标签:idf ldl eem jit sci nmf dbv sea order
这篇文章即是Felix Endres等人12年完成的RGB-D SLAM V2,是最早的为kinect风格传感器设计的SLAM系统之一
在Github上可找到开源代码,工程配置与运行参考http://www.cnblogs.com/voyagee/p/6898278.html
系统流程:
系统分为前后端。前端就是视觉里程记。从每一帧的RGB图像提取特征,计算描述符,RANSAC+ICP计算两帧之间的motion estimation,
并提出了一个EMM(Environment Measurement Model)模型来判断estimate motion是否可接受。后端回环检测,基于g2o优化库的位姿图(pose graph)优化,
得到优化后的轨迹,用于建立地 图。建图采用八叉树地图octomap的方式。
特征提取
在源码中可选择 SIFT \ SURF \ORB 特征,其中SIFT要在GPU上运行,ORB和SURF都在CPU上用Opencv实现
不同特征比较:
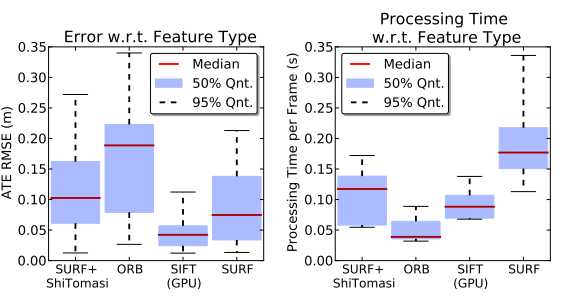
( 其中,ATE为Absolute Trajectory Error,轨迹的误差,就是系统估计的轨迹和真实轨迹(GroundTruth)之间的欧式距离,RMSE就是均方根)
可以看出,有GPU时SIFT综合表现最好。 综合实时性、硬件成本和准确率来看,ORB较好。
运动估计
三对特征快速计算RANSAC的初始值,在每一轮迭代中,最小二乘correspondences之间的马氏距离 。
马氏距离与欧式距离的差别:http://www.cnblogs.com/likai198981/p/3167928.html,简单说就是计算距离时考虑到了各项异性,多乘了一个协方差矩阵
EMM:Environment Measurement Model
一个传统的判断motion estimate是否可接受的方法就是看inlier的比例,小于设定阈值就reject motion estimate。
然而,motion blur(运动模糊),缺少纹理信息的环境都很容易出现inlier较少的情况。
并且有一些点,在一帧中可以看到,另一帧可能就被其他点挡住了。 作者提出使用这个EMM来更鲁棒的判断是否reject estimate
先看一个假设:实施transformation之后,空间上对应的深度测量值应该来自于同一个表面位置之下:
after applying transformation estimate,spatially corresponding depth measurement stem from the same underlying surface location.
论文中作者证明了观测yi和yj(不同与下图的yi,yj)之间的差满足高斯分布,方差为表示噪音的协方差矩阵(计算方法由论文 Accuracy and Resolution of Kinect Depth Data给出)
这样,就可以用概率学里的p值检验来判断是否reject estimate,然而,发现p值检验 有点神经衰弱 ,对于微小的误差太过敏感,
因此使用另一种方法
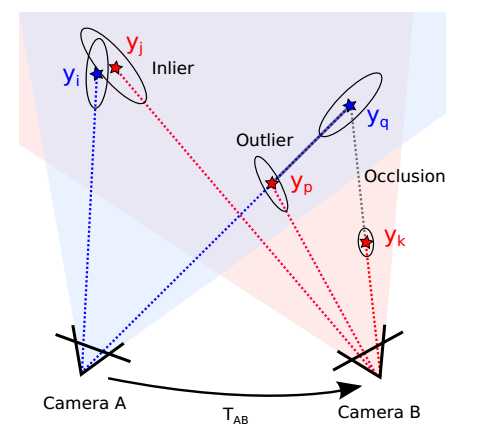
将相机A观测到的点投影到相机B,在observed points中找出inlier,outlier,occluded:
上图中yi和yj应该是同一个点,算作inlier。yk不再A的视场内,所以被忽视,不看作“observed points”。
投影之后的yq在相机B 的市场中被yk挡住,看不到,因此算作occluded。
至于yp,落在了yq和相机A光心的连线上,算作outlier(注意,yp与yk不同,yp在相机A的视场内,但是相机A在这里观测到的是yq的深度)
因此,在上图中,inlier有俩,outlier一个,occluded一个
而在代码中(misc.cpp 913行之后有两个函数,其中一个是用于p值检验方法的),作者是这么计算inlier,outlier,occluded,并判断是否reject的

