标签:官方 com 过程 重构 reader script har 链表 strong
1、数据分类:
2、检索过程:Luncene检索过程可以分为两个部分,一个部分是上图左侧结构化,半结构化,非结构化数据的索引建立过程,另一部分是右侧索引查询过程。
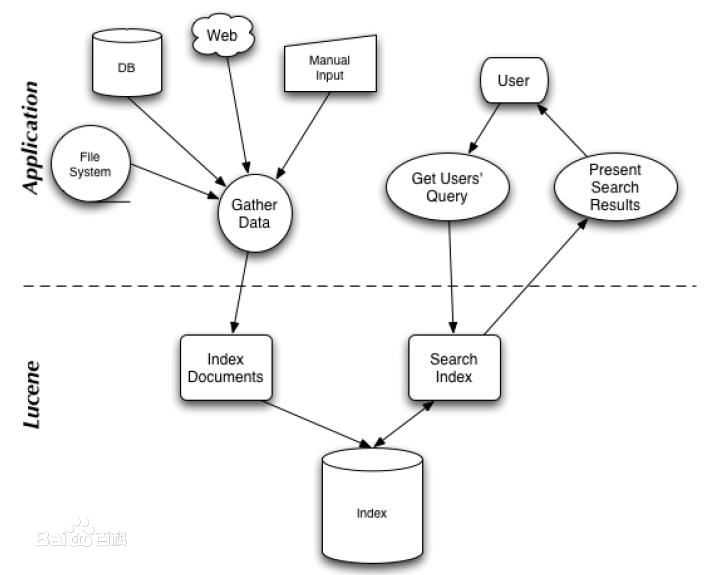
3、反向索引:
luncene检索关键词,通过索引可以将关键词定位到一篇文档,这种与哦关键词到文档的映射是文档到字符串映射的方向过程,所以称之为方向索引。
4、创建索引:
5、索引检索:
1、关键名词:
2、权重计算:
3、空间向量模型:

运行源代码中的demo实例文件和LucenecoreAPI中示例,来看看luncene是如何创建Index和检索的。
package Test; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.store.Directory; import org.apache.lucene.store.RAMDirectory; import java.io.IOException; /** * Created by rzx on 2017/6/1. */ public class CindexSearch { public static void createIndexANDSearchIndex() throws Exception{ Analyzer analyzer = new StandardAnalyzer();//标准分词器 //RAMDirectory内存字典存储索引 Directory directory = new RAMDirectory(); //Directory directory = FSDirectory.open("/tmp/testindex");磁盘存储索引 IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter writer = new IndexWriter(directory,config); Document document = new Document(); String text = "hello world main test"; document.add(new Field("filetest",text, TextField.TYPE_STORED)); //将域field添加到document中 writer.addDocument(document); writer.close(); DirectoryReader directoryReader = DirectoryReader.open(directory); IndexSearcher isearch = new IndexSearcher(directoryReader); QueryParser parser = new QueryParser("filetest",new StandardAnalyzer()); Query query = parser.parse("main");//查询main关键词 ScoreDoc [] hits = isearch.search(query,1000).scoreDocs; for (int i = 0; i <hits.length ; i++) { Document hitdoc =isearch.doc(hits[i].doc); System.out.print("命中的文件内容:"+hitdoc.get("filetest")); } directoryReader.close(); directory.close(); } public static void main(String[] args) { try { createIndexANDSearchIndex(); } catch (Exception e) { e.printStackTrace(); } } }
运行结果:

input目录中创建了两个文件test1.txt,test2.txt,内容分别是:hello world和hello main man test。运行IndexFiles读取input目录,并自动创建一个testindex索引目录,结果如下:

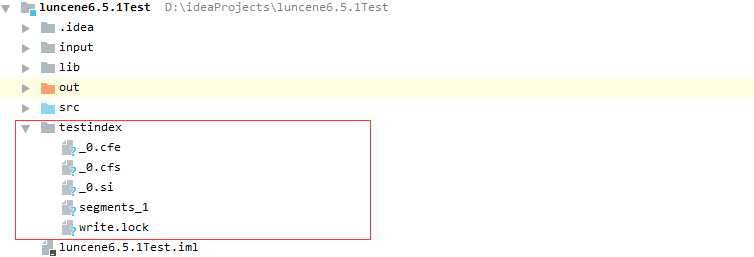
目录中创建了testindex文件,里面存储索引相关信息。运行SearchFiles如下:分别在控制台输入检索关键字:hello,min

