 6 7 def f(url): 8 print(‘GET: %s‘ % url) 9 resp = request.urlopen(url) 10 data = resp.read() 11 print(‘%d bytes received from %s.‘ % (len(data), url)) 12 13 urls = [‘https://www.python.org/‘, 14 ‘https://www.yahoo.com/‘, 15 ‘https://github.com/‘] 16 17 time_start = time.time() 18 for url in urls: 19 f(url) 20 print("同步cost", time.time() - time_start) 21 22 async_time_start = time.time() 23 gevent.joinall([ 24 gevent.spawn(f, ‘https://www.python.org/‘), 25 gevent.spawn(f, ‘https://www.yahoo.com/‘), 26 gevent.spawn(f, ‘https://github.com/‘), 27 ]) 28 print("异步cost", time.time() - async_time_start)
输出结果:
通过gevent实现单线程下的多socket并发
1 import sys 2 import socket 3 import time 4 import gevent 5 6 from gevent import socket,monkey 7 monkey.patch_all() 8 9 10 def server(port): 11 s = socket.socket() 12 s.bind((‘0.0.0.0‘, port)) 13 s.listen(500) 14 while True: 15 cli, addr = s.accept() 16 gevent.spawn(handle_request, cli) 17 18 19 20 def handle_request(conn): 21 try: 22 while True: 23 data = conn.recv(1024) 24 print("recv:", data) 25 conn.send(data) 26 if not data: 27 conn.shutdown(socket.SHUT_WR) 28 29 except Exception as ex: 30 print(ex) 31 finally: 32 conn.close() 33 if __name__ == ‘__main__‘: 34 server(8001)
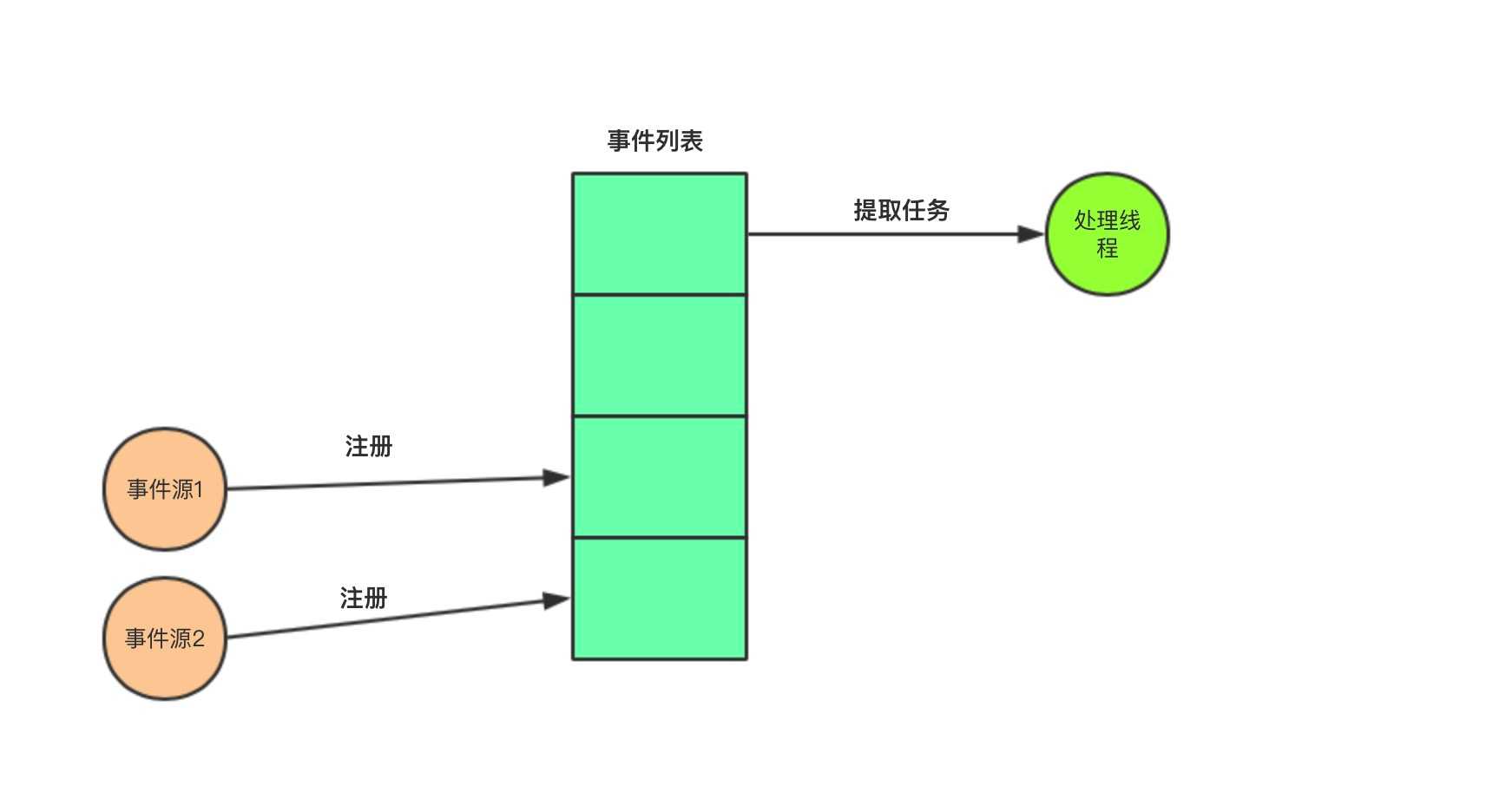
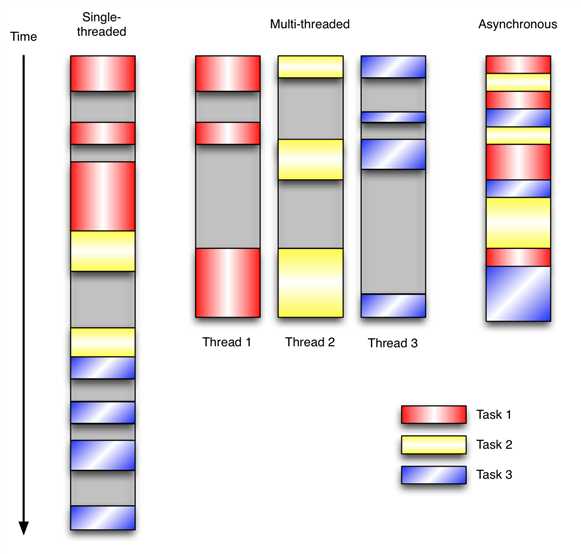
标签:同步机制 class rmi ui编程 标记 .so 运行 扩展模块 操作
原文地址:http://www.cnblogs.com/breakering/p/6979559.html