标签:目标 sam 避免 gray 中间 持久性 不同类 style pad
你可能听说过Apache Tez,它是一个针对Hadoop数据处理应用程序的新分布式执行框架。但是它到底是什么呢?它的工作原理是什么?哪些人应该使用它,为什么?如果你有这些疑问,那么可以看一下Bikas Saha和Arun Murthy提供的呈现“Apache Tez: 加速Hadoop查询处理”,在这个呈现中他们讨论了Tez的设计,它的一些突出亮点,同时还分享了通过让Hive使用Tez而不是MapReduce而获得的一些初始成果。
Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。
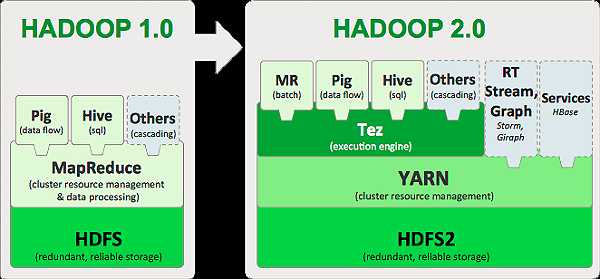 Tez项目的目标是支持高度定制化,这样它就能够满足各种用例的需要,让人们不必借助其他的外部方式就能完成自己的工作,如果 Hive和 Pig 这样的项目使用Tez而不是MapReduce作为其数据处理的骨干,那么将会显著提升它们的响应时间。Tez构建在YARN之上,后者是Hadoop所使用的新资源管理框架。
Tez项目的目标是支持高度定制化,这样它就能够满足各种用例的需要,让人们不必借助其他的外部方式就能完成自己的工作,如果 Hive和 Pig 这样的项目使用Tez而不是MapReduce作为其数据处理的骨干,那么将会显著提升它们的响应时间。Tez构建在YARN之上,后者是Hadoop所使用的新资源管理框架。
Tez产生的主要原因是绕开MapReduce所施加的限制。除了必须要编写Mapper和Reducer的限制之外,强制让所有类型的计算都满足这一范例还有效率低下的问题——例如使用HDFS存储多个MR作业之间的临时数据,这是一个负载。在Hive中,查询需要对不相关的key进行多次shuffle操作的场景非常普遍,例如join - grp by - window function - order by。
Tez设计哲学里面的关键元素包括:
Tez之所以能够实现这些目标依赖于以下内容:
你甚至可以在你的集群上放置两份类库。一份用于产品环境,它使用稳定版本供所有的生产任务使用;另一份使用最新版本,供用户体验。这两份类库相互独立,互不影响。
接下来让我们详细地探索一下这些表现力丰富的数据流API——看看我们可以使用它们做些什么?例如,你可以使用MRR模式而不是使用多个MapReduce任务,这样一个单独的map就可以有多个reduce阶段;并且这样做数据流可以在不同的处理器之间流转,不需要把任何内容写入HDFS(将会被写入磁盘,但这仅仅是为了设置检查点),与之前相比这种方式性能提升显著。下面的图表阐述了这个过程:
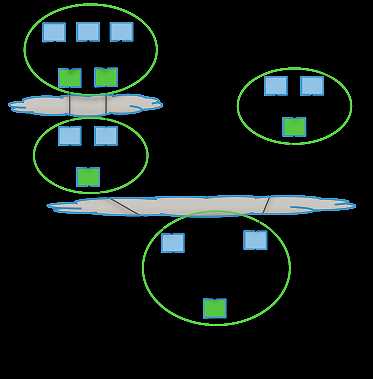
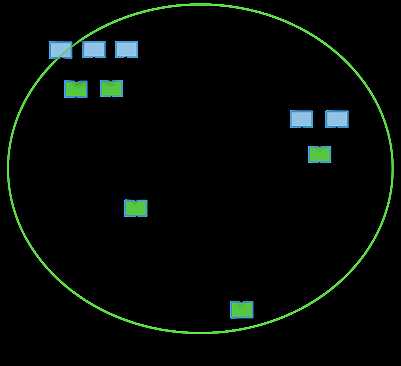
第一个图表展示的流程包含多个MR任务,每个任务都将中间结果存储到HDFS上——前一个步骤中的reducer为下一个步骤中的mapper提供数据。第二个图表展示了使用Tez时的流程,仅在一个任务中就能完成同样的处理过程,任务之间不需要访问HDFS。
Tez的灵活性意味着你需要付出比MapReduce更多的努力才能使用它,你需要学习更多的API,需要实现更多的处理逻辑。但是这还好,毕竟它和MapReduce一样并不是一个面向最终用户的应用程序,其目的是让开发人员基于它构建供最终用户使用的应用程序。
