标签:style blog http os 使用 io strong ar for
作者网站,内含数据库知识。
数据库设计是指对一个给定的应用环境,构造最优的数据库模式,建立数据库及其他应用系统,使之能有效地存储数据,满足各种用户的需求。数据库设计过程中命名规范很是重要,命名规范合理的设计能够省去开发人员很多时间去区别数据库实体。
最近也因为工作需要所以整理出了这个word文档,望大家指正。
数据库规划→需求分析→数据库设计→应用程序设计→实现→测试→运行于维护
定义数据库应用系统的主要目标,定义系统特定任务,包括工作量的估计、使用资源、和需求经费,定义系统的范围以及边界。
涉及人员:用户和分析人员
任务:对现实世界要处理的对象进行详细的调查,收集基础数据及处理方法,在用户调查的基础上通过分析,逐步明确用户对系统的需求,包括信息的要求及处理的要求。
方法与步骤:1.通过与用户的调查,对用户的信息需求进行收集。
2.在收集数据的同时,设计人员要对其进行加工和整理,以数据字典和数据流图的形式描述出来,并以设计人员的角度向用户讲述信息,根据用户的反馈加以修改并确定(该过程是反复的过程)
成果:数据流图,数据字典,各种说明性表格,统计输出表以及系统功能结构图。
外部实体:存在于软件系统之外的人员或组织(正方形或立方体表示)。
加工:数据处理,表示输入数据在此进行变换,产生输出数据(圆角巨型或圆形表示)。
数据流:表示流动着的数据(箭头线表示)。
数据存储:用来表示要存储的数据(开门矩形或两条平行横线表示)。
订单处理系统顶层流程图:
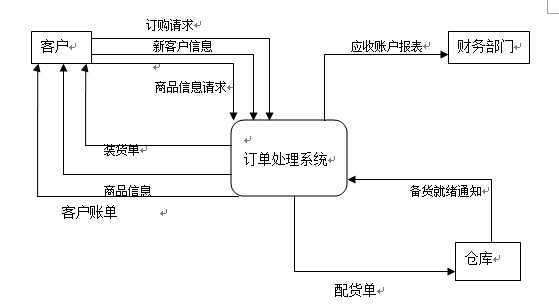
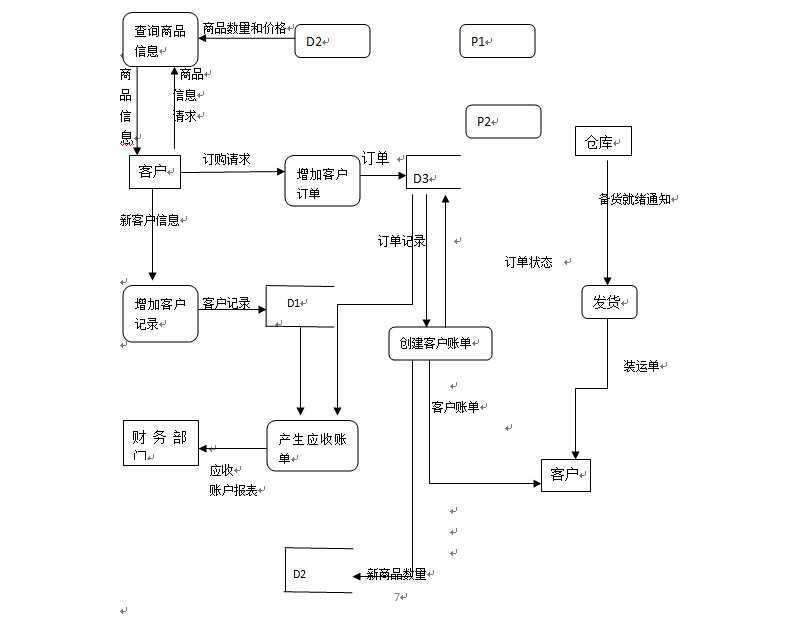
0层数据流图:
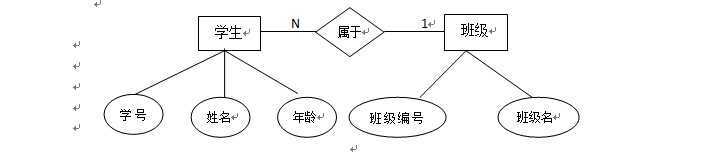
实体:现实中的事物例如,学生,老师
联系:两个实体之间的关系,1:1、1:N、M:N三种关系
属性:实体所具有的属性,例如 学生的学号、姓名、性别等
例如:一个学生属于一个班级,一个班级拥有多名学生,E-R图如下
网上购物系统E-R图,该系统数据之间存在下列约束
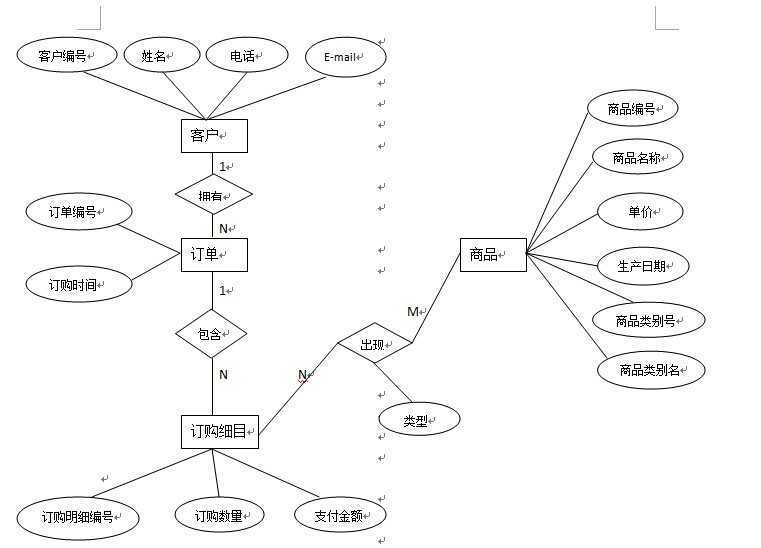
图2.2
将每个实体转换成一个关系模式,实体的属性即关系模式的属性,实体的标识即关系模式的键。
根据E-R图实体之间的联系可以转换成以下关系模式:
客户(客户编号,姓名,电话,E-mail)。关系的主键:客户编号;外键:无
订单(订单编号,订购时间,客户编号)。关系的主键:订单编号;外键:客户编号
订购细目(订购明细编号,订购数量,支付金额,订单编号)。关系主键:订购明细编号;外键:订单编号。
出现(订购明细编号,商品编号,类型)。关系的主键:订购明细编号,商品编号;外键:订购明细编号,商品编号。
商品:(商品编号,商品名称,单价,生产日期,商品类别号,商品类别名)。关系的主键:商品编号;外键:无
在关系模式设计中可能会出现以下几个问题:数据冗余、数据修改不一致、数据插入异常、数据删除异常,所以提出范式的要求,目的就是最低限度地冗余,避免插入、删除、修改异常。
主属性:包含键的所有属性。
第一范式(1NF):若关系模式R的每一个分量是不可分的数据项,则关系模式属于第一范式。即每个属性都是不可拆分的.
第二范式(2NF):R属于1NF,且每一个非主属性完全依赖于键(没有部分依赖),则R属于2NF
例如:选课关系(学号,课程号,成绩,学分)
该关系的主键是(学号,课程号),但是课程号→学分,所以学分属性部分依赖于主键,即关系部满足第二范式,可以拆分为(学号,课程号,成绩),(课程号,学分)两个关系
第三范式(3NF):R属于2NF,且每个非主属性即不部分依赖于码,也不传递依赖于码
例如:学生关系(学号,姓名,所属系,系地址)
该关系的主键是:学号
