标签:输入 利用 处理 实验 logs 实际应用 分享 average 多参数
首先我们从宏观的角度理解一下这篇论文做了什么。这篇论文引入了一个“Dense Block”,该模块的的组成如下图所示(要点就是,Input输入到后续的每一层,每一层都输入到后续层)
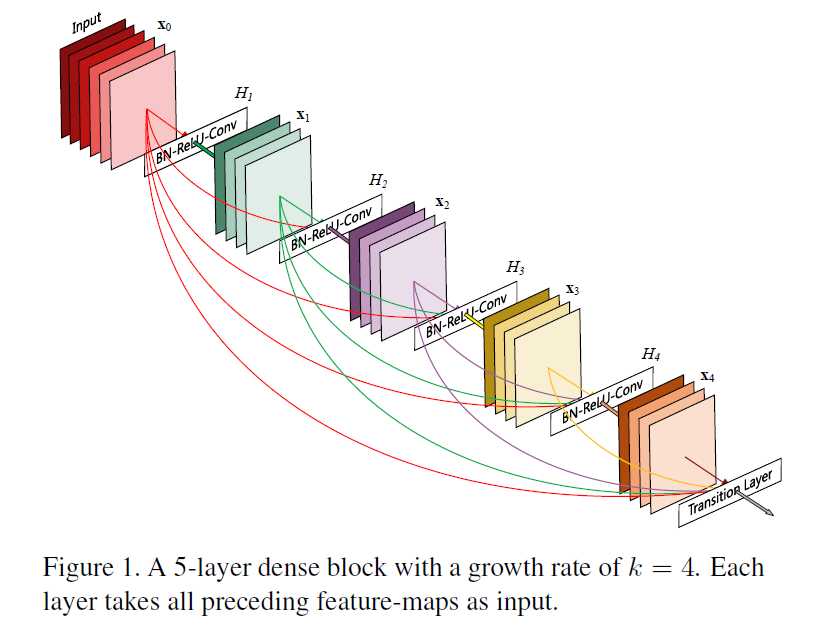
在实际应用的时候,如果我们将“Dense Block”作为一个building block,那么可以按照如下的方式构建深度网络结构(是不是一下子就理解了这篇文章做了什么?)。

下面我们来分析一下这个“Dense Block”的一些特点
为此,作者引入了一个参数k(growth rate),它表示“Dense Block”内每一层输出feature map的个数。如果“Dense Block”的层数较多、k值较大,那么“Dense Block”最后一层的输入个数是很大的,因此k取值不应该太大。
在深度网络结构的设计中,pooling layer是一个很重要的因素,作者想用pooling layer。在“Dense Block”内,第L层来自它前面所有层的输入是以“concatenate”的形式组成一个single tensor的,这样就要求它前面所有层具有相同的feature map sizes。这和pooling layer改变feature map sizes的特点相矛盾。作者做了一个折中,以pooling layer为界分割“Dense Blcok”,如Figure 2所示,这样就能够满足上述两个需求了。“Dense Block”之间的层在论文中一个专门的名字“transition layer”。
这一层的设计比较常规,“We use 1x1 convolution followed by 2x2 average pooling as transition layers between two contiguous dense blocks”.
该Block输出个数为k,但是输入个数很多,作者采取bottleneck layers的方式减少特定层输入的个数,具体就是BN-Relu-Conv(1x1)-BN-Relu-Conv(3x3),1x1的卷积核将输入的个数限制在4k个feature maps上。
由Figure 1可以看出,“transition layer”的输入个数是最多的。假如“Dense Block”一共有m个feature maps,那么我们将transition layer输出feature maps的个数限制在θm,θ属于(0,1],在实验中作者用的是0.5。
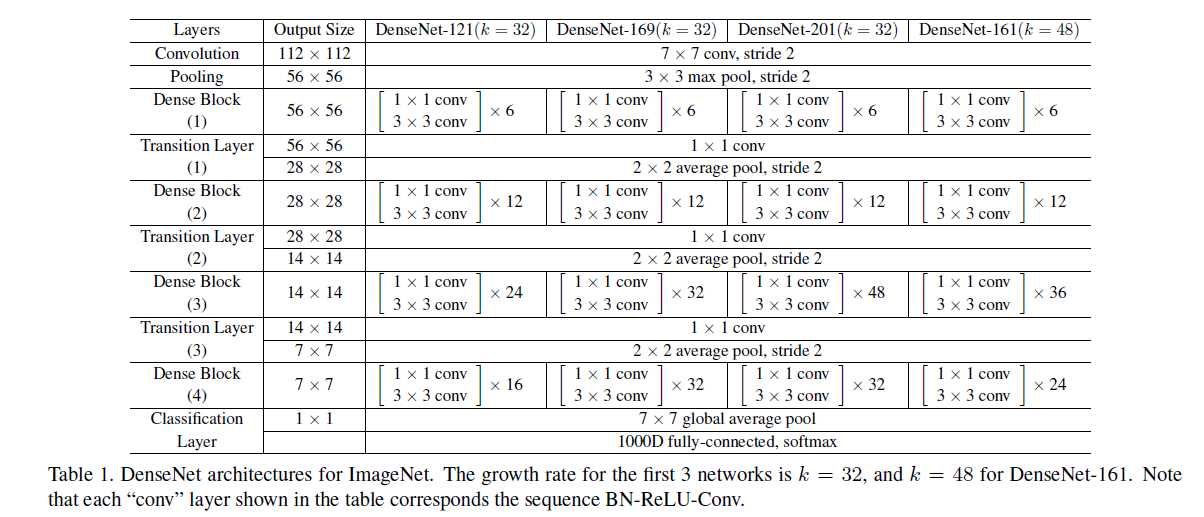
原则上,在上述解释的基础上,去搭建一个网络结构应该不难了。下面给出作者在Imagenet上的网络结构。
最后,我们来分析一下“Dense Block”的优点
这个很好理解,第L层将它前面所有层的feature maps都利用到了,没有“浪费宝贵的feature maps”。
以输入Input为例,Input通过一个或者几个“transition layer”连接到了loss函数,等效为“在Input与Loss进行了bypass”有利于Loss函数对低层的监督。仔细分析就会发现类似于上述的通路是存在很多的,它们的区别就是“有的通路距离Loss近,有的远”。这样会导致受Loss函数监督程度的差异。
就是用更少的参数达到同类模型的准确率,或者同样多参数达到更高的准确率。之所以会出现这种现象,是因为作者引入的“growth rate”这一个概念,以及对“Dense Block”结构巧妙的设计。
总结:
论文笔记 Densely Connected Convolutional Networks
标签:输入 利用 处理 实验 logs 实际应用 分享 average 多参数
原文地址:http://www.cnblogs.com/everyday-haoguo/p/Note-DenseNet.html