建立索引:Analyzer,Director(RAMDirectory,FSDirectory),IndexWriterConfig,IndexWriter,Document
* Analyzer analyzer = new StandardAnalyzer(); //实例化分词器 * Directory directory = new RAMDirectory(); //初始化内存索引目录 * Directory directory = FSDirectory.open("indexpath");//初始化磁盘存储索引 * IndexWriterConfig config = new IndexWriterConfig(analyzer); //索引器配置 * IndexWriter writer = new IndexWriter(directory,config); //索引器 * Document document = new Document(); //初始化Document,用来存数据。
* DirectoryReader directoryReader = DirectoryReader.open(directory); //索引目录读取器 * IndexSearcher isearch = new IndexSearcher(directoryReader); //索引查询器 *多种检索方式: * QueryParser单字段<域>绑定: QueryParser qparser = new QueryParser("filed",new StandardAnalyzer()); //查询解析器:参数Field域,分词器 Query query = qparser.parse("main") //查询关键词 * MultiFieldQueryParser多字段<域>绑定(): QueryParser qparser2 = new MultiFieldQueryParser(new String[]{"field1","field2"},new StandardAnalyzer());//多字段查询解析器 Query query = qparser2.parse("main") //查询关键词 * Term绑定字段<域>查询:new Term(field,keyword); Term term =new Term("content","main"); Query query = new TermQuery(term); *更多方法:参照http://blog.csdn.net/chenghui0317/article/details/10824789 * ScoreDoc [] hits = isearch.search(query,1000).scoreDocs; //查询你命中的文档以及评分和所在分片
SimpleHTMLFormatter formatter=new SimpleHTMLFormatter("<b><font color=‘red‘>","</font></b>"); Highlighter highlighter=new Highlighter(formatter, new QueryScorer(query)); highlighter.setTextFragmenter(new SimpleFragmenter(400)); String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents","hello main man test");
QueryParser qparser = new QueryParser("content",new SimpleAnalyzer()); QueryParser qparser = new QueryParser("content",new ClassicAnalyzer()); QueryParser qparser = new QueryParser("content",new KeywordAnalyzer()); QueryParser qparser = new QueryParser("content",new StopAnalyzer()); QueryParser qparser = new QueryParser("content",new UAX29URLEmailAnalyzer()); QueryParser qparser = new QueryParser("content",new UnicodeWhitespaceAnalyzer()); QueryParser qparser = new QueryParser("content",new WhitespaceAnalyzer()); QueryParser qparser = new QueryParser("content",new ArabicAnalyzer()); QueryParser qparser = new QueryParser("content",new ArmenianAnalyzer()); QueryParser qparser = new QueryParser("content",new BasqueAnalyzer()); QueryParser qparser = new QueryParser("content",new BrazilianAnalyzer()); QueryParser qparser = new QueryParser("content",new BulgarianAnalyzer()); QueryParser qparser = new QueryParser("content",new CatalanAnalyzer()); QueryParser qparser = new QueryParser("content",new CJKAnalyzer()); QueryParser qparser = new QueryParser("content",new CollationKeyAnalyzer()); QueryParser qparser = new QueryParser("content",new CustomAnalyzer(Version defaultMatchVersion, CharFilterFactory[] charFilters, TokenizerFactory tokenizer, TokenFilterFactory[] tokenFilters, Integer posIncGap, Integer offsetGap)); QueryParser qparser = new QueryParser("content",new SmartChineseAnalyzer());//中文最长分词
public static void searchByIndex(String indexFilePath,String keyword) throws ParseException, InvalidTokenOffsetsException { try { String indexDataPath="testindex"; String keyWord = "main"; Directory dir= FSDirectory.open(new File(indexDataPath).toPath()); IndexReader reader= DirectoryReader.open(dir); IndexSearcher searcher=new IndexSearcher(reader); QueryParser queryParser = new QueryParser("contents",new StandardAnalyzer()); Query query = queryParser.parse("main"); TopDocs topdocs=searcher.search(query,10); ScoreDoc[] scoredocs=topdocs.scoreDocs; System.out.println("最大的评分:"+topdocs.getMaxScore()); for(int i=0;i<scoredocs.length;i++){ int doc=scoredocs[i].doc; Document document=searcher.doc(doc); System.out.println("====================================="); System.out.println("关键词:"+keyWord); System.out.println("文件路径:"+document.get("path")); System.out.println("文件ID:"+scoredocs[i].doc); //开始高亮 SimpleHTMLFormatter formatter=new SimpleHTMLFormatter("<b><font color=‘red‘>","</font></b>"); Highlighter highlighter=new Highlighter(formatter, new QueryScorer(query)); highlighter.setTextFragmenter(new SimpleFragmenter(400)); String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents","hello main man test"); //String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents",document.get("content")); System.out.println("文件内容:"+conten); System.out.println("相关度:"+scoredocs[i].score); } reader.close(); } catch (IOException e) { e.printStackTrace(); } }
输出结果:

源代码:https://codeload.github.com/NextNight/luncene6.5.1Test/zip/master
标签:官方 com 过程 重构 reader script har 链表 strong
原文地址:http://www.cnblogs.com/NextNight/p/6928352.html