标签:src 过滤 筛选 配置 bin 外键 动态 定位 ip地址
python 操作MYSQL数据库主要有两种方式:
使用原生模块:pymysql
ORM框架:SQLAchemy
一、pymysql
1.1下载安装模块
第一种:cmd下:执行命令下载安装:pip3 install pymysql 第二种:IDE下pycharm python环境路径下添加模块
1.2使用操作
#导入模块 import pymysql #建立连接通道,建立连接填入(连接数据库的IP地址,端口号,用户名,密码,要操作的数据库,字符编码) conn = pymysql.connect( host="", port="", user=‘‘, password=‘‘, database="" charset="", ) # 创建游标,操作设置为字典类型,返回结果为字典格式!不写默认是元组格式! cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) #操作数据库的sql语句 sql="" # 向数据库发送数据,在方法内部进行拼接!!! #向数据库发送操作单条操作指令 # 格式化输入的值可以单个按顺序传入 或是写成列表 (注意 顺序和位置) r = cursor.execute(sql,v1,v2……) r = cursor.execute(sql,args) #r 代表接收返回受影响的行数(数字)及执行这一条sql语句,数据库中有多少行受到了影响。 #sql 指上边写的sql语句 #args 指要给sql语句中传的参数 sql 语句可以不传值 及为空 [] sql 语句可以传一个值 及 [v1,] sql 语句可以传多值 及 [v1,v2,v3……] #向数据库发送操作多条数据指令 args=[(v1,s1),(v2,s2),(v3,s3)] r = cursor.executemany(sql,[(‘egon‘,‘sb‘),(‘laoyao‘,‘BS‘)]) #数据库有四种操作:增删改查! # 执行查操作的时候就得接收从数据库返回的数据! #执行增删改操作的时候,就需要像数据库提交数据! #查操作:(接收的数据格式由创建的游标样式决定!) #接收数据有三种方式: res = cursor.fetchone() #接收返回的第一行数据 ret = cursor.fetchmany(n) #接收返回的n行数据 req = cursor.fetchall() #接收返回的说有数据 #注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如: cursor.scroll(1,mode=‘relative‘) # 相对当前位置移动 cursor.scroll(2,mode=‘absolute‘) # 相对绝对位置移动 #增删改操作: #写完发送操作语句之后,就需要把更改的数据提交,不然数据库无法完成新建或是修改操作 conn.commit() #提交 #注:此处有个获取新建数据自增ID的操作(只能拿到最后那一行的id数) #执行增加语句,并提交之后,可以获取到 new_id=cursor.lastrowid print(new_id) #操作完成之后,就需要关闭连接 cursor.close() #关闭游标 conn.close() #关闭连接
操作总结:
1、重中之重,一定要注意sql注入的问题!!!

#格式化写入sql语句,就会造成sql注入的情况!!! import pymysql user = input("username:") pwd = input("password:") conn = pymysql.connect(host="localhost",user=‘root‘,password=‘‘,database="db666") cursor = conn.cursor() sql = "select * from userinfo where username=‘%s‘ and password=‘%s‘" %(user,pwd,) # select * from userinfo where username=‘uu‘ or 1=1 -- ‘ and password=‘%s‘ cursor.execute(sql) result = cursor.fetchone() cursor.close() conn.close() if result: print(‘登录成功‘) else: print(‘登录失败‘)