observedPoints=inliers + outliers + occluded
I=inlier数量,O=outlier数量,C=occluded数量,如果I/(I+O+C)<25%,直接reject
否则,对I/(I+O)设一个阈值,小于阈值就reject
回环检测
现在的回环检测大多数是基于Bag-of-Words,深度学习兴起后也有用deep learning 的,或者用语义信息
此文回环是基于 最小生成树 ,随机森林的随机回环
使用描述符之间的距离(直接相减),生成一棵深度图像(limited depth)的最小生成树,去掉n个时间上最近的(避免重复)
再随机从树上选k帧(偏向于更早的帧)来找闭环
图优化
只优化位姿图,不优化三维点。
使用g2o图优化库。g2o的使用http://www.cnblogs.com/gaoxiang12/p/3776107.html
没有被EMM拒绝的motion,将两帧相机位姿作为优化顶点,motion作为约束,加入优化边
检测到的回环,也加入优化顶点和边
g2o优化边的误差函数:
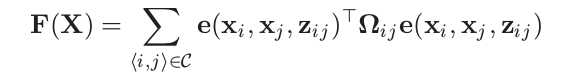
这里的xi,xj为优化变量(顶点位姿的estimate),Zij是约束,也就是xi和xj之间的变换。e()是how well xi and xj satisfy the constraint ,
中间的Ω是约束(优化边)的信息矩阵(协方差矩阵的逆), 表示对边的精度的估计。
看到这里,依然明白这个误差究竟咋算的~
查看g2o::SE3edge.cpp, 这个e其实是这么算的:

_inverseMeasurement * from->estimate().inverse() * to->estimate()
解释一下这个误差函数:
我们认为 帧2( from)的位姿态 Tj 是帧1(to)的位姿 Ti 经过 Tij 得到的 ,也就是
Ti * Tij = Tj
也就是
Tij = Ti -1 * Tj
即一个位姿的逆乘另一个位姿可以表示两个位姿之间的变化,那么,我们想表达边的measurement与Tij之间的差距,也可以这么玩儿
delta : Δ = measurement-1 * Ti-1 * Tj ,
这就得到g2o代码里的式子了, 后面的toVectorMQT是啥我也不清楚。。应该就是矩阵转化为向量
注意,Ti其实完整写法是Twi, w代表世界坐标系
这里看不懂的可以参考高翔大大《视觉SLAM十四讲》11.1.2
这个样子的回环检测,难免会出现错误的回环,这种回环约束加入到图优化中去,势必会把地图拉的扭曲
所以,在图优化第一次收敛之后,作者就把错误回环对应的优化边 从图中删除。
怎么判断回环是错误的呢? ----- 给上面说的误差函数设一个阈值(又又又又是阈值。。) ,误差大于这个阈值的就是错误的
octoMap:
http://www.cnblogs.com/gaoxiang12/p/5041142.html
把一个立方体平均分成八个小立方体,小立方体又可以再分,子子孙孙无穷尽也
每个小立方体对应八叉树的一个节点,因此成为八叉树地图
每个小立方体存储 被占据的概率的logist回归,被观测到占据次数越多,概率越大,而如果没有一次观测到被占据,则不用展开该节点


OctoMap的优点: 利于导航 ; 易于更新 ;存储方式比较省空间
欢迎交流,欢迎补充,欢迎纠错
3D Mapping with an RGB-D Camera(RGBD SLAM V2 )论文笔记
标签:idf ldl eem jit sci nmf dbv sea order
原文地址:http://www.cnblogs.com/voyagee/p/7027076.html