以上内容是对Tez的概述及其目标的描述,下面就让我们看看它实际的API。
Tez API包括以下几个组件:
边需要分配属性,对Tez而言这些属性是必须的,有了它们才能在运行时将逻辑图展开为能够在集群上并行执行的物理任务集合。下面是一些这样的属性:
如果你想查看一个API的使用示例,对这些属性的详细介绍,以及运行时如何展开逻辑图,那么可以看看Hortonworks提供的这篇文章。
运行时API基于输入—处理器—输出模型,借助于该模型所有的输入和输出都是可插拔的。为了方便,Tez使用了一个基于事件的模型,目的是为了让任务和系统之间、组件和组件之间能够通信。事件用于将信息(例如任务失败信息)传递给所需的组件,将输出的数据流(例如生成的数据位置信息)传送给输入,以及在运行时对DAG执行计划做出改变等。
Tez还提供了各种开箱即用的输入和输出处理器。
这些富有表现力的API能够让更高级语言(例如Hive)的编写者很优雅地将自己的查询转换成Tez任务。
在决定如何分配任务的时候,Tez调度程序考虑了很多方面,包括:任务位置需求、容器的兼容性、集群可利用资源的总量、等待任务请求的优先级、自动并行化、释放应用程序不再使用的资源(因为对它而言数据并不是本地的)等。它还维护着一个使用共享注册对象的预热JVM连接池。应用程序可以选择使用这些共享注册对象存储不同类型的预计算信息,这样之后再进行处理的时候就能重用它们而不需要重新计算了,同时这些共享的连接集合及容器池资源也能非常快地运行任务。
如果你想了解更多与容器重利用相关的信息,那么可以查看这里。
总体来看,Tez为开发人员提供了丰富的扩展性以便于让他们能够应对复杂的处理逻辑。这可以通过示例“Hive是如何使用Tez的”来说明。
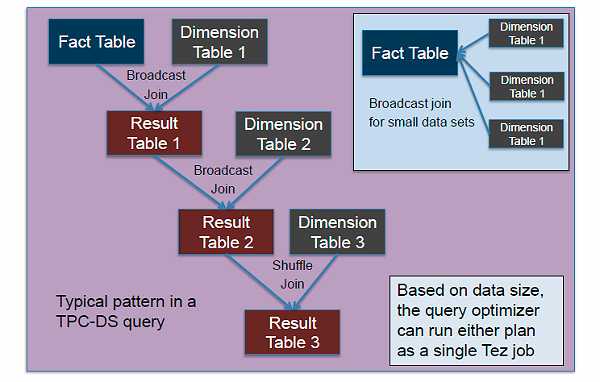
让我们看看这个经典的TPC-DS查询模式,在该模式中你需要将多个维度表与一个事实表连接到一起。大部分优化器和查询系统都能完成该图右上角部分所描述的场景:如果维度表较小,那么可以将所有的维度表与较大的事实表进行广播连接,这种情况下你可以在Tez上完成同样的事情。
但是如果这些广播包含用户自定义的、计算成本高昂的函数呢?此时,你不可能都用这种方式实现。这就需要你将自己的任务分割成不同的阶段,正如该图左边的拓扑图所展示的方法。第一个维度表与事实表进行广播连接,连接的结果再与第二个维度表进行广播连接。
第三个维度表不再进行广播连接,因为它太大了。你可以选择使用shuffle连接,Tez能够非常有效地导航拓扑。
使用Tez完成这种类型的Hive查询的好处包括:
使用新的Tez引擎执行这个特殊的Hive查询性能提升将超过100%。
Tez是一个支持DAG作业的分布式执行框架。它能够轻而易举地映射到更高级的声明式语言,例如Hive、Pig、Cascading等。它拥有一个高度可定制的执行架构,因而我们能够在运行时根据与数据和资源相关的实时信息完成动态性能优化。框架本身会自动地决定很多棘手问题,让它能够顺利地正确运行。
使用Tez,你能够得到良好的性能和开箱即用的效率。Tez的目标是解决Hadoop数据处理领域所面对的一些问题,包括延迟以及执行的复杂性等。Tez是一个开源的项目,并且已经被Hive和Pig使用。
标签:目标 sam 避免 gray 中间 持久性 不同类 style pad
原文地址:http://www.cnblogs.com/rongfengliang/p/6991020.html