import pymysql user = input("username:") pwd = input("password:") conn = pymysql.connect(host="localhost",user=‘root‘,password=‘‘,database="db666") cursor = conn.cursor() sql = "select * from userinfo where username=%s and password=%s" # sql = "select * from userinfo where username=%(u)s and password=%(p)s" #传入数据类型举例 cursor.execute(sql,user,pwd) #直接传值 # cursor.execute(sql,[user,pwd]) #列表形式 # cursor.execute(sql,{‘u‘:user,‘p‘:pwd}) #字典格式 result = cursor.fetchone() cursor.close() conn.close() if result: print(‘登录成功‘) else: print(‘登录失败‘)
import pymysql # 增加,删,该 # conn = pymysql.connect(host="localhost",user=‘root‘,password=‘‘,database="db666") # cursor = conn.cursor() # sql = "insert into userinfo(username,password) values(‘root‘,‘123123‘)" # 受影响的行数 # r = cursor.execute(sql) # # ****** # conn.commit() # cursor.close() # conn.close() # conn = pymysql.connect(host="localhost",user=‘root‘,password=‘‘,database="db666") # cursor = conn.cursor() # # sql = "insert into userinfo(username,password) values(%s,%s)" # # cursor.execute(sql,(user,pwd,)) #插入多条信息 # sql = "insert into userinfo(username,password) values(%s,%s)" # # 受影响的行数 # r = cursor.executemany(sql,[(‘egon‘,‘sa‘),(‘laoyao‘,‘BS‘)]) # # ****** # conn.commit() # cursor.close() # conn.close() # 查 # conn = pymysql.connect(host="localhost",user=‘root‘,password=‘‘,database="db666") # cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # sql = "select * from userinfo" # cursor.execute(sql) # cursor.scroll(1,mode=‘relative‘) # 相对当前位置移动 # cursor.scroll(2,mode=‘absolute‘) # 相对绝对位置移动 # result = cursor.fetchone() # print(result) # result = cursor.fetchone() # print(result) # result = cursor.fetchone() # print(result) # result = cursor.fetchall() # print(result) # result = cursor.fetchmany(4) # print(result) # cursor.close() # conn.close() # 新插入数据的自增ID: cursor.lastrowid # import pymysql # # conn = pymysql.connect(host="localhost",user=‘root‘,password=‘‘,database="db666") # cursor = conn.cursor() # sql = "insert into userinfo(username,password) values(‘asdfasdf‘,‘123123‘)" # cursor.execute(sql) # conn.commit() # print(cursor.lastrowid) # cursor.close() # conn.close()
二、SQLAchemy
2.1下载安装模块
pip3 install SQLAlchemy
IDE下pycharm python环境路径下添加模块
2.2原理
SQLAlchemy是python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
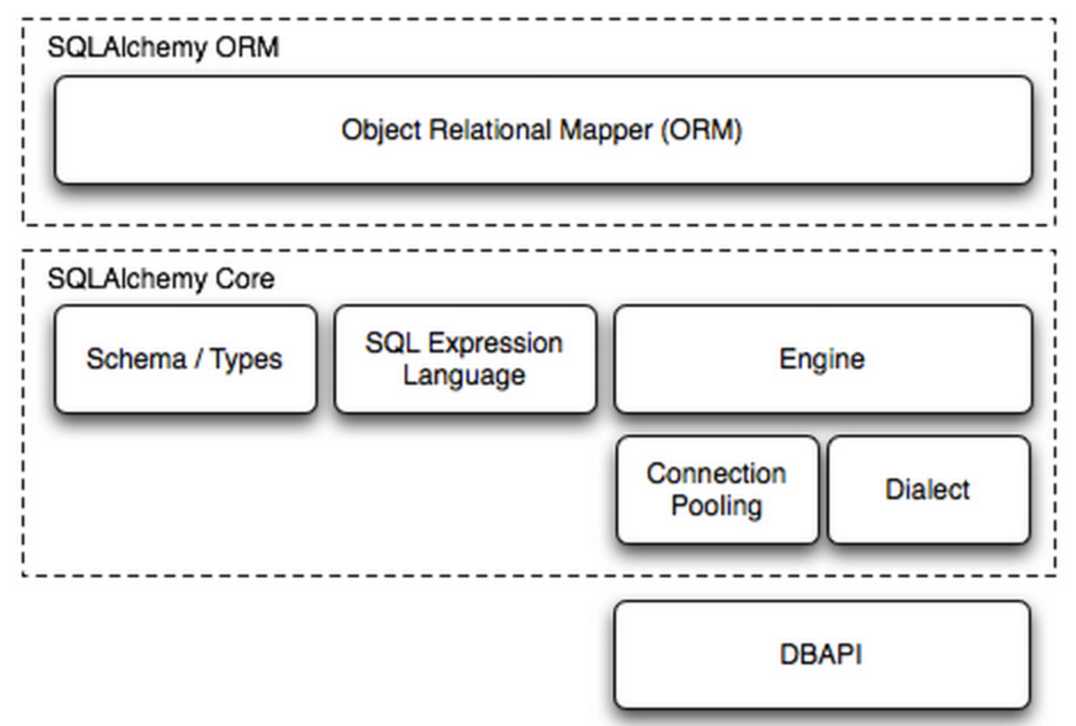
利用模块,按照对应规则,自动生成sql语句!