学号→所属系,所属系→学号,所属系→系地址;根据函数的依赖公理,系地址传递函数依赖于学号,即关系不满足第三范式,可以拆分关系为(学号,姓名,所属系),(所属系,系地址)
如果不拆分会存在数据修改异常,比如该学生的换了系,修改了所属系,但是系地址没有修改,这样就造成了修改异常
BCNF:R属于3NF,且不存在主属性对码的部分和传递函数依赖
例如:关系R(零件号,零件名,厂商名),如果设定每种零件号只有一个零件名,但不同的的零件号可以有相同的零件名,每种零件可以有多个厂商生产,但每家厂商生产的零件应有不同的零件名。这样可以得到:
零件号→零件名,(厂商名,零件名)→零件号
所以主属性包括(零件号,厂商名,零件名),但是“零件名”传递依赖于码“厂商名,零件名”,所以关系R不满足BCNF,当一个零件由多个生产厂商生产时,由于零件号只有一个而零件名根据厂商不同而又多个,零件名与零件号之间的联系将多次重复,带来数据冗余和操作异常现象
可以将关系分解为(零件号,厂商名),(零件号,零件名)
4NF:关系模式R属于1NF,若对于R的每个非平凡多值依赖X→→Y且Y不包含于X时,X必含码,则R属于4NF
5NF:对关系进行投影,消除关系中不是由候选码所蕴含的连接依赖
对于上面的商品关系,由于关系的主键是商品编号,而商品类别号→商品类别名
所以商品关系部满足第三范式,非主属性商品类别名传递依赖于商品编号,会存在数据冗余,数据修改异常问题。将商品关系分解为:
商品(商品编号,商品名称,单价,生产日期,商品类别号)
商品类别(商品类别号,商品类别名)
为一个给定的逻辑数据模型设计一个最合适应用要求的物理结构的过程
采用高级语言以结构化设计方法或面向对象方法进行设计
1.如果频繁地访问涉及的是对两个相关的表进行连接操作,则考虑将其合并
2.如果频繁地访问只是在表中的某一部分字段上进行,则考虑分解表,将该部分单独作为一个表
3.对于很少更新的表,引入物化视图
4. 当系统中有一些少量的,重复出现的值时,使用字典表来节约存储空间和优化查询。如地区、系统中用户类型的代号等。这类值不会在程序的运行期变化,但是需要存储在数据库中。
就地区而言,如果我们要查询某个地区的记录,则数据库需要通过字符串匹配的方式来查询;如果将地区改为一个地区的代号保存在表中,查询时通过地区的代号来查询,则查询的效率将大大提高。
程序中宜大量的使用字典表来表示这类值。字典表中保存这类值的代号和实体的集合,以外键的方式关联到使用这类值的表中。然而,在编码阶段,程序员并不使用字典表,因为首先查询字典表中实体的代号,违背了提高查询效率的初衷。程序员在数据字典的帮助下,直接使用代号来代表实体,从而提高效率。
虽然字典表在实际上并不使用,但是仍应该保留在数据库中(起码是在开发期内保留)。字典表作为另一种形式上的“数据字典文档”出现,以说明数据库中哪些表的哪些字段是使用了字典表的。
为了提高数据库的数据完整性,在开发阶段可以保留完整的字典表和普通表的外键约束。但是在数据库的运行阶段,应该将普通表和字典表的外键删除,以提高运行效率,特别是某些表使用了很多字典表的情况。
案例:某数据库中有百万条用户信息,应用系统中常常需要按照地区要查询用户的信息。用户信息表以前是按照具体的地区名称来保存的,现在将具体的名称改为字典表中的地区代号,查询效率大大提高。
|
对象 |
前缀 |
|
数据库 |
无 |
|
表 |
无 |
|
视图 |
VI |
|
索引 |
IX |
|
存储过程 |
SP |
|
函数 |
FN |
|
触发器 |
TR |
|
自定义数据类型 |
ud |
|
Default |
DF |
|
主键 |
pk |
|
外键 |
FK |
|
rule |
ru |
|
序列 |
Sq |
|
UNIQUE |
uq |
数据库对象采用26个英文字母(区分大小写)和0-9这十个自然数,加上下划线_组成,共63个字符。不能出现其他字符(注释除外)。
同一个数据库中这些对象名都是不能重复
