标签:png appname 技术 machine 机器学习 height 元素 pool label
保序回归即给定了一个无序的数字序列,通过修改其中元素的值,得到一个非递减的数字序列,要求是使得误差(预测值和实际值差的平方)最小。比如在动物身上实验某种药物,使用了不同的剂量,按理说剂量越大,有效的比例就应该越高,但是如果发现了剂量大反而有效率降低了,这个时候就只有把无序的两个元素合并了,重新计算有效率,直到计算出来的有效率不大于比下一个元素的有效率。
MLlib使用的是PAVA(Pool Adjacent Violators Algorithm)算法,并且是分布式的PAVA算法。首先在每个分区的样本集序列运行PAVA算法,保证局部有序,然后再对整个样本集运行PAVA算法,保证全局有序。
代码:
import org.apache.log4j.{Level, Logger} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.regression.{IsotonicRegression, IsotonicRegressionModel, LabeledPoint} object IsotonicRegression { def main(args: Array[String]) { // 设置运行环境 val conf = new SparkConf().setAppName("Istonic Regression Test") .setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\MachineLearning\\MachineLearning.jar")) val sc = new SparkContext(conf) Logger.getRootLogger.setLevel(Level.WARN) // 读取样本数据并解析 val dataRDD = sc.textFile("hdfs://master:9000/ml/data/sample_isotonic_regression_data.txt") val parsedDataRDD = dataRDD.map { line => val parts = line.split(‘,‘).map(_.toDouble) (parts(0), parts(1), 1.0) } // 样本数据划分,训练样本占0.7,测试样本占0.3 val dataParts = parsedDataRDD.randomSplit(Array(0.7, 0.3), seed = 25L) val trainRDD = dataParts(0) val testRDD = dataParts(1) // 建立保序回归模型并训练 val model = new IsotonicRegression().setIsotonic(true).run(trainRDD) // 计算误差 val prediction = testRDD.map { line => val predicted = model.predict(line._2) (predicted, line._2, line._1) } val showPrediction = prediction.collect println println("Prediction" + "\t" + "Feature") for (i <- 0 to showPrediction.length - 1) { println(showPrediction(i)._1 + "\t" + showPrediction(i)._2) } val MSE = prediction.map { case (p, _, l1) => math.pow((p - l1), 2) }.mean() println("MSE = " + MSE) } }
运行结果:
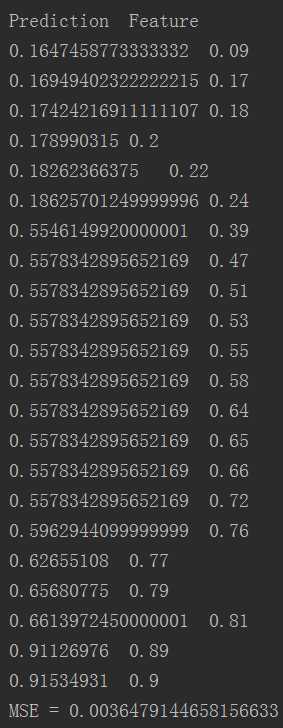
标签:png appname 技术 machine 机器学习 height 元素 pool label
原文地址:http://www.cnblogs.com/mstk/p/7019449.html