作用:提供简单的规则,自动转换成sql语句,最终还是执行sql语句,获取结果!
ORM操作流程:
创建一个类,类对应数据库的表,类能实例一个对象,这个对象对应表里的数据行
关系对象映射关系:
代码 数据库
类 ---> 表
对象 ---> 行
DB first :手动创建数据库和表,通过ORM框架 根据数据库,通过类生成一个一个表
code first :手动创建类和数据库,通过ORM框架 利用类创建表
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作。
远程连接数据库引擎类型: MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
SQLAchemy 只负责把类转换成sql语句,连接数据库还是需要插件配合着数据库模块连接的。
连接的数据库不同,转换成的sql语句也不同。
提前必须有连接不同数据库的模块或是软件,SQLAchemy再去配置
规则:导入模块,生成一个基类,然后再用创建类的方法去创建表,sql语句中的语法,全部转换成了方法
虽然没有使用__init__方法,但是在执行定义的时候,会copy到__init__中
找到当前所有继承base的类,然后创建对应的表
注意:利用SQLAchemy 创建表之前,需要先手动创建一个数据库!
2.3操作
导入模块:
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index,CHAR,VARCHAR
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
创建基类:
Base = declarative_base()
通过pymysql与mysql数据库建立远程连接 和设置最大连接数:
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/day63?charset=utf8", max_overflow=5)
创建单表:
class 类名(Base):
__tablename__="表名" #创建表名
列名=Column(数据类型,是否为空,主键,自增,索引,唯一索引)
__table_args__(
UniqueConstraint("列名1","列名2","联合唯一索引名"),
index("索引名","列名1","列名2"),
) #创建联合唯一索引
数据类型:Integer 整型;String 字符串类型(CHAR,VARCHAR也可以);
是否为空:nullable=True,
是否为主键:primary_key=True,
是否自增:autoincrement=True
索引:index=True
唯一索引:unique=True
例:
class Users(Base):
__tablename__ = ‘users‘
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(VARCHAR(32), nullable=True, index=True)
email = Column(VARCHAR(16), unique=True)
__table_args__ = (
UniqueConstraint(‘id‘, ‘name‘, name=‘uix_id_name‘),
Index(‘ix_n_ex‘,‘name‘, ‘email‘,),
)
创建有外键关系的多表:
1、先创建一个继承Base基类 存放数据的普通表
2、创建一个继承Base基类 与其有外键关系的表
3、语法:外键名("表名.列名")ForeignKey("usertype.id")
例:
class UserType(Base):
__tablename__ = "usertype"
id = Column(Integer,primary_key=True,autoincrement=True)
title = Column(String(32),nullable=True,index=True)
class Users(Base):
__tablename__ = "users"
id = Column(Integer,primary_key=True,autoincrement=True)
name = Column(String(32),nullable=True,index=True)
email = Column(String(16),unique=True)
u_type_id = Column(Integer,ForeignKey("usertype.id"))
#外键名 = Column(数据类型,ForeignKey("表名.列名"))
生成表或是删除表(可以把操作写成一个函数!):
#找到当前所有继承base的类,然后创建所有的表
def create_table():
Base.metadata.create_all(engine)
#找到当前所有继承base的类,然后删除所有的表
def del_table():
Base.metadata.drop_all(engine)
操作表:
万年不变的 数据行 的增删改查
#首先,先建立链接通道
Session = sessionmaker(bind=engine)
session = Session()
#其次,操作表 注意:操作内填如的内容,一定并必须是表达式!
#增
对哪张表更改,就用其对应的类进行实例化,生成的对象就代表着数据行
#增加单个 session.add()
obj = UserType(title = "黑金用户")
session.add(obj)
#增加多个 session.add_all()
objs =[
UserType(title = "会员用户"),
UserType(title = "超级用户"),
UserType(title = "铂金用户"),
UserType(title = "黑金用户"),
]
session.add_all(objs)
#查 session.query(类名).all() #直接获取整个类(表)下所有的对象(数据行)
#直接操作,获取的是像数据库发送执行的sql语句
res = session.query(UserType) #SQL语句
print(res)
#获取所有对应类(表)的对象(数据行) 列表类型
res_list = session.query(UserType).all()
print(res_list)
#查询操作,获取表中某列的值!是对接收到的整个列表进行循环遍历查找
#查询整个表内的信息 ------->等效于数据库中: select xxx from usertype
res_list = session.query(UserType).all()
for sss in res_list:
print(sss.id,sss.title)
#注意点:.filter()方法是过滤的意思,相当于sql语句中的where
#条件查找表内信息 -------->等效于数据库中: select xxx usertype where 条件
res_list = session.query(UserType).filter(UserType.id >2)
for sss in res_list:
print(sss.id,sss.title)
#注意点:执行删除和更改操作时,都是先把数据行找到(查操作),再进行删或改操作!