C CHECK_CONSTRAINT
D DEFAULT_CONSTRAINT
F FOREIGN_KEY_CONSTRAINT
IT INTERNAL_TABLE
P SQL_STORED_PROCEDURE
PK PRIMARY_KEY_CONSTRAINT
S SYSTEM_TABLE
SQ SERVICE_QUEUE
TR SQL_TRIGGER
U USER_TABLE
UQ UNIQUE_CONSTRAINT
V VIEW
1.表名使用单数名
例如:对存储客人信息的表(Customer)不使用Customers
2.避免无谓的表格后缀
1、 表是用来存储数据信息的,表是行的集合。那么如果表名已经能够很好地说明其包含的数据信息,就不需要再添加体现上面两点的后缀了。
2、 GuestInfo(存储客户信息)应写成Guest,FlightList(存储航班信息的表)应写成Flight
3.所有表示时间的字段,统一以 Date 来作为结尾(而不是有的使用Date,有的使用Time)
以大家都熟悉的论坛来说,需要记录会员最后一次登录的时间,这时候一般人都会把这个字段命名为LoginTime 或者 LoginDate。这时候,已经产生了一个歧义;如果仅看表的字段名称,不去看表的内容,很容易将LoginTime理解成登录的次数,因为,Time还有一个很常用的意思,就是次数
4.所有表示数目的字段,都应该以Count作为结尾
5.所有代表链接的字段,均为Url结尾
6.所有名称的字符范围为:A-Z, a-z, 0-9 和_(下划线)。不允许使用其他字符作为名称。
7.采用英文单词或英文短语(包括缩写)作为名称,不能使用无意义的字符或汉语拼音。
8.名称应该清晰明了,能够准确表达事物的含义,最好可读,遵循“见名知意”的原则。
数据库名称不需要简写,根据实际意义来命名。例如:ReportServer
数据库名:ReportServer
逻辑数据名:ReportServer;逻辑日志名:ReportServer_log
物理数据名:ReportServer.mdf;物理日志名:ReportServer_log.LDF
CREATE DATABASE [ReportServer] ON PRIMARY
( NAME = N‘ReportServer‘, FILENAME = N‘D:\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\useData\ReportServer.mdf‘ , SIZE = 3328KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N‘ReportServer_log‘, FILENAME = N‘D:\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\useData\ReportServer_log.LDF‘ , SIZE = 6400KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
注意:避免所有数据库的逻辑名称使用相同的名称。
注意字段名不能使用保留关键字:如action,avg等
1、不使用tab或tbl作为表前缀(本来就是一个表,为什么还要说明)
2、表名以代表表内的内容的一个和多个名词组成,以下划线分隔,每个名词的第一个字母大写,例如:User、UserLogin,UserGroupRelation等
3、使用表的内容分类作为表名的前缀:如,与用户信息相关的表使用前缀User,与内容相关的信息使用前缀Content。
4、表的前缀以后,是表的具体内容的描述。如:用户登录信息的表名为:UserLogin,用户在论坛中的信息的表名为:UserBBSInfo
5、一些作为多对多连接的表,可以使用两个表的前缀作为表名:
如:用户登录表UserLogin,用户分组表GroupInfo,这两个表建立多对多关系的表名为:UserGroupRelation
存储过程名=[SP_]+[表名]+[操作名字]
[操作名字]=[insert|delete|update|calculate|confirm]
例如:SP_community_update
只允许应用程序通过存储过程访问数据库,而不允许直接在代码中写SQL语句访问数据库。
在数据库开发项目中,大量使用存储过程有很多的好处,首先看微软提供信息:
|
使用 SQL Server 中的存储过程而不使用存储在客户计算机本地的 Transact-SQL 程序的优势有: 允许模块化程序设计: 只需创建过程一次并将其存储在数据库中,以后即可在程序中调用该过程任意次。存储过程可由在数据库编程方面有专长的人员创建,并可独立于程序源代码而单独修改。 允许更快执行: 如果某操作需要大量 Transact-SQL 代码或需重复执行,存储过程将比 Transact-SQL 批代码的执行要快。将在创建存储过程时对其进行分析和优化,并可在首次执行该过程后使用该过程的内存中版本。每次运行 Transact-SQL 语句时,都要从客户端重复发送,并且在 SQL Server 每次执行这些语句时,都要对其进行编译和优化。 减少网络流量: 一个需要数百行 Transact-SQL 代码的操作由一条执行过程代码的单独语句就可实现,而不需要在网络中发送数百行代码。 可作为安全机制使用: 即使对于没有直接执行存储过程中语句的权限的用户,也可授予他们执行该存储过程的权限。
|
除此以外,使用存储过程的好处还有:
1、 在逻辑上,存储过程将应用程序层和数据库物理结构分离开来。存储过程形成了一个应用程序和数据库之间的接口。这样的接口抽象了复杂的数据库结构,符合极限编程中“基于接口编程”的思想。
2、 将主要的业务逻辑封装在存储过程中,能够避免在应用程序层写大量的代码(在应用程序中通过字符串插入太长的SQL语句影响效率,而且维护困难)。有助于提高开发效率,并且直接在查询分析器中调试存储过程,能够更早的发现系统中的逻辑问题,从而提高代码的质量。
3、 在网站一类的应用系统中,SQL注入式漏洞一直是难以完全杜绝的漏洞。如果只通过存储过程来访问数据库,能够大大减少这类安全性问题。(因此,就算是简单的只有一句的SQL语句,也应该写成存储过程。)
4、 由于采用存储过程,应用程序的层面可以不关心具体的数据库结构,而只关心存储过程的接口调用。因此,在以下一些情况,存储过程的优势非常明显:
·需求变更,表的结构必须要改变。使用存储过程,只要参数不变,我们就只需要修改相应的存储过程,而不需要修改应用程序的代码。这样的设计将减小需求变更对项目的影响。
·为提高效率,使部分字段冗余:一些经常性访问的字段,我们可以在相关的表中进行冗余存储。这样既提高了效率,又通过存储过程屏蔽了冗余细节。
·为提高效率,使用冗余表(拆分表):一些大的表,为了提高查询效率,可能需要将记录分别保存到多个表中去。使用存储过程,有存储过程来决定从哪些拆分的表中获取或插入数据。这样提高了效率,又不必在应用程序层面关心具体的拆分规则。
5、 使用存储过程,便于在项目后期或者运行中集中优化系统性能。在项目开发过程中,由于各种原因,往往无法编写高效的代码,这个问题常常在项目后期或者在运行期体现出来。通过存储过程来封装对数据库的访问,可以在项目集成以后,通过试运行观察系统的运行效率,从而很容易找出系统的瓶颈,并能够通过优化存储过程的代码来提高系统的运行效率。这样的优化,比在运用程序中优化更有效,更容易。
同时,过多的使用存储过程,也存在以下一些疑虑:
问题一:存储过程编译后,将作为数据库的全局对象保存,太多的存储过程将占用大量的数据库服务器的内存。
问题二:在存储过程中实现大量的逻辑,将使大量的运算在数据库服务器上完成,而不是在应用服务器上完成。当访问量很大的时候,会大大消耗数据库服务器的CPU占用率。
在此还存在这个一个案例:有一个访问量巨大的网站,有多台WEB服务器构成一个负载均衡的服务器群集,但是只有一台中心的数据库服务器。当访问量持续增加的时候,接入更多的WEB服务器来满足高并发量的访问;但是数据库服务器却没办法一直增加。因此,就需要尽量在WEB服务器上完成业务逻辑,尽量避免消耗数据库服务器的资源。
对于这两个担心,我的想法是:
问题一的解决:存储过程是经过编译后的SQL语句,在内存中是二进制的代码,并不会消耗太多内存。并且,存储过程比起直接使用SQL语句来说,效率大大提高。换个角度来说,这是一个“以空间换时间”的方案,多消耗一点内存来换取效率的提高,是值得的。
问题二的解决:首先,在实现业务逻辑的问题上,在存储过程中实现比在应用程序中实现更容易;其次,从开发效率上,存储过程的开发比应用程序更简单(就完成相同逻辑而言)。在高访问量的系统中,应用服务器和数据库服务器的资源分配的问题,应该从成本的角度来开率:软件开发中的成本,人工支出的费用远远高于硬件支出的成本。我们可以很容易花钱购买更好的服务器,但是很难花钱让开发人员使程序有大幅度的提高。
使用存储过程来封装业务逻辑,首先节省的是大量的开发时间和调试时间,并能够大大提高代码的质量。因此,从成本来说,应该使用存储过程。
对于大访问量的情况,最简单的办法是投入更多的硬件成本:更快的硬盘,更大的内存和更多的CPU,还有更好的网卡…………等等。
其次,在应用程序的层面,可以大量的使用静态文件缓存的办法来减轻数据库的压力。如:不经常变化的信息,可以从数据库服务器中读取,保存为应用服务器上的XML静态文件等。
实在不行的话,应该在系统设计之初,考虑可能的访问量,将系统设计成分布式的。这样就能从根本上解决大访问量的问题。
1、存储过程的前缀和表名的前缀类似:把一系列表看成一个对象,字段为对象的属性,存储过程则为访问对象的方法。如:添加用户的存储过程取名为:User_AddUser
2、存储过程使用模块的前缀来命名。如,用户管理的存储过程使用前缀user_。
3、存储过程的前缀之后,是动词+名词形式的存储过程名(也可以是动词短语)。
1、参数名采用匈牙利命名法,使用类型的前缀
2、每个存储过程都有:@errno int和@errmsg varchar(255)两个输出参数。应用程序中可以根据这两个参数得到存储过程执行的情况。(这两个参数使用默认值,可以忽略)
errno为整型的错误信息代码,执行成功返回0。Errno的值的具体含义通过errmsg参数说明,或者通过代码中的注释或文档。
Errmsg为错误信息的字符串描述,这个参数主要用于调试期作为说明,避免在应用程序中使用该值。同时,要注意英文版系统和中文版系统中,信息的语言选择对程序的影响。
1、存储过程的输出记录集:为程序的结构清晰,存储过程最好只返回一个记录集。但在某些为了提高性能的场合,还是可以输出多个记录集
2、记录集中,每个输出的字段最后都指定字段的别名,以面真实的字段名信息流失到客户端,从而加大黑客找到系统漏洞的可能。
1、 所有SQL关键字大写
2、 使用良好的变量命名规范
3、 保持良好的结构,包括空行、缩进和空格等。
4、 块状的语句,一定要写上BEGIN…END
5、 在每个存储过程的开头加上详细的注释:包括存储过程名称、参数说明、功能说明、返回数据集说明、以及作者和版权声明。
6、 每个存储过程内的代码前后必须加上SET NOCOUNT ON 和SET NOCOUNT OFF。
7、 存储过程格式的示例如下:
CREATE PROCEDURE SP_User_update
(
@Options VarChar(100),
@strUserName varchar(20),
@strPwd varchar(50),
@errno int = 0 OUTPUT,
@errmsg varchar(255)=NULL OUTPUT
)
AS
BEGIN
IF @Options=‘UP1‘