#删 找到对应的数据行,删除即可 .delete()
#先找后删,等效于------> delete from usertype where usertype.id > 4
session.query(UserType).filter(UserType.id > 4).delete()
#改 先查后改 注意传值的格式!
#这里有个参数 synchronize_session 没别的招,看源码解释!!!
#对表进行批量更改!
session.query(UserType).filter(UserType.id>0).update({"title":"黑金"})
#动态获取原表的数据(char类型),对表进行批量更改
session.query(UserType).filter(UserType.id>0).update({UserType.title:UserType.title+"SX"},synchronize_session=False)
#动态获取原表的数据(int类型),对表进行批量更改
session.query(UserType).filter(UserType.id>0).update({"title":UserType.id+1},synchronize_session="evaluate")
#查找其他操作:
# 分组,排序,连表,通配符,子查询,limit,union,where,原生SQL、
# 条件
#过滤,又叫条件判断
ret = session.query(Users).filter_by(name=‘alex‘).all()
#两个表达式同时存在,逗号分开,不写关系默认是 and
ret = session.query(Users).filter(Users.id > 1, Users.name == ‘eric‘).all()
#between and
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == ‘eric‘).all()
#in判断 语法:in_
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
# not in 判断 语法:表达式最前加 ~
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
#子查询
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name=‘eric‘))).all()
#逻辑判断: and_ or_ 操作
from sqlalchemy import and_, or_
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == ‘eric‘)).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == ‘eric‘)).all()
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == ‘eric‘, Users.id > 3),
Users.extra != ""
)).all()
# 通配符 .like()的方法调用
ret = session.query(Users).filter(Users.name.like(‘e%‘)).all()
ret = session.query(Users).filter(~Users.name.like(‘e%‘)).all()
# 限制
ret = session.query(Users)[1:2]
#分页 .limit(n) 取n个数据
res_list = session.query(UserType).limit(2).all()
for sss in res_list:
print(sss.id,sss.title)
# 排序 查表.order_by(列名.desc()/列名.asc()) [.desc() 由大到小;.asc() 由小到大]
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()
# 分组 聚合函数func.方法(列名) 和 .group_by(列名) 方法
from sqlalchemy.sql import func
ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() #直连
ret = session.query(Person).join(Favor).all()
ret = session.query(Person).join(Favor, isouter=True).all()
#子查询 三种样式
#查询的信息作为另一张表的条件
# 1.select * from b where id in (select id from tb2)
#最为一张新表进行二次筛选
# 2. select * from (select * from tb) as B
#查询语句.subquery() 查询结果作为一个子查询(新表)好在进行下一步的查询。不加.subquery()的话会报错,不再往下查询
# q1 = session.query(UserType).filter(UserType.id > 0).subquery()
# result = session.query(q1).all()
# print(result)
#作为一个列内的数据,在另一张表中显示 ****** .as_scalar()方法
# 3. select id ,(select * from users where users.user_type_id=usertype.id) from usertype;
# session.query(UserType,Users)
# result = session.query(UserType.id,session.query(Users).as_scalar())
# print(result) #查看对应的sql语句
# result = session.query(UserType.id,session.query(Users).filter(Users.user_type_id==UserType.id).as_scalar())
# print(result) #查看对应的sql语句
# 组合(上下连表) .union() 和 .union_all() 注意是:先把信息找到再操作!
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
- 便利的功能 relationship() 与生成表结构无关,仅用于查询方便 释放了连表操作的繁琐查找,直接通过方法定位!
使用规范:哪个类中有外键列,就在外键列下添加。
语法:自定义名=relationship("外键有联系的类名",backref="任意命名")
# 问题1. 获取用户信息以及与其关联的用户类型名称(FK,Relationship=>正向操作)
#初始方法:连表操作
user_list = session.query(Users,UserType).join(UserType,isouter=True)
print(user_list)
for row in user_list:
print(row[0].id,row[0].name,row[0].email,row[0].user_type_id,row[1].title)
user_list = session.query(Users.name,UserType.title).join(UserType,isouter=True).all()
for row in user_list:
print(row[0],row[1],row.name,row.title)
#(FK,Relationship=>正向操作) 先查用户信息表,通过命名的 自定义名 正向获取用户类型
user_list = session.query(Users)
for row in user_list:
print(row.name,row.id,row.user_type.title)
# 问题2. 获取用户类型 (FK,Relationship=>反向操作)
#连表操作:
type_list = session.query(UserType)
for row in type_list:
print(row.id,row.title,session.query(Users).filter(Users.user_type_id == row.id).all())
#反向操作:先查类型表,再通过backref 自定义的变量 反向查找用户信息
type_list = session.query(UserType)
for row in type_list:
print(row.id,row.title,row.xxoo)
PS:正向操作与反向操作,是相对于外键来相对判断的!
例如:A表与B表,A表中建立了与B表联系的外键,A表通过外键获取B表中的信息,叫正向操作;反之,叫反向操作!
最后,操作及语法写完后,都需要提交给数据库去执行,不再使用也需要断开连接!
session.commit() #提交
session.close() #关闭连接
#!/usr/bin/env python # _*_ coding:utf-8 _*_ from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine Base = declarative_base() engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/day63?charset=utf8",max_overflow=5) class UserType(Base): __tablename__ = "usertype" id = Column(Integer,primary_key=True,autoincrement=True) title = Column(String(32),nullable=True,index=True) class Users(Base): __tablename__ = "users" id = Column(Integer,primary_key=True,autoincrement=True) name = Column(String(32),nullable=True,index=True) email = Column(String(16),unique=True) u_type_id = Column(Integer,ForeignKey("usertype.id")) u_type = relationship("UserType",backref="sss") def create_table(): Base.metadata.create_all(engine) def del_table(): Base.metadata.drop_all(engine) #类 --> 表 #对象 --> 行 #建立链接通道 Session = sessionmaker(bind=engine) session = Session() #操作内填入的内容,必须是表达式 ########## 增加 ################### #增加单个 # obj = UserType(title = "黑金用户") # session.add(obj) #增加多个 # objs =[ # UserType(title = "会员用户"), # UserType(title = "超级用户"), # UserType(title = "铂金用户"), # UserType(title = "黑金用户"), # ] # session.add_all(objs) ############ 查询 ################ # res = session.query(UserType) #SQL语句 # print(res) # res_list = session.query(UserType).all() #获取所有对应类(表)的对象(数据行) 列表类型 # print(res_list) #select xxx from usertype # res_list = session.query(UserType).limit(2).all() # for sss in res_list: # print(sss.id,sss.title) # # #select xxx usertype where *** # res_list = session.query(UserType).filter(UserType.id >2) # for sss in res_list: # print(sss.id,sss.title) ############### 删除 ################### # delete from usertype where usertype.id > 4 # session.query(UserType).filter(UserType.id > 4).delete() ################ 更改 ######################## #这里有个参数 synchronize_session 没别的招,看源码解释!!! # session.query(UserType).filter(UserType.id>0).update({"title":"黑金"}) #对表进行批量更改 # session.query(UserType).filter(UserType.id>0).update({UserType.title:UserType.title+"SX"},synchronize_session=False) #动态获取原先的数据,对表进行批量更改 # session.query(UserType).filter(UserType.id>0).update({"title":UserType.id+1},synchronize_session="evaluate") #对表进行批量更改 ############# 查询其他操作 ################# # 分组,排序,连表,通配符,limit,union,where,原生SQL# #条件 and or # ret = session.query(Users).filter(Users.id > 1, Users.name == "sesc").all() # for row in ret: # print(row.email) # #正向操作 # res = session.query(Users) # for row in res: # print(row.id,row.name,row.u_type.title) # # #反向操作 # res = session.query(UserType) # for row in res: # for a in row.sss: # print(row.id,row.title,a.name) session.commit() session.close()
标签:src 过滤 筛选 配置 bin 外键 动态 定位 ip地址
原文地址:http://www.cnblogs.com/zh605929205/p/7001994.html