BEGIN
SET NOCOUNT ON
/*以下是存储过程的代码*/
SET NOCOUNT OFF
END
IF @Options=‘UP2‘
BEGIN
SET NOCOUNT ON
/*以下是存储过程的代码*/
SET NOCOUNT OFF
END
END
一个数据库中的视图名不能重复
视图名=VI(前缀)+[表名]..[表名]+[描述]
一个数据库中的主键名不能重复
主键名=PK_(前缀)+[表名]
例如:pk_Community
一个数据库中的外键名不能重复
外键名=FK_(前缀)+[主表名]+[从表名]+[字段名]
考虑这样一个关系,表Hotel,字段Id, Name, CityId。表City,字段Id,Name。因为一个城市可能有好多家酒店,所以是一个一对多的关系,City是主表(1方),Hotel是从表(多方)。在Hotel表中,CityId是做为外键使用。
在实现外键的时候我们可以这样写:
ALTER TABLE HotelInfo
ADD CONSTRAINT FK_Hotel_City_Cityid FOREIGN KEY (CityID) REFERENCES City(ID)
触发器名=TR_(前缀)+[表名]+[ _I、_U、_D]+[字段\描述]
例如:TR _Communtiy_u_name(对表community的字段name进行更新)
使用格式如:DF_[表名]_[列名]
例如:DF _Community_Age
格式:CK_[表名]_[列名]
例如:CK_Community_Number
格式:uq_[表名]_[列名]
例如:uq_Community_Name
1、字段不使用任何前缀(表名代表了一个名称空间,字段前面再加前缀显得罗嗦)
2、字典名也避免采用过于普遍过于简单的名称:例如,用户表中,用户名的字段为UserName比Name更好。
3、布尔型的字段,以一些助动词开头,更加直接生动:如,用户是否有留言HasMessage,用户是否通过检查IsChecked等。
4、字段名为英文短语、形容词+名词或助动词+动词时态的形式表示,大小写混合,遵循“见名知意”的原则。
1、不允许写SELECT * FROM ……,必须指明需要读取的具体字段。
2、不允许在应用程序代码中直接写SQL语句访问数据库。
3、避免在一行内写太长的SQL语句,在SQL关键字的地方将SQL语句分成多行会更加清晰。
如:SELECT UserID,UserName,UserPwd FROM User_Login WHERE AreaID=20
修改成:
SELECT UserID,UserName,UserPwd
FROM User_Login
WHERE AreaID=20
更加直观
4、在一些块形式的SQL语句中,就算只有一行代码,也要加上BEGIN…END块。
如:IF EXISTS(…)
SET @nVar = 100
应该写成:
IF EXISTS(…)
BEGIN
SET @nVar = 100
END
5、SQL批处理语句的空行和缩进与一般的结构化程序语言一致,应该保持良好的代码格式。
6、所有的SQL关键字大写
1、 若无必要,不要使用游标
2、 包含游标的存储过程,必须对性能进行认真测试。
对于数据库的维护建索引是很平常的事情,但是如果没有一个规范化的命名,我们对于一个表的诸多索引可能需要花上一段时间的了解。
当你执行SELECT NAME FROM SYS.COLUMNS 查询索引时,你根据NAME名很快就知道索引来自那张表,是否是非聚集索引,而不用根据OBJECTID列去跟对象表关联。
函数命名分两类:1.针对对象的函数,2.用作辅助功能操作的函数(不针对具体的数据库对象)
标签:style blog http os 使用 io strong ar for
原文地址:http://www.cnblogs.com/For-her/p/3